 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singing Voice Conversion Challenge 2025: From Singer Identity Conversion To Singing Style Conversion
Sep 19, 2025We present the findings of the latest iteration of the Singing Voice Conversion Challenge, a scientific event aiming to compare and understand different voice conversion systems in a controlled environment. Compared to previous iterations which solely focused on converting the singer identity, this year we also focused on converting the singing style of the singer. To create a controlled environment and thorough evaluations, we developed a new challenge database, introduced two tasks, open-sourced baselines, and conducted large-scale crowd-sourced listening tests and objective evaluations. The challenge was ran for two months and in total we evaluated 26 different systems. The results of the large-scale crowd-sourced listening test showed that top systems had comparable singer identity scores to ground truth samples. However, modeling the singing style and consequently achieving high naturalness still remains a challenge in this task, primarily due to the difficulty in modeling dynamic information in breathy, glissando, and vibrato singing styles.
Automatic design optimization of preference-based subjective evaluation with online learning in crowdsourcing environment
Mar 10, 2024



A preference-based subjective evaluation is a key method for evaluating generative media reliably. However, its huge combinations of pairs prohibit it from being applied to large-scale evaluation using crowdsourcing. To address this issue, we propose an automatic optimization method for preference-based subjective evaluation in terms of pair combination selections and allocation of evaluation volumes with online learning in a crowdsourcing environment. We use a preference-based online learning method based on a sorting algorithm to identify the total order of evaluation targets with minimum sample volumes. Our online learning algorithm supports parallel and asynchronous execution under fixed-budget conditions required for crowdsourcing. Our experiment on preference-based subjective evaluation of synthetic speech shows that our method successfully optimizes the test by reducing pair combinations from 351 to 83 and allocating optimal evaluation volumes for each pair ranging from 30 to 663 without compromising evaluation accuracies and wasting budget allocations.
Preference-based training framework for automatic speech quality assessment using deep neural network
Aug 29, 2023One objective of Speech Quality Assessment (SQA) is to estimate the ranks of synthetic speech systems. However, recent SQA models are typically trained using low-precision direct scores such as mean opinion scores (MOS) as the training objective, which is not straightforward to estimate ranking. Although it is effective for predicting quality scores of individual sentences, this approach does not account for speech and system preferences when ranking multiple systems. We propose a training framework of SQA models that can be trained with only preference scores derived from pairs of MOS to improve ranking prediction. Our experiment reveals conditions where our framework works the best in terms of pair generation, aggregation functions to derive system score from utterance preferences, and threshold functions to determine preference from a pair of MOS. Our results demonstrate that our proposed method significantly outperforms the baseline model in Spearman's Rank Correlation Coefficient.
Investigation of Japanese PnG BERT language model in text-to-speech synthesis for pitch accent language
Dec 16, 2022End-to-end text-to-speech synthesis (TTS) can generate highly natural synthetic speech from raw text. However, rendering the correct pitch accents is still a challenging problem for end-to-end TTS. To tackle the challenge of rendering correct pitch accent in Japanese end-to-end TTS, we adopt PnG~BERT, a self-supervised pretrained model in the character and phoneme domain for TTS. We investigate the effects of features captured by PnG~BERT on Japanese TTS by modifying the fine-tuning condition to determine the conditions helpful inferring pitch accents. We manipulate content of PnG~BERT features from being text-oriented to speech-oriented by changing the number of fine-tuned layers during TTS. In addition, we teach PnG~BERT pitch accent information by fine-tuning with tone prediction as an additional downstream task. Our experimental results show that the features of PnG~BERT captured by pretraining contain information helpful inferring pitch accent, and PnG~BERT outperforms baseline Tacotron on accent correctness in a listening test.
Text-to-speech synthesis based on latent variable conversion using diffusion probabilistic model and variational autoencoder
Dec 16, 2022Text-to-speech synthesis (TTS) is a task to convert texts into speech. Two of the factors that have been driving TTS are the advancements of probabilistic models and latent representation learning. We propose a TTS method based on latent variable conversion using a diffusion probabilistic model and the variational autoencoder (VAE). In our TTS method, we use a waveform model based on VAE, a diffusion model that predicts the distribution of latent variables in the waveform model from texts, and an alignment model that learns alignments between the text and speech latent sequences. Our method integrates diffusion with VAE by modeling both mean and variance parameters with diffusion, where the target distribution is determined by approximation from VAE. This latent variable conversion framework potentially enables us to flexibly incorporate various latent feature extractors. Our experiments show that our method is robust to linguistic labels with poor orthography and alignment errors.
ESPnet2-TTS: Extending the Edge of TTS Research
Oct 15, 2021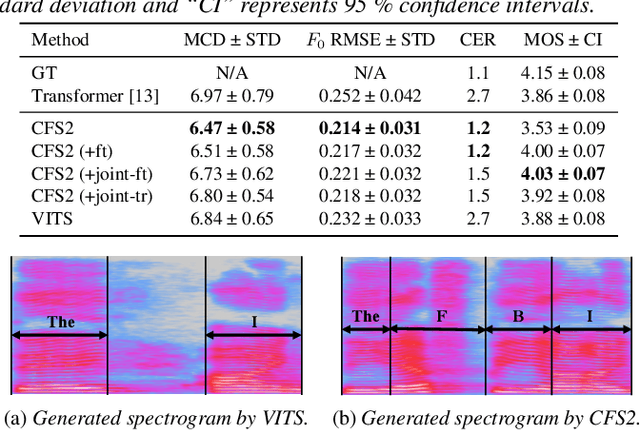
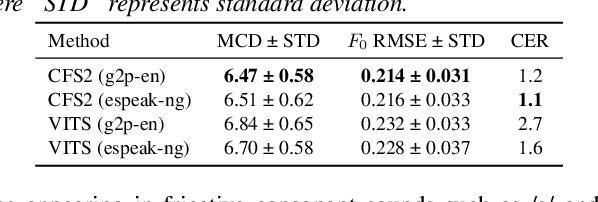
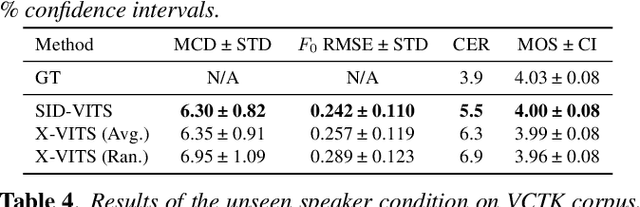

This paper describes ESPnet2-TTS, an end-to-end text-to-speech (E2E-TTS) toolkit. ESPnet2-TTS extends our earlier version, ESPnet-TTS, by adding many new features, including: on-the-fly flexible pre-processing, joint training with neural vocoders, and state-of-the-art TTS models with extensions like full-band E2E text-to-waveform modeling, which simplify the training pipeline and further enhance TTS performance. The unified design of our recipes enables users to quickly reproduce state-of-the-art E2E-TTS results. We also provide many pre-trained models in a unified Python interface for inference, offering a quick means for users to generate baseline samples and build demos. Experimental evaluations with English and Japanese corpora demonstrate that our provided models synthesize utterances comparable to ground-truth ones, achieving state-of-the-art TTS performance. The toolkit is available online at https://github.com/espnet/espnet.
Pretraining Strategies, Waveform Model Choice, and Acoustic Configurations for Multi-Speaker End-to-End Speech Synthesis
Nov 10, 2020
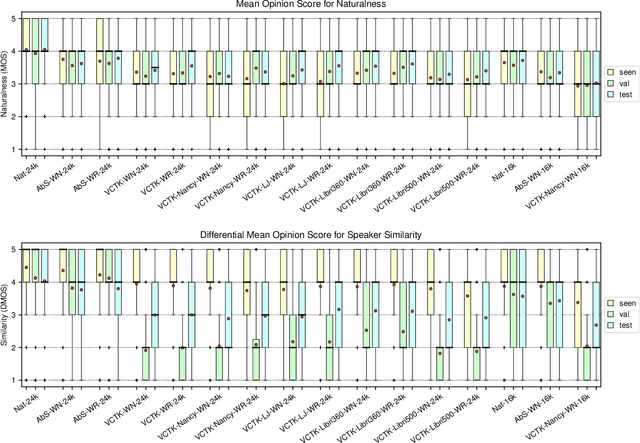
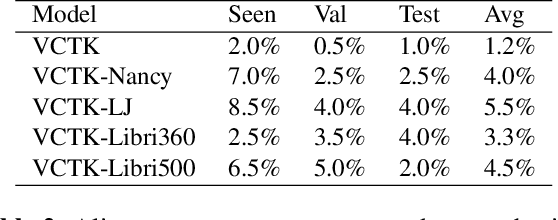
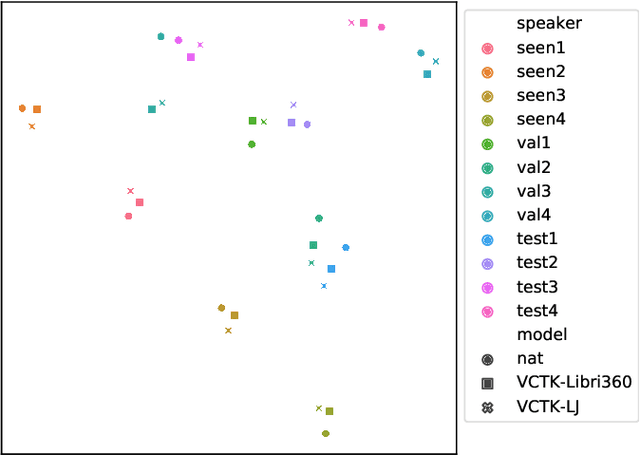
We explore pretraining strategies including choice of base corpus with the aim of choosing the best strategy for zero-shot multi-speaker end-to-end synthesis. We also examine choice of neural vocoder for waveform synthesis, as well as acoustic configurations used for mel spectrograms and final audio output. We find that fine-tuning a multi-speaker model from found audiobook data that has passed a simple quality threshold can improve naturalness and similarity to unseen target speakers of synthetic speech. Additionally, we find that listeners can discern between a 16kHz and 24kHz sampling rate, and that WaveRNN produces output waveforms of a comparable quality to WaveNet, with a faster inference time.
End-to-End Text-to-Speech using Latent Duration based on VQ-VAE
Oct 20, 2020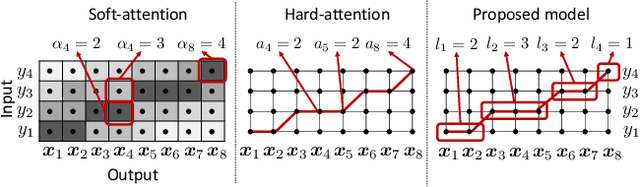
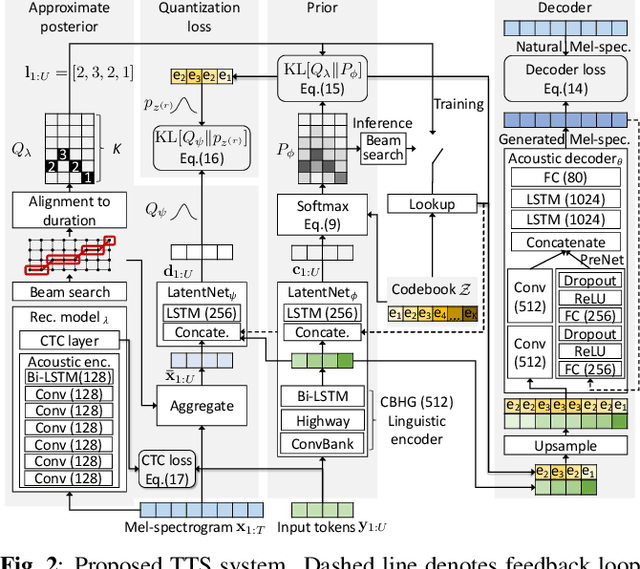
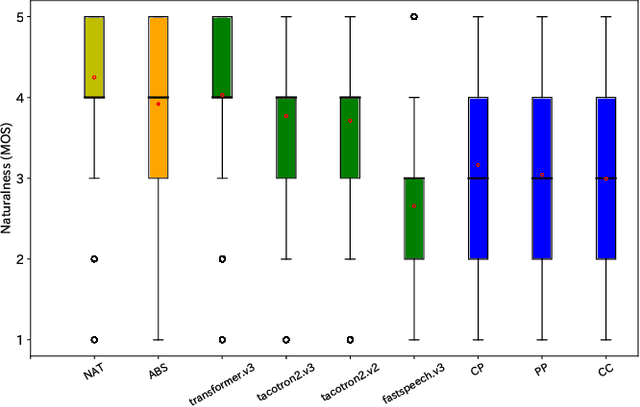
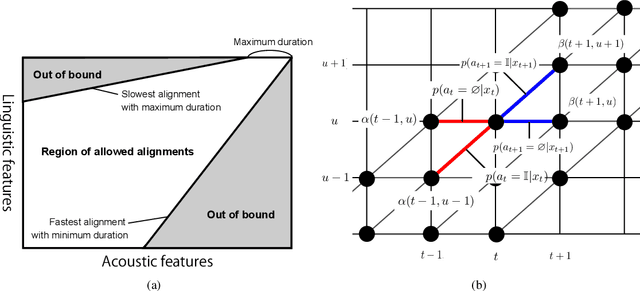
Explicit duration modeling is a key to achieving robust and efficient alignment in text-to-speech synthesis (TTS). We propose a new TTS framework using explicit duration modeling that incorporates duration as a discrete latent variable to TTS and enables joint optimization of whole modules from scratch. We formulate our method based on conditional VQ-VAE to handle discrete duration in a variational autoencoder and provide a theoretical explanation to justify our method. In our framework, a connectionist temporal classification (CTC) -based force aligner acts as the approximate posterior, and text-to-duration works as the prior in the variational autoencoder. We evaluated our proposed method with a listening test and compared it with other TTS methods based on soft-attention or explicit duration modeling. The results showed that our systems rated between soft-attention-based methods (Transformer-TTS, Tacotron2) and explicit duration modeling-based methods (Fastspeech).
Investigation of learning abilities on linguistic features in sequence-to-sequence text-to-speech synthesis
May 20, 2020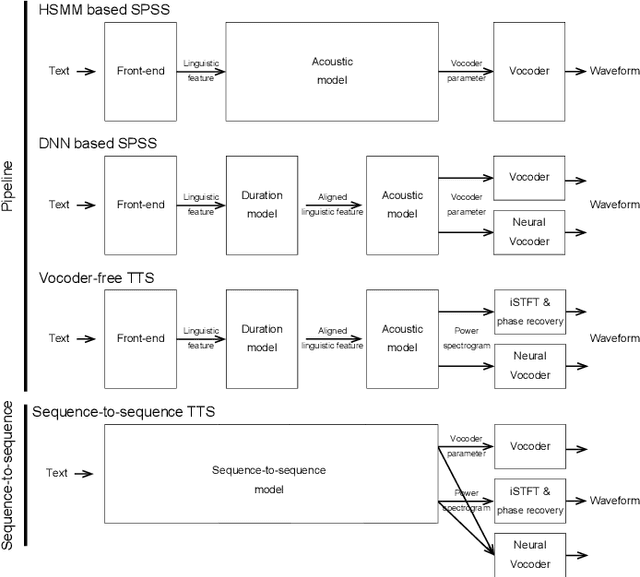
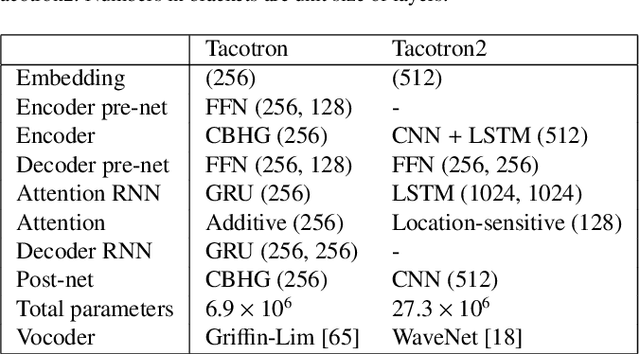
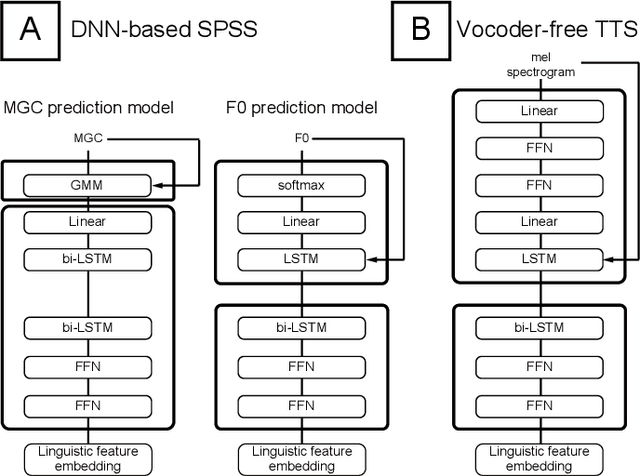
Neural sequence-to-sequence text-to-speech synthesis (TTS) can produce high-quality speech directly from text or simple linguistic features such as phonemes. Unlike traditional pipeline TTS, the neural sequence-to-sequence TTS does not require manually annotated and complicated linguistic features such as part-of-speech tags and syntactic structures for system training. However, it must be carefully designed and well optimized so that it can implicitly extract useful linguistic features from the input features. In this paper we investigate under what conditions the neural sequence-to-sequence TTS can work well in Japanese and English along with comparisons with deep neural network (DNN) based pipeline TTS systems. Unlike past comparative studies, the pipeline systems also use autoregressive probabilistic modeling and a neural vocoder. We investigated systems from three aspects: a) model architecture, b) model parameter size, and c) language. For the model architecture aspect, we adopt modified Tacotron systems that we previously proposed and their variants using an encoder from Tacotron or Tacotron2. For the model parameter size aspect, we investigate two model parameter sizes. For the language aspect, we conduct listening tests in both Japanese and English to see if our findings can be generalized across languages. Our experiments suggest that a) a neural sequence-to-sequence TTS system should have a sufficient number of model parameters to produce high quality speech, b) it should also use a powerful encoder when it takes characters as inputs, and c) the encoder still has a room for improvement and needs to have an improved architecture to learn supra-segmental features more appropriately.
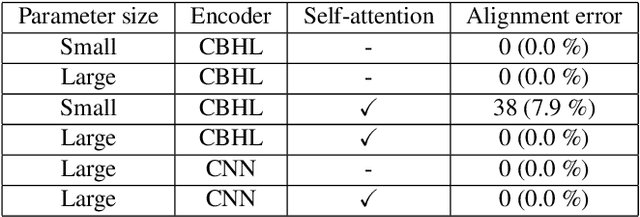
Effect of choice of probability distribution, randomness, and search methods for alignment modeling in sequence-to-sequence text-to-speech synthesis using hard alignment
Oct 28, 2019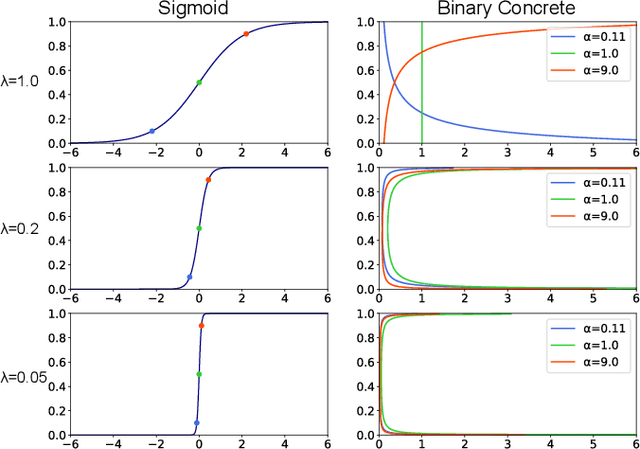
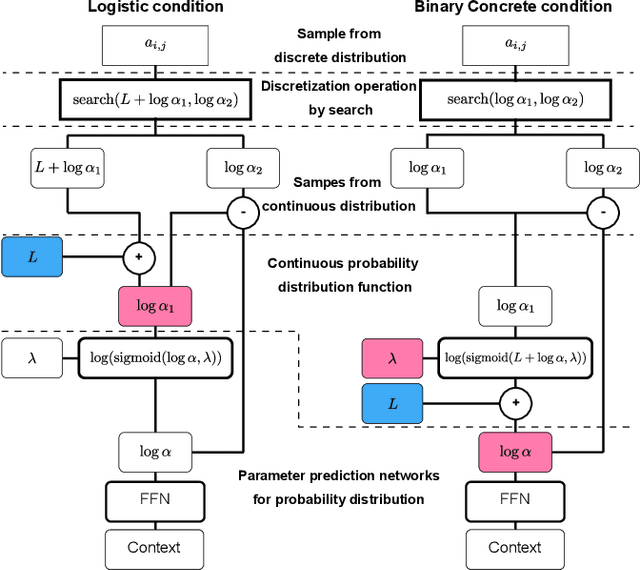
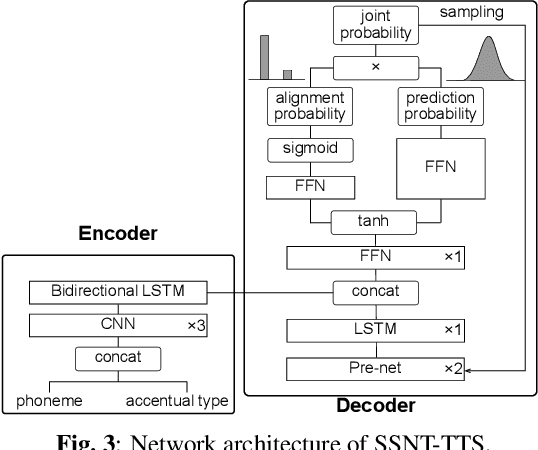
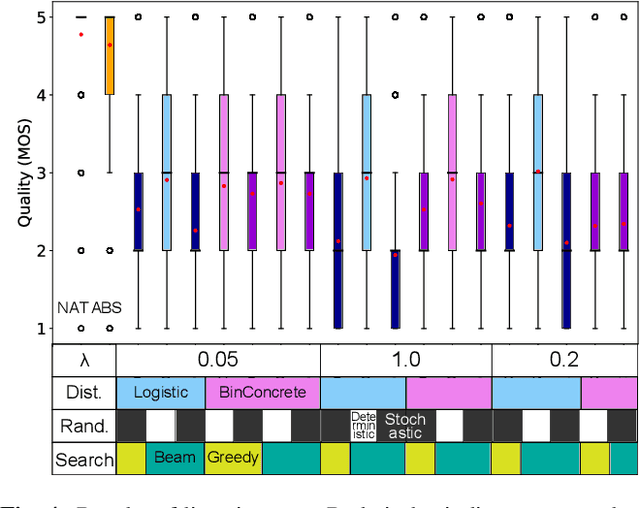
Sequence-to-sequence text-to-speech (TTS) is dominated by soft-attention-based methods. Recently, hard-attention-based methods have been proposed to prevent fatal alignment errors, but their sampling method of discrete alignment is poorly investigated. This research investigates various combinations of sampling methods and probability distributions for alignment transition modeling in a hard-alignment-based sequence-to-sequence TTS method called SSNT-TTS. We clarify the common sampling methods of discrete variables including greedy search, beam search, and random sampling from a Bernoulli distribution in a more general way. Furthermore, we introduce the binary Concrete distribution to model discrete variables more properly. The results of a listening test shows that deterministic search is more preferable than stochastic search, and the binary Concrete distribution is robust with stochastic search for natural alignment transition.