 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exact Sampling in the Two-Variable Fragment of First-Order Logic
Feb 06, 2023



In this paper, we study the sampling problem for first-order logic proposed recently by Wang et al. -- how to efficiently sample a model of a given first-order sentence on a finite domain? We extend their result for the universally-quantified subfragment of two-variable logic $\mathbf{FO}^2$ ($\mathbf{UFO}^2$) to the entire fragment of $\mathbf{FO}^2$. Specifically, we prove the domain-liftability under sampling of $\mathbf{FO}^2$, meaning that there exists a sampling algorithm for $\mathbf{FO}^2$ that runs in time polynomial in the domain size. We then further show that this result continues to hold even in the presence of counting constraints, such as $\forall x\exists_{=k} y: \varphi(x,y)$ and $\exists_{=k} x\forall y: \varphi(x,y)$, for some quantifier-free formula $\varphi(x,y)$. Our proposed method is constructive, and the resulting sampling algorithms have potential applications in various areas, including the uniform generation of combinatorial structures and sampling in statistical-relational models such as Markov logic networks and probabilistic logic programs.
Complex Handwriting Trajectory Recovery: Evaluation Metrics and Algorithm
Oct 28, 2022Many important tasks such as forensic signature verification, calligraphy synthesis, etc, rely on handwriting trajectory recovery of which, however, even an appropriate evaluation metric is still missing. Indeed, existing metrics only focus on the writing orders but overlook the fidelity of glyphs. Taking both facets into account, we come up with two new metrics, the adaptive intersection on union (AIoU) which eliminates the influence of various stroke widths, and the length-independent dynamic time warping (LDTW) which solves the trajectory-point alignment problem. After that, we then propose a novel handwriting trajectory recovery model named Parsing-and-tracing ENcoder-decoder Network (PEN-Net), in particular for characters with both complex glyph and long trajectory, which was believed very challenging. In the PEN-Net, a carefully designed double-stream parsing encoder parses the glyph structure, and a global tracing decoder overcomes the memory difficulty of long trajectory prediction. Our experiments demonstrate that the two new metrics AIoU and LDTW together can truly assess the quality of handwriting trajectory recovery and the proposed PEN-Net exhibits satisfactory performance in various complex-glyph languages including Chinese, Japanese and Indic.
Continuous Temporal Graph Networks for Event-Based Graph Data
May 31, 2022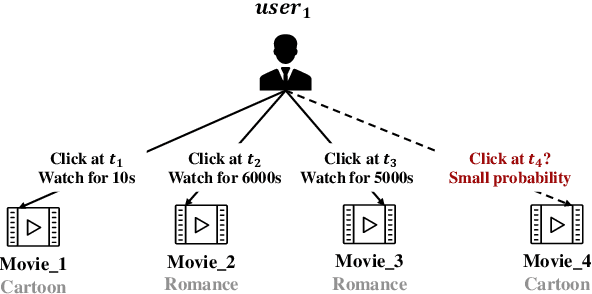
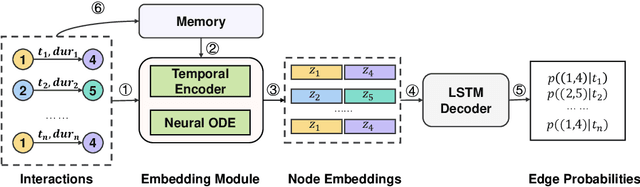
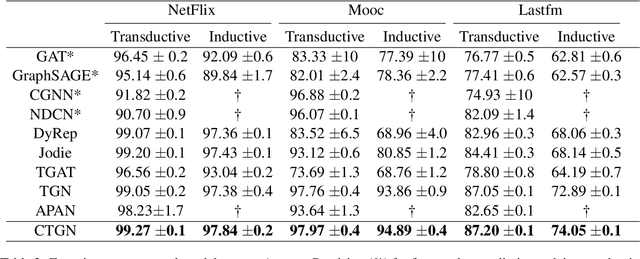
There has been an increasing interest in modeling continuous-time dynamics of temporal graph data. Previous methods encode time-evolving relational information into a low-dimensional representation by specifying discrete layers of neural networks, while real-world dynamic graphs often vary continuously over time. Hence, we propose Continuous Temporal Graph Networks (CTGNs) to capture the continuous dynamics of temporal graph data. We use both the link starting timestamps and link duration as evolving information to model the continuous dynamics of nodes. The key idea is to use neural ordinary differential equations (ODE) to characterize the continuous dynamics of node representations over dynamic graphs. We parameterize ordinary differential equations using a novel graph neural network. The existing dynamic graph networks can be considered as a specific discretization of CTGNs. Experiment results on both transductive and inductive tasks demonstrate the effectiveness of our proposed approach over competitive baselines.
Controllable Multi-Character Psychology-Oriented Story Generation
Oct 11, 2020
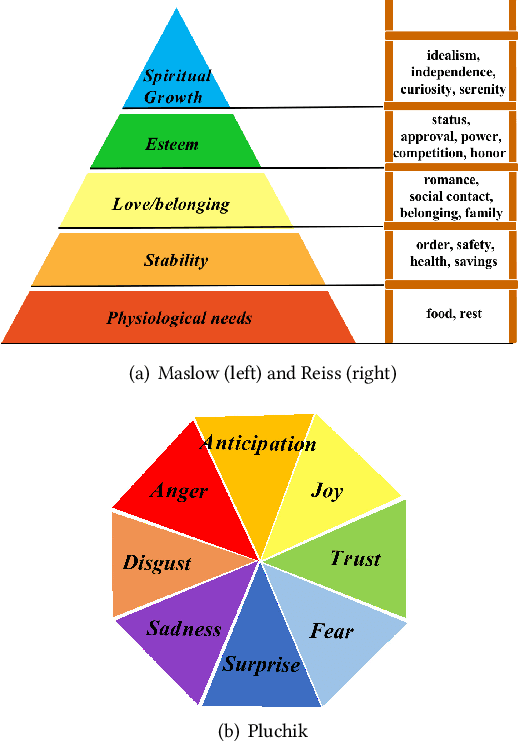
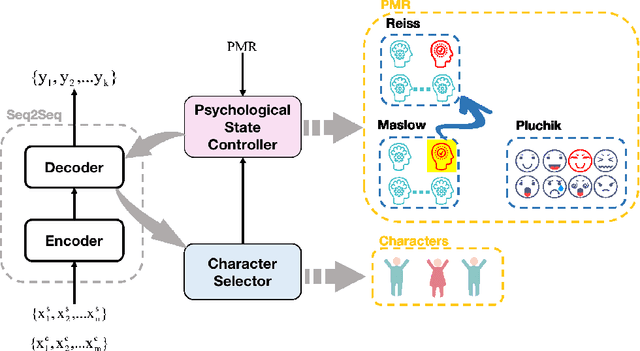
Story generation, which aims to generate a long and coherent story automatically based on the title or an input sentence, is an important research area in the field of natural language generation. There is relatively little work on story generation with appointed emotions. Most existing works focus on using only one specific emotion to control the generation of a whole story and ignore the emotional changes in the characters in the course of the story. In our work, we aim to design an emotional line for each character that considers multiple emotions common in psychological theories, with the goal of generating stories with richer emotional changes in the characters. To the best of our knowledge, this work is first to focuses on characters' emotional lines in story generation. We present a novel model-based attention mechanism that we call SoCP (Storytelling of multi-Character Psychology). We show that the proposed model can generate stories considering the changes in the psychological state of different characters. To take into account the particularity of the model, in addition to commonly used evaluation indicators(BLEU, ROUGE, etc.), we introduce the accuracy rate of psychological state control as a novel evaluation metric. The new indicator reflects the effect of the model on the psychological state control of story characters. Experiments show that with SoCP, the generated stories follow the psychological state for each character according to both automatic and human evaluations.
Graph Hawkes Network for Reasoning on Temporal Knowledge Graphs
Mar 31, 2020

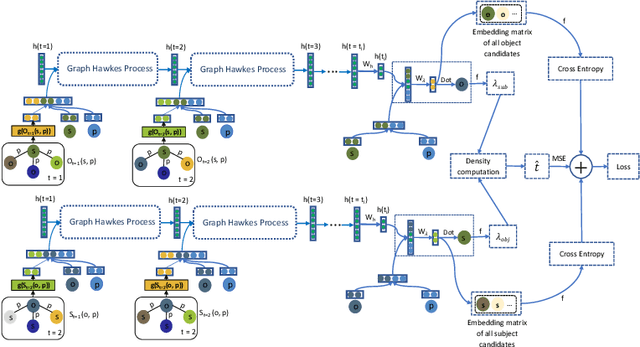
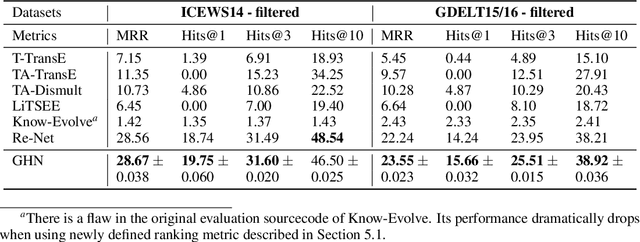
The Hawkes process has become a standard method for modeling self-exciting event sequences with different event types. A recent work generalizing the Hawkes process to a neurally self-modulating multivariate point process enables the capturing of more complex and realistic influences of past events on the future. However, this approach is limited by the number of event types, making it impossible to model the dynamics of evolving graph sequences, where each possible link between two nodes can be considered as an event type. The problem becomes even more dramatic when links are directional and labeled, since, in this case, the number of event types scales with the number of nodes and link types. To address this issue, we propose the Graph Hawkes Network to capture the dynamics of evolving graph sequences. Extensive experiments on large-scale temporal relational databases, such as temporal knowledge graphs, demonstrate the effectiveness of our approach.
Causal Inference under Networked Interference
Feb 20, 2020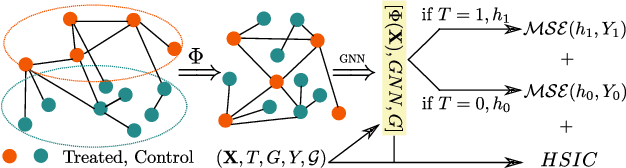
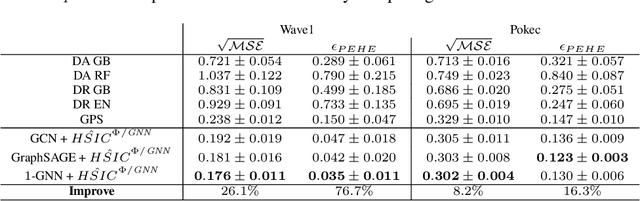
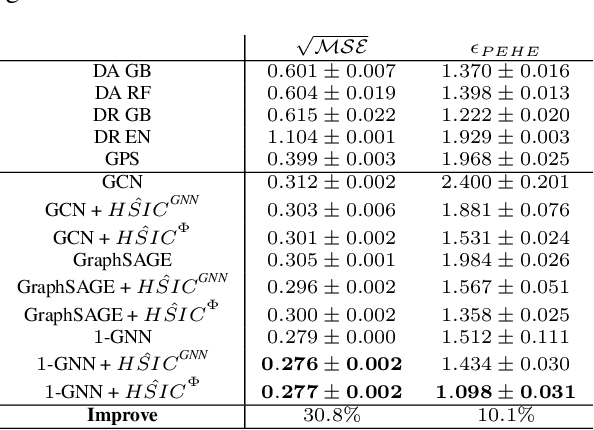

Estimating individual treatment effects from data of randomized experiments is a critical task in causal inference. The Stable Unit Treatment Value Assumption (SUTVA) is usually made in causal inference. However, interference can introduce bias when the assigned treatment on one unit affects the potential outcomes of the neighboring units. This interference phenomenon is known as spillover effect in economics or peer effect in social science. Usually, in randomized experiments or observational studies with interconnected units, one can only observe treatment responses under interference. Hence, how to estimate the superimposed causal effect and recover the individual treatment effect in the presence of interference becomes a challenging task in causal inference. In this work, we study causal effect estimation under general network interference using GNNs, which are powerful tools for capturing the dependency in the graph. After deriving causal effect estimators, we further study intervention policy improvement on the graph under capacity constraint. We give policy regret bounds under network interference and treatment capacity constraint. Furthermore, a heuristic graph structure-dependent error bound for GNN-based causal estimators is provided.
Domain-Liftability of Relational Marginal Polytopes
Jan 15, 2020We study computational aspects of relational marginal polytopes which are statistical relational learning counterparts of marginal polytopes, well-known from probabilistic graphical models. Here, given some first-order logic formula, we can define its relational marginal statistic to be the fraction of groundings that make this formula true in a given possible world. For a list of first-order logic formulas, the relational marginal polytope is the set of all points that correspond to the expected values of the relational marginal statistics that are realizable. In this paper, we study the following two problems: (i) Do domain-liftability results for the partition functions of Markov logic networks (MLNs) carry over to the problem of relational marginal polytope construction? (ii) Is the relational marginal polytope containment problem hard under some plausible complexity-theoretic assumptions? Our positive results have consequences for lifted weight learning of MLNs. In particular, we show that weight learning of MLNs is domain-liftable whenever the computation of the partition function of the respective MLNs is domain-liftable (this result has not been rigorously proven before).
Quantum Machine Learning Algorithm for Knowledge Graphs
Jan 04, 2020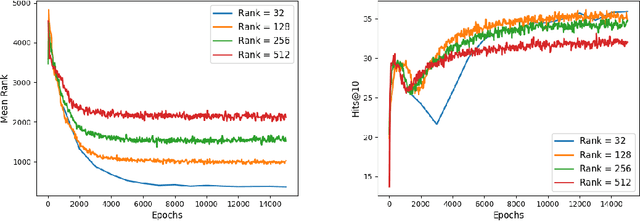
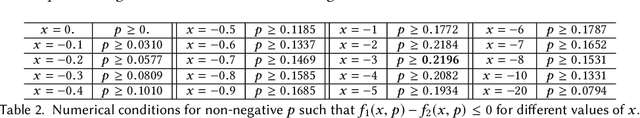
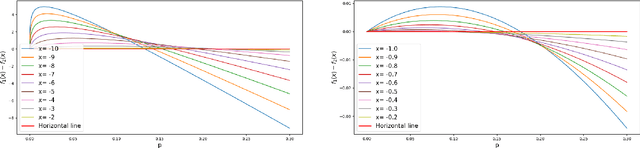
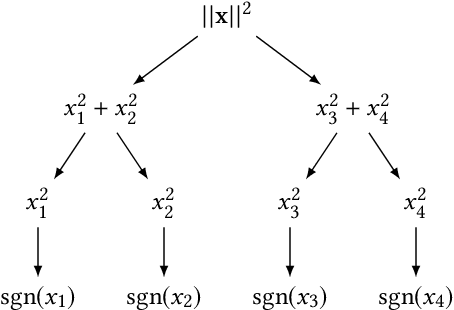
Semantic knowledge graphs are large-scale triple-oriented databases for knowledge representation and reasoning. Implicit knowledge can be inferred by modeling and reconstructing the tensor representations generated from knowledge graphs. However, as the sizes of knowledge graphs continue to grow, classical modeling becomes increasingly computational resource intensive. This paper investigates how quantum resources can be capitalized to accelerate the modeling of knowledge graphs. In particular, we propose the first quantum machine learning algorithm for making inference on tensorized data, e.g., on knowledge graphs. Since most tensor problems are NP-hard, it is challenging to devise quantum algorithms to support that task. We simplify the problem by making a plausible assumption that the tensor representation of a knowledge graph can be approximated by its low-rank tensor singular value decomposition, which is verified by our experiments. The proposed sampling-based quantum algorithm achieves exponential speedup with a runtime that is polylogarithmic in the dimension of knowledge graph tensor.
Improving Neural Relation Extraction with Positive and Unlabeled Learning
Nov 28, 2019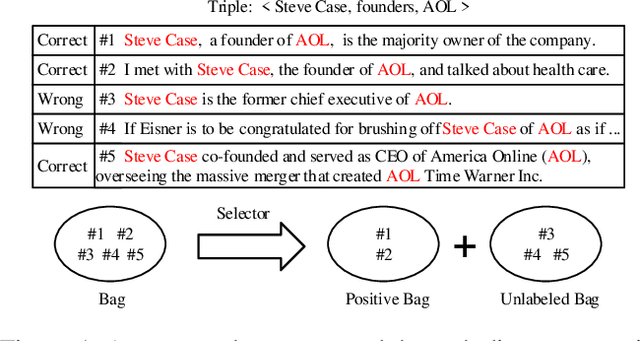
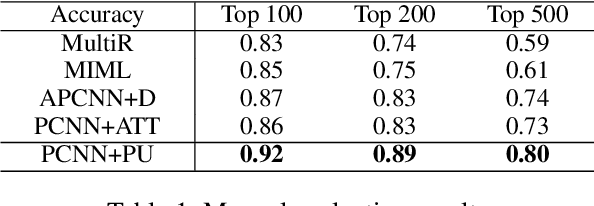
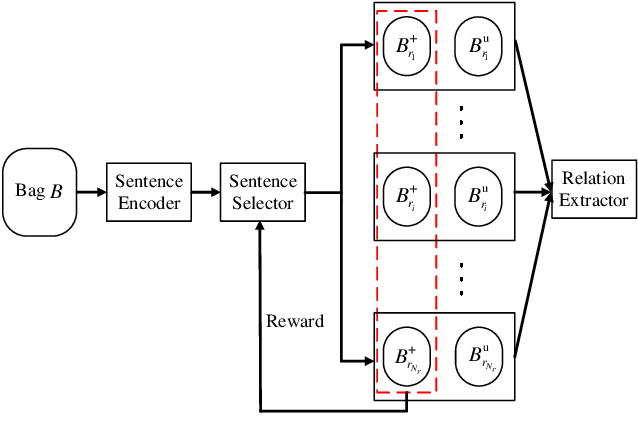
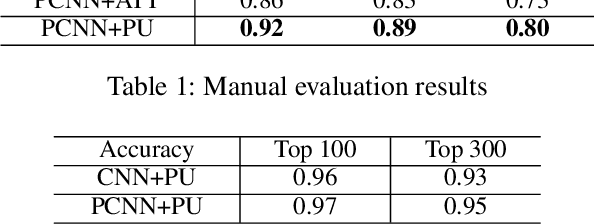
We present a novel approach to improve the performance of distant supervision relation extraction with Positive and Unlabeled (PU) Learning. This approach first applies reinforcement learning to decide whether a sentence is positive to a given relation, and then positive and unlabeled bags are constructed. In contrast to most previous studies, which mainly use selected positive instances only, we make full use of unlabeled instances and propose two new representations for positive and unlabeled bags. These two representations are then combined in an appropriate way to make bag-level prediction. Experimental results on a widely used real-world dataset demonstrate that this new approach indeed achieves significant and consistent improvements as compared to several competitive baselines.
McDiarmid-Type Inequalities for Graph-Dependent Variables and Stability Bounds
Sep 09, 2019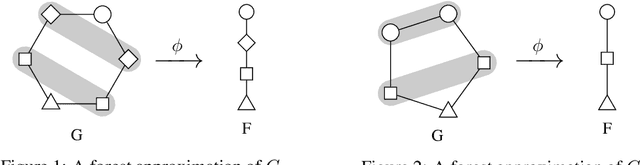
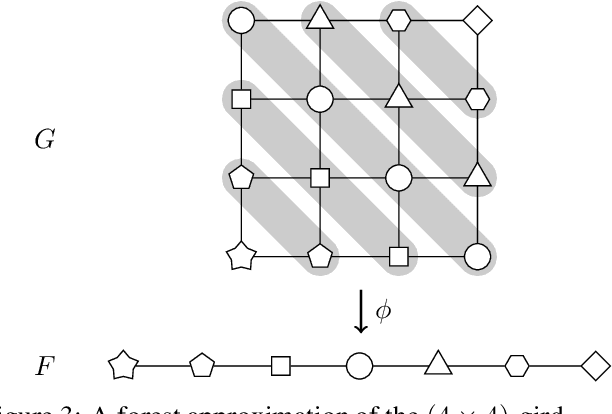
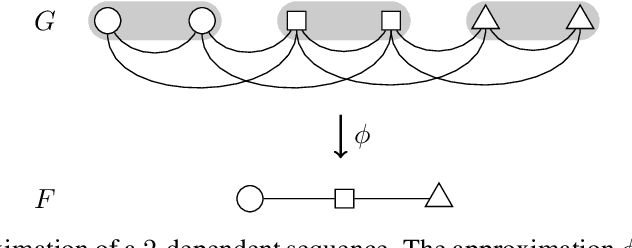
A crucial assumption in most statistical learning theory is that samples are independently and identically distributed (i.i.d.). However, for many real applications, the i.i.d. assumption does not hold. We consider learning problems in which examples are dependent and their dependency relation is characterized by a graph. To establish algorithm-dependent generalization theory for learning with non-i.i.d. data, we first prove novel McDiarmid-type concentration inequalities for Lipschitz functions of graph-dependent random variables. We show that concentration relies on the forest complexity of the graph, which characterizes the strength of the dependency. We demonstrate that for many types of dependent data, the forest complexity is small and thus implies good concentration. Based on our new inequalities we are able to build stability bounds for learning from graph-dependent data.