 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Speech Extraction Using Spatially Regularized Independent Low-rank Matrix Analysis and Rank-constrained Spatial Covariance Matrix Estimation
Mar 19, 2024


Real-time speech extraction is an important challenge with various applications such as speech recognition in a human-like avatar/robot. In this paper, we propose the real-time extension of a speech extraction method based on independent low-rank matrix analysis (ILRMA) and rank-constrained spatial covariance matrix estimation (RCSCME). The RCSCME-based method is a multichannel blind speech extraction method that demonstrates superior speech extraction performance in diffuse noise environments. To improve the performance, we introduce spatial regularization into the ILRMA part of the RCSCME-based speech extraction and design two regularizers. Speech extraction experiments demonstrated that the proposed methods can function in real time and the designed regularizers improve the speech extraction performance.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023



Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
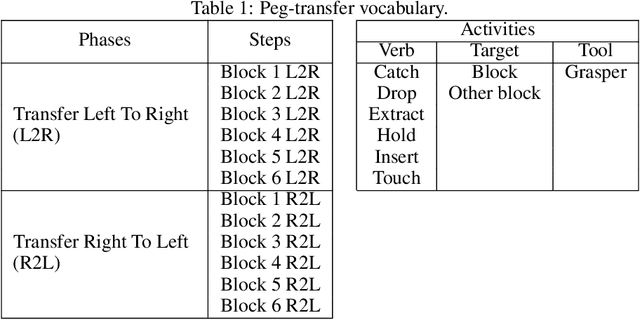
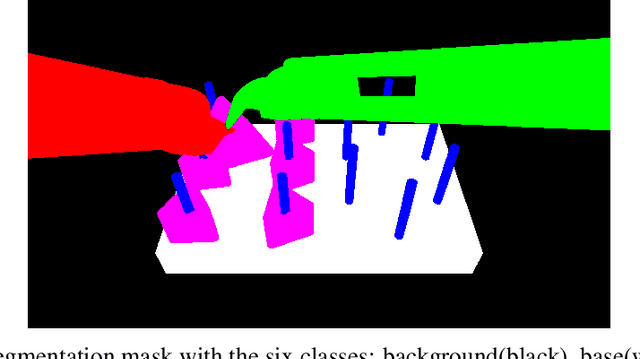
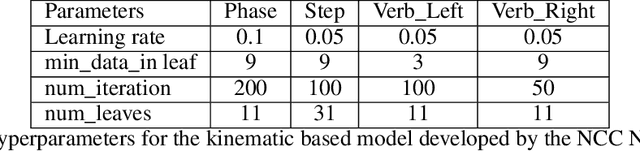
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.