 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Recent Teacher-student Learning Studies
Apr 10, 2023Knowledge distillation is a method of transferring the knowledge from a complex deep neural network (DNN) to a smaller and faster DNN, while preserving its accuracy. Recent variants of knowledge distillation include teaching assistant distillation, curriculum distillation, mask distillation, and decoupling distillation, which aim to improve the performance of knowledge distillation by introducing additional components or by changing the learning process. Teaching assistant distillation involves an intermediate model called the teaching assistant, while curriculum distillation follows a curriculum similar to human education. Mask distillation focuses on transferring the attention mechanism learned by the teacher, and decoupling distillation decouples the distillation loss from the task loss. Overall, these variants of knowledge distillation have shown promising results in improving the performance of knowledge distillation.
ChemiRise: a data-driven retrosynthesis engine
Aug 09, 2021
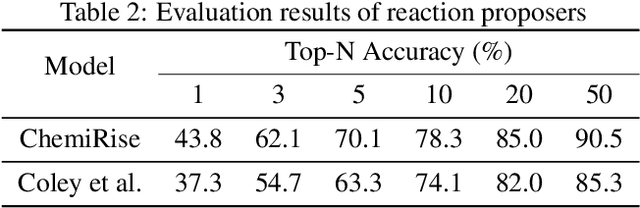

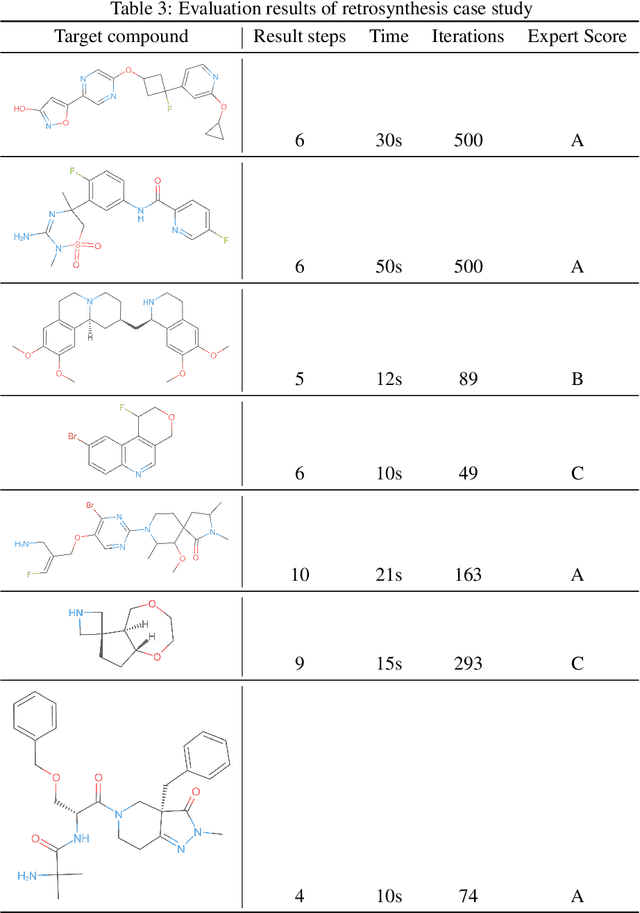
We have developed an end-to-end, retrosynthesis system, named ChemiRise, that can propose complete retrosynthesis routes for organic compounds rapidly and reliably. The system was trained on a processed patent database of over 3 million organic reactions. Experimental reactions were atom-mapped, clustered, and extracted into reaction templates. We then trained a graph convolutional neural network-based one-step reaction proposer using template embeddings and developed a guiding algorithm on the directed acyclic graph (DAG) of chemical compounds to find the best candidate to explore. The atom-mapping algorithm and the one-step reaction proposer were benchmarked against previous studies and showed better results. The final product was demonstrated by retrosynthesis routes reviewed and rated by human experts, showing satisfying functionality and a potential productivity boost in real-life use cases.