 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaTeCon: A Pattern-Based Temporal Constraint Mining Method for Conflict Detection on Knowledge Graphs
Apr 23, 2023



Temporal facts, the facts for characterizing events that hold in specific time periods, are attracting rising attention in the knowledge graph (KG) research communities. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs and detecting potential temporal conflicts. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. We start from the common pattern of temporal facts and constraints and propose a pattern-based temporal constraint mining method, PaTeCon. PaTeCon uses automatically determined graph patterns and their relevant statistical information over the given KG instead of human experts to generate time constraints. Specifically, PaTeCon dynamically attaches class restriction to candidate constraints according to their measuring scores.We evaluate PaTeCon on two large-scale datasets based on Wikidata and Freebase respectively. The experimental results show that pattern-based automatic constraint mining is powerful in generating valuable temporal constraints.
DyRRen: A Dynamic Retriever-Reranker-Generator Model for Numerical Reasoning over Tabular and Textual Data
Nov 23, 2022



Numerical reasoning over hybrid data containing tables and long texts has recently received research attention from the AI community. To generate an executable reasoning program consisting of math and table operations to answer a question, state-of-the-art methods use a retriever-generator pipeline. However, their retrieval results are static, while different generation steps may rely on different sentences. To attend to the retrieved information that is relevant to each generation step, in this paper, we propose DyRRen, an extended retriever-reranker-generator framework where each generation step is enhanced by a dynamic reranking of retrieved sentences. It outperforms existing baselines on the FinQA dataset.
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases
Oct 24, 2022



Pre-trained language models (PLMs) have shown their effectiveness in multiple scenarios. However, KBQA remains challenging, especially regarding coverage and generalization settings. This is due to two main factors: i) understanding the semantics of both questions and relevant knowledge from the KB; ii) generating executable logical forms with both semantic and syntactic correctness. In this paper, we present a new KBQA model, TIARA, which addresses those issues by applying multi-grained retrieval to help the PLM focus on the most relevant KB contexts, viz., entities, exemplary logical forms, and schema items. Moreover, constrained decoding is used to control the output space and reduce generation errors. Experiments over important benchmarks demonstrate the effectiveness of our approach. TIARA outperforms previous SOTA, including those using PLMs or oracle entity annotations, by at least 4.1 and 1.1 F1 points on GrailQA and WebQuestionsSP, respectively.
Semantic Framework based Query Generation for Temporal Question Answering over Knowledge Graphs
Oct 10, 2022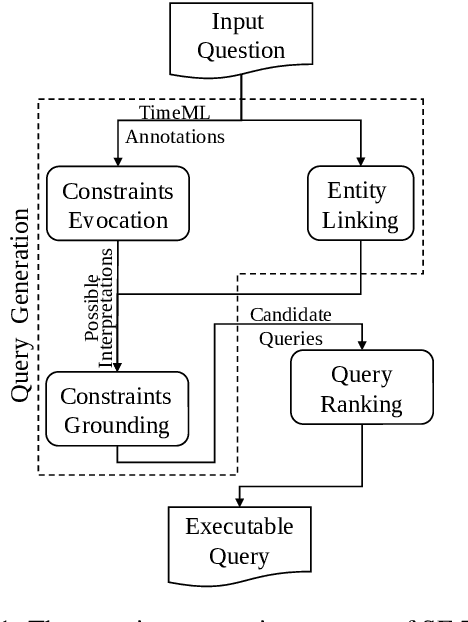
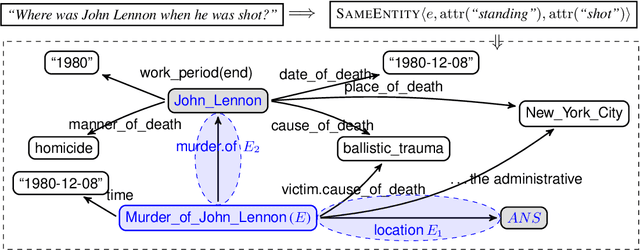

Answering factual questions with temporal intent over knowledge graphs (temporal KGQA) attracts rising attention in recent years. In the generation of temporal queries, existing KGQA methods ignore the fact that some intrinsic connections between events can make them temporally related, which may limit their capability. We systematically analyze the possible interpretation of temporal constraints and conclude the interpretation structures as the Semantic Framework of Temporal Constraints, SF-TCons. Based on the semantic framework, we propose a temporal question answering method, SF-TQA, which generates query graphs by exploring the relevant facts of mentioned entities, where the exploring process is restricted by SF-TCons. Our evaluations show that SF-TQA significantly outperforms existing methods on two benchmarks over different knowledge graphs.
AdaLoGN: Adaptive Logic Graph Network for Reasoning-Based Machine Reading Comprehension
Mar 16, 2022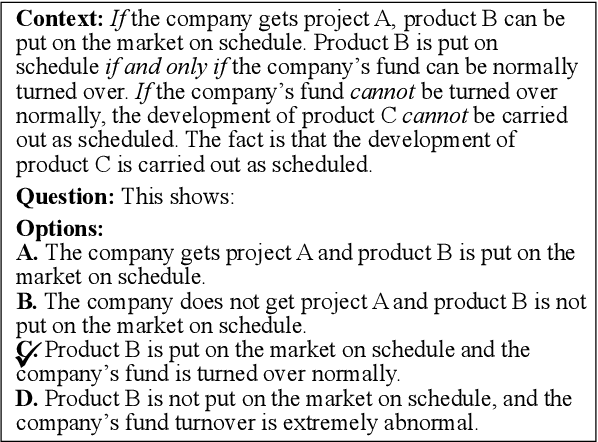

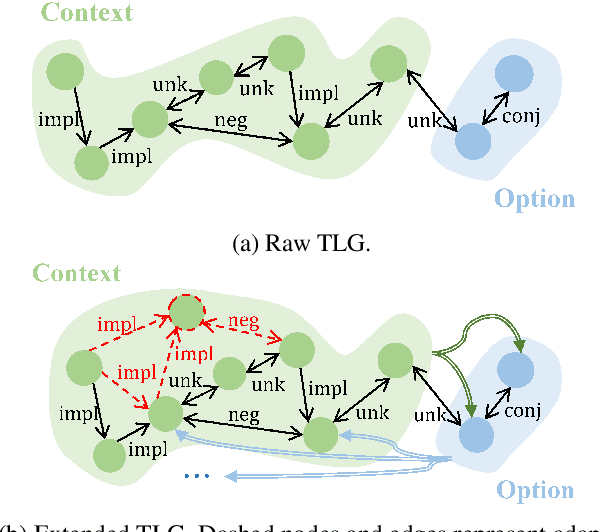
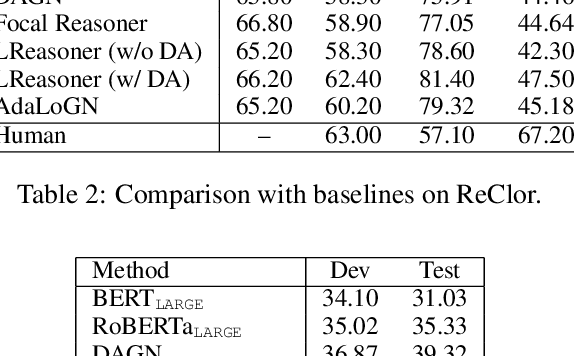
Recent machine reading comprehension datasets such as ReClor and LogiQA require performing logical reasoning over text. Conventional neural models are insufficient for logical reasoning, while symbolic reasoners cannot directly apply to text. To meet the challenge, we present a neural-symbolic approach which, to predict an answer, passes messages over a graph representing logical relations between text units. It incorporates an adaptive logic graph network (AdaLoGN) which adaptively infers logical relations to extend the graph and, essentially, realizes mutual and iterative reinforcement between neural and symbolic reasoning. We also implement a novel subgraph-to-node message passing mechanism to enhance context-option interaction for answering multiple-choice questions. Our approach shows promising results on ReClor and LogiQA.
When Retriever-Reader Meets Scenario-Based Multiple-Choice Questions
Sep 05, 2021

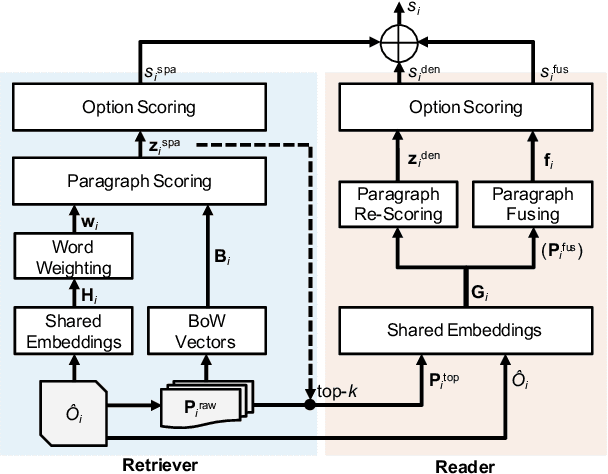
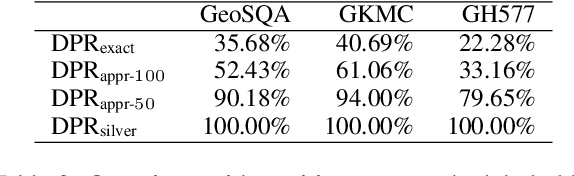
Scenario-based question answering (SQA) requires retrieving and reading paragraphs from a large corpus to answer a question which is contextualized by a long scenario description. Since a scenario contains both keyphrases for retrieval and much noise, retrieval for SQA is extremely difficult. Moreover, it can hardly be supervised due to the lack of relevance labels of paragraphs for SQA. To meet the challenge, in this paper we propose a joint retriever-reader model called JEEVES where the retriever is implicitly supervised only using QA labels via a novel word weighting mechanism. JEEVES significantly outperforms a variety of strong baselines on multiple-choice questions in three SQA datasets.
Automatic Rule Generation for Time Expression Normalization
Aug 31, 2021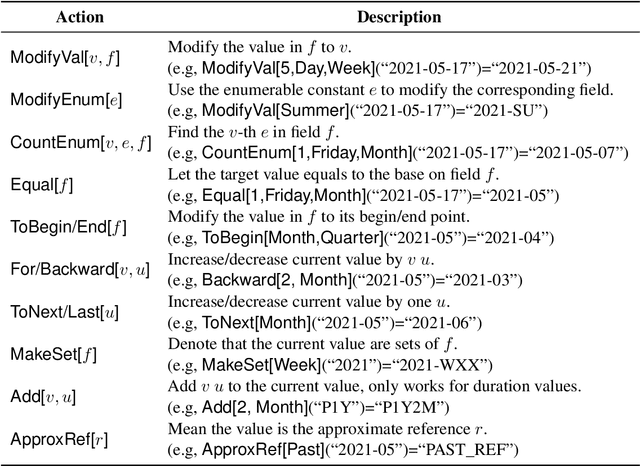
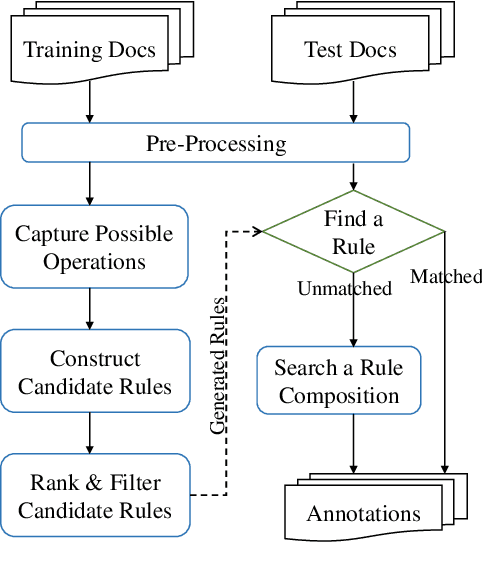

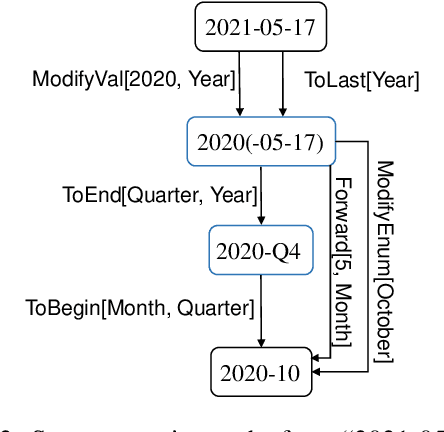
The understanding of time expressions includes two sub-tasks: recognition and normalization. In recent years, significant progress has been made in the recognition of time expressions while research on normalization has lagged behind. Existing SOTA normalization methods highly rely on rules or grammars designed by experts, which limits their performance on emerging corpora, such as social media texts. In this paper, we model time expression normalization as a sequence of operations to construct the normalized temporal value, and we present a novel method called ARTime, which can automatically generate normalization rules from training data without expert interventions. Specifically, ARTime automatically captures possible operation sequences from annotated data and generates normalization rules on time expressions with common surface forms. The experimental results show that ARTime can significantly surpass SOTA methods on the Tweets benchmark, and achieves competitive results with existing expert-engineered rule methods on the TempEval-3 benchmark.
TransEdge: Translating Relation-contextualized Embeddings for Knowledge Graphs
Apr 22, 2020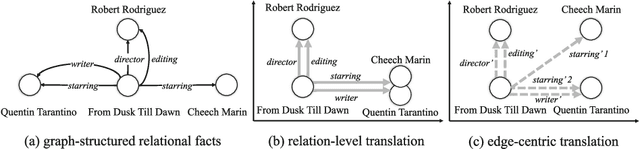
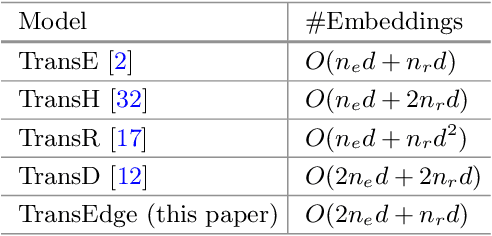

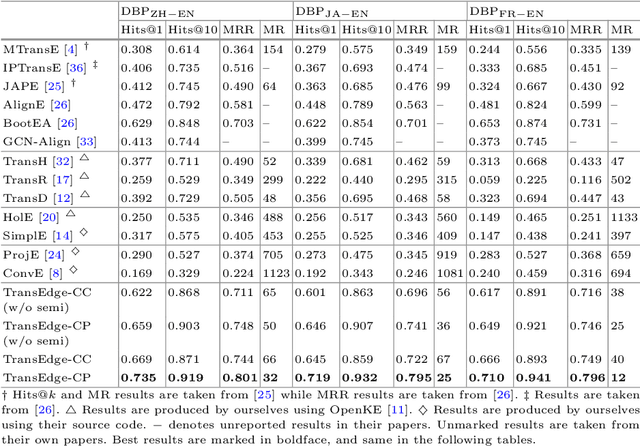
Learning knowledge graph (KG) embeddings has received increasing attention in recent years. Most embedding models in literature interpret relations as linear or bilinear mapping functions to operate on entity embeddings. However, we find that such relation-level modeling cannot capture the diverse relational structures of KGs well. In this paper, we propose a novel edge-centric embedding model TransEdge, which contextualizes relation representations in terms of specific head-tail entity pairs. We refer to such contextualized representations of a relation as edge embeddings and interpret them as translations between entity embeddings. TransEdge achieves promising performance on different prediction tasks. Our experiments on benchmark datasets indicate that it obtains the state-of-the-art results on embedding-based entity alignment. We also show that TransEdge is complementary with conventional entity alignment methods. Moreover, it shows very competitive performance on link prediction.
SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
Mar 31, 2020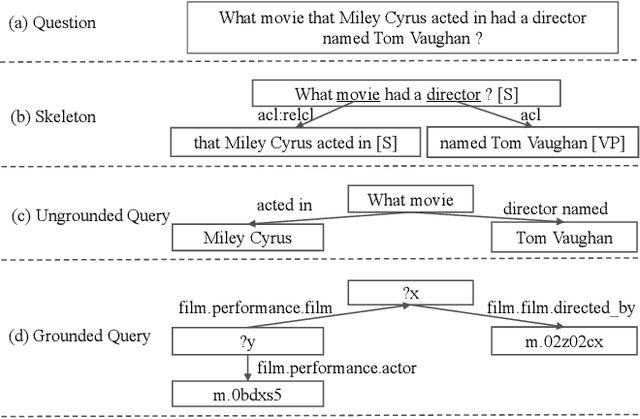
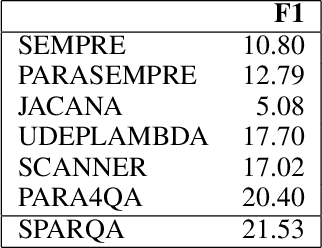
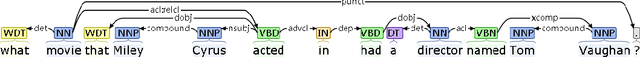

Semantic parsing transforms a natural language question into a formal query over a knowledge base. Many existing methods rely on syntactic parsing like dependencies. However, the accuracy of producing such expressive formalisms is not satisfying on long complex questions. In this paper, we propose a novel skeleton grammar to represent the high-level structure of a complex question. This dedicated coarse-grained formalism with a BERT-based parsing algorithm helps to improve the accuracy of the downstream fine-grained semantic parsing. Besides, to align the structure of a question with the structure of a knowledge base, our multi-strategy method combines sentence-level and word-level semantics. Our approach shows promising performance on several datasets.
DeepLENS: Deep Learning for Entity Summarization
Mar 08, 2020


Entity summarization has been a prominent task over knowledge graphs. While existing methods are mainly unsupervised, we present DeepLENS, a simple yet effective deep learning model where we exploit textual semantics for encoding triples and we score each candidate triple based on its interdependence on other triples. DeepLENS significantly outperformed existing methods on a public benchmark.