 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeLens: An Interactive Tool for Visualizing Code Representations
Jul 27, 2023Representing source code in a generic input format is crucial to automate software engineering tasks, e.g., applying machine learning algorithms to extract information. Visualizing code representations can further enable human experts to gain an intuitive insight into the code. Unfortunately, as of today, there is no universal tool that can simultaneously visualise different types of code representations. In this paper, we introduce a tool, CodeLens, which provides a visual interaction environment that supports various representation methods and helps developers understand and explore them. CodeLens is designed to support multiple programming languages, such as Java, Python, and JavaScript, and four types of code representations, including sequence of tokens, abstract syntax tree (AST), data flow graph (DFG), and control flow graph (CFG). By using CodeLens, developers can quickly visualize the specific code representation and also obtain the represented inputs for models of code. The Web-based interface of CodeLens is available at http://www.codelens.org. The demonstration video can be found at http://www.codelens.org/demo.
RNNS: Representation Nearest Neighbor Search Black-Box Attack on Code Models
May 20, 2023Pre-trained code models are mainly evaluated using the in-distribution test data. The robustness of models, i.e., the ability to handle hard unseen data, still lacks evaluation. In this paper, we propose a novel search-based black-box adversarial attack guided by model behaviours for pre-trained programming language models, named Representation Nearest Neighbor Search(RNNS), to evaluate the robustness of Pre-trained PL models. Unlike other black-box adversarial attacks, RNNS uses the model-change signal to guide the search in the space of the variable names collected from real-world projects. Specifically, RNNS contains two main steps, 1) indicate which variable (attack position location) we should attack based on model uncertainty, and 2) search which adversarial tokens we should use for variable renaming according to the model behaviour observations. We evaluate RNNS on 6 code tasks (e.g., clone detection), 3 programming languages (Java, Python, and C), and 3 pre-trained code models: CodeBERT, GraphCodeBERT, and CodeT5. The results demonstrate that RNNS outperforms the state-of-the-art black-box attacking methods (MHM and ALERT) in terms of attack success rate (ASR) and query times (QT). The perturbation of generated adversarial examples from RNNS is smaller than the baselines with respect to the number of replaced variables and the variable length change. Our experiments also show that RNNS is efficient in attacking the defended models and is useful for adversarial training.
Distribution-aware Fairness Test Generation
May 08, 2023



This work addresses how to validate group fairness in image recognition software. We propose a distribution-aware fairness testing approach (called DistroFair) that systematically exposes class-level fairness violations in image classifiers via a synergistic combination of out-of-distribution (OOD) testing and semantic-preserving image mutation. DistroFair automatically learns the distribution (e.g., number/orientation) of objects in a set of images. Then it systematically mutates objects in the images to become OOD using three semantic-preserving image mutations -- object deletion, object insertion and object rotation. We evaluate DistroFair using two well-known datasets (CityScapes and MS-COCO) and three major, commercial image recognition software (namely, Amazon Rekognition, Google Cloud Vision and Azure Computer Vision). Results show that about 21% of images generated by DistroFair reveal class-level fairness violations using either ground truth or metamorphic oracles. DistroFair is up to 2.3x more effective than two main baselines, i.e., (a) an approach which focuses on generating images only within the distribution (ID) and (b) fairness analysis using only the original image dataset. We further observed that DistroFair is efficient, it generates 460 images per hour, on average. Finally, we evaluate the semantic validity of our approach via a user study with 81 participants, using 30 real images and 30 corresponding mutated images generated by DistroFair. We found that images generated by DistroFair are 80% as realistic as real-world images.
Going Further: Flatness at the Rescue of Early Stopping for Adversarial Example Transferability
Apr 05, 2023



Transferability is the property of adversarial examples to be misclassified by other models than the surrogate model for which they were crafted. Previous research has shown that transferability is substantially increased when the training of the surrogate model has been early stopped. A common hypothesis to explain this is that the later training epochs are when models learn the non-robust features that adversarial attacks exploit. Hence, an early stopped model is more robust (hence, a better surrogate) than fully trained models. We demonstrate that the reasons why early stopping improves transferability lie in the side effects it has on the learning dynamics of the model. We first show that early stopping benefits transferability even on models learning from data with non-robust features. We then establish links between transferability and the exploration of the loss landscape in the parameter space, on which early stopping has an inherent effect. More precisely, we observe that transferability peaks when the learning rate decays, which is also the time at which the sharpness of the loss significantly drops. This leads us to propose RFN, a new approach for transferability that minimizes loss sharpness during training in order to maximize transferability. We show that by searching for large flat neighborhoods, RFN always improves over early stopping (by up to 47 points of transferability rate) and is competitive to (if not better than) strong state-of-the-art baselines.
Boosting Source Code Learning with Data Augmentation: An Empirical Study
Mar 13, 2023



The next era of program understanding is being propelled by the use of machine learning to solve software problems. Recent studies have shown surprising results of source code learning, which applies deep neural networks (DNNs) to various critical software tasks, e.g., bug detection and clone detection. This success can be greatly attributed to the utilization of massive high-quality training data, and in practice, data augmentation, which is a technique used to produce additional training data, has been widely adopted in various domains, such as computer vision. However, in source code learning, data augmentation has not been extensively studied, and existing practice is limited to simple syntax-preserved methods, such as code refactoring. Essentially, source code is often represented in two ways, namely, sequentially as text data and structurally as graph data, when it is used as training data in source code learning. Inspired by these analogy relations, we take an early step to investigate whether data augmentation methods that are originally used for text and graphs are effective in improving the training quality of source code learning. To that end, we first collect and categorize data augmentation methods in the literature. Second, we conduct a comprehensive empirical study on four critical tasks and 11 DNN architectures to explore the effectiveness of 12 data augmentation methods (including code refactoring and 11 other methods for text and graph data). Our results identify the data augmentation methods that can produce more accurate and robust models for source code learning, including those based on mixup (e.g., SenMixup for texts and Manifold-Mixup for graphs), and those that slightly break the syntax of source code (e.g., random swap and random deletion for texts).
GAT: Guided Adversarial Training with Pareto-optimal Auxiliary Tasks
Feb 06, 2023While leveraging additional training data is well established to improve adversarial robustness, it incurs the unavoidable cost of data collection and the heavy computation to train models. To mitigate the costs, we propose \textit{Guided Adversarial Training } (GAT), a novel adversarial training technique that exploits auxiliary tasks under a limited set of training data. Our approach extends single-task models into multi-task models during the min-max optimization of adversarial training, and drives the loss optimization with a regularization of the gradient curvature across multiple tasks. GAT leverages two types of auxiliary tasks: self-supervised tasks, where the labels are generated automatically, and domain-knowledge tasks, where human experts provide additional labels. Experimentally, under limited data, GAT increases the robust accuracy on CIFAR-10 up to four times (from 11% to 42% robust accuracy) and the robust AUC of CheXpert medical imaging dataset from 50\% to 83\%. On the full CIFAR-10 dataset, GAT outperforms eight state-of-the-art adversarial training strategies. Our large study across five datasets and six tasks demonstrates that task augmentation is an efficient alternative to data augmentation, and can be key to achieving both clean and robust performances.
On Evaluating Adversarial Robustness of Chest X-ray Classification: Pitfalls and Best Practices
Dec 15, 2022Vulnerability to adversarial attacks is a well-known weakness of Deep Neural Networks. While most of the studies focus on natural images with standardized benchmarks like ImageNet and CIFAR, little research has considered real world applications, in particular in the medical domain. Our research shows that, contrary to previous claims, robustness of chest x-ray classification is much harder to evaluate and leads to very different assessments based on the dataset, the architecture and robustness metric. We argue that previous studies did not take into account the peculiarity of medical diagnosis, like the co-occurrence of diseases, the disagreement of labellers (domain experts), the threat model of the attacks and the risk implications for each successful attack. In this paper, we discuss the methodological foundations, review the pitfalls and best practices, and suggest new methodological considerations for evaluating the robustness of chest xray classification models. Our evaluation on 3 datasets, 7 models, and 18 diseases is the largest evaluation of robustness of chest x-ray classification models.
Enhancing Mixup-Based Graph Learning for Language Processing via Hybrid Pooling
Oct 06, 2022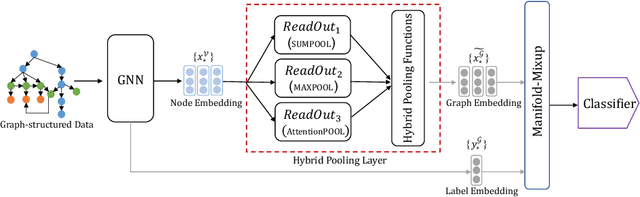
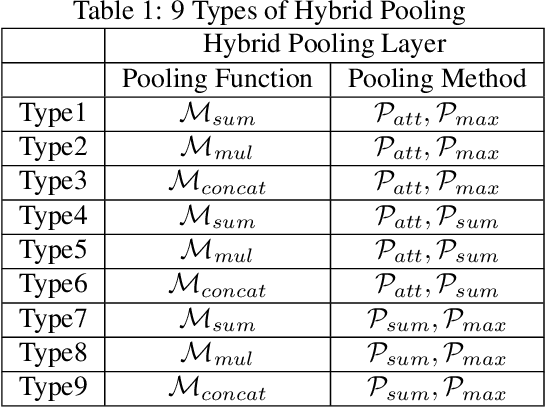

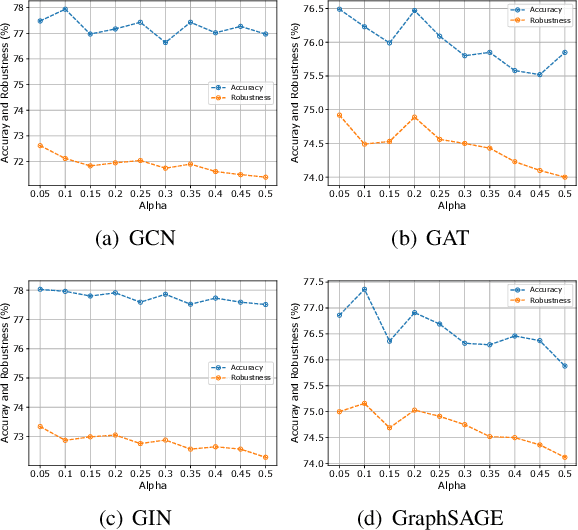
Graph neural networks (GNNs) have recently been popular in natural language and programming language processing, particularly in text and source code classification. Graph pooling which processes node representation into the entire graph representation, which can be used for multiple downstream tasks, e.g., graph classification, is a crucial component of GNNs. Recently, to enhance graph learning, Manifold Mixup, a data augmentation strategy that mixes the graph data vector after the pooling layer, has been introduced. However, since there are a series of graph pooling methods, how they affect the effectiveness of such a Mixup approach is unclear. In this paper, we take the first step to explore the influence of graph pooling methods on the effectiveness of the Mixup-based data augmentation approach. Specifically, 9 types of hybrid pooling methods are considered in the study, e.g., $\mathcal{M}_{sum}(\mathcal{P}_{att},\mathcal{P}_{max})$. The experimental results on both natural language datasets (Gossipcop, Politifact) and programming language datasets (Java250, Python800) demonstrate that hybrid pooling methods are more suitable for Mixup than the standard max pooling and the state-of-the-art graph multiset transformer (GMT) pooling, in terms of metric accuracy and robustness.
Enhancing Code Classification by Mixup-Based Data Augmentation
Oct 06, 2022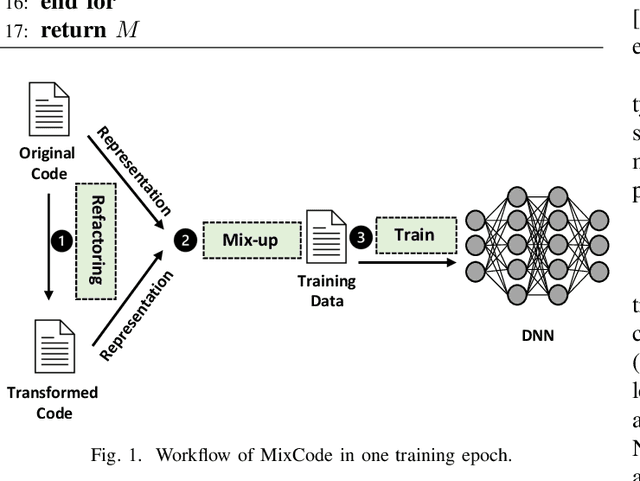
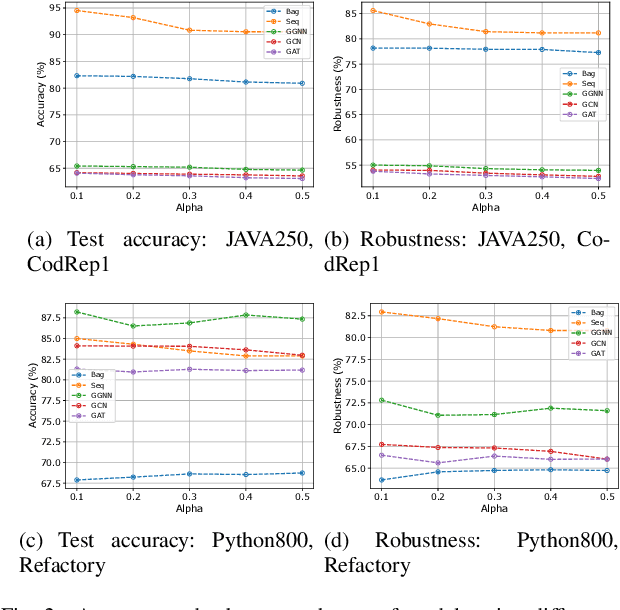
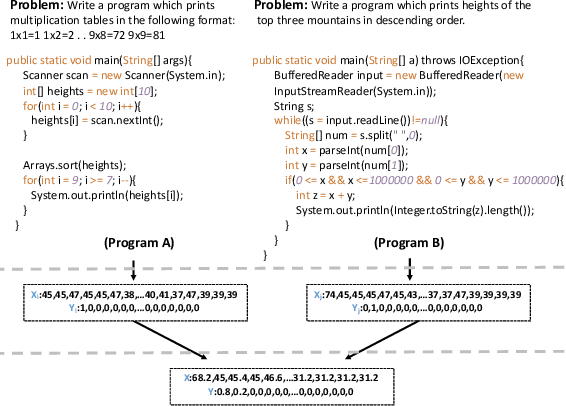
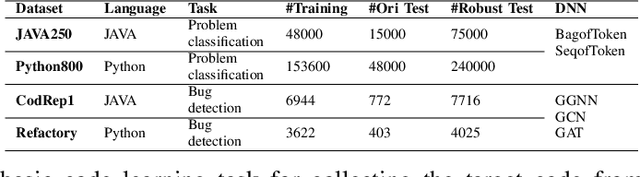
Recently, deep neural networks (DNNs) have been widely applied in programming language understanding. Generally, training a DNN model with competitive performance requires massive and high-quality labeled training data. However, collecting and labeling such data is time-consuming and labor-intensive. To tackle this issue, data augmentation has been a popular solution, which delicately increases the training data size, e.g., adversarial example generation. However, few works focus on employing it for programming language-related tasks. In this paper, we propose a Mixup-based data augmentation approach, MixCode, to enhance the source code classification task. First, we utilize multiple code refactoring methods to generate label-consistent code data. Second, the Mixup technique is employed to mix the original code and transformed code to form the new training data to train the model. We evaluate MixCode on two programming languages (JAVA and Python), two code tasks (problem classification and bug detection), four datasets (JAVA250, Python800, CodRep1, and Refactory), and 5 model architectures. Experimental results demonstrate that MixCode outperforms the standard data augmentation baseline by up to 6.24\% accuracy improvement and 26.06\% robustness improvement.
LGV: Boosting Adversarial Example Transferability from Large Geometric Vicinity
Jul 26, 2022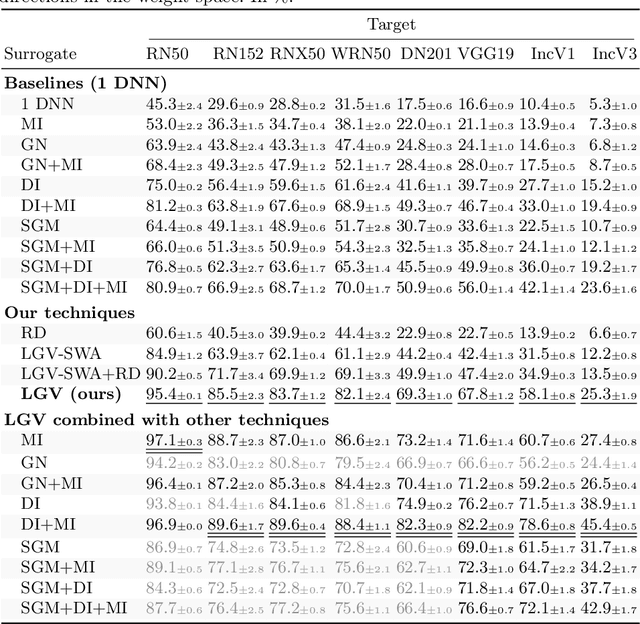
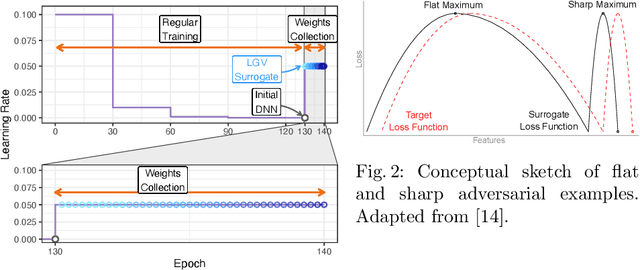
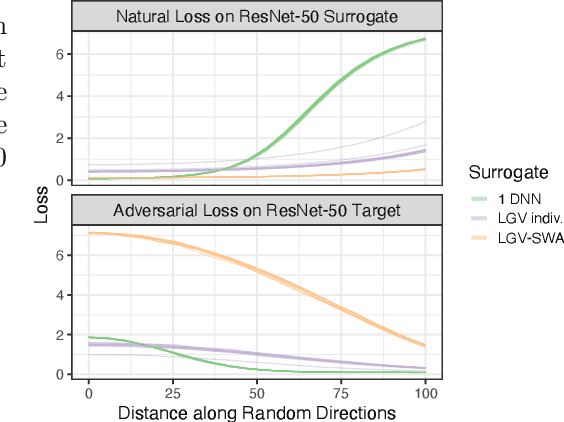

We propose transferability from Large Geometric Vicinity (LGV), a new technique to increase the transferability of black-box adversarial attacks. LGV starts from a pretrained surrogate model and collects multiple weight sets from a few additional training epochs with a constant and high learning rate. LGV exploits two geometric properties that we relate to transferability. First, models that belong to a wider weight optimum are better surrogates. Second, we identify a subspace able to generate an effective surrogate ensemble among this wider optimum. Through extensive experiments, we show that LGV alone outperforms all (combinations of) four established test-time transformations by 1.8 to 59.9 percentage points. Our findings shed new light on the importance of the geometry of the weight space to explain the transferability of adversarial examples.