 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Parallelized Reinforcement Learning Training with Relaxed Assignment Dependencies
Feb 27, 2025As the demands for superior agents grow, the training complexity of Deep Reinforcement Learning (DRL) becomes higher. Thus, accelerating training of DRL has become a major research focus. Dividing the DRL training process into subtasks and using parallel computation can effectively reduce training costs. However, current DRL training systems lack sufficient parallelization due to data assignment between subtask components. This assignment issue has been ignored, but addressing it can further boost training efficiency. Therefore, we propose a high-throughput distributed RL training system called TianJi. It relaxes assignment dependencies between subtask components and enables event-driven asynchronous communication. Meanwhile, TianJi maintains clear boundaries between subtask components. To address convergence uncertainty from relaxed assignment dependencies, TianJi proposes a distributed strategy based on the balance of sample production and consumption. The strategy controls the staleness of samples to correct their quality, ensuring convergence. We conducted extensive experiments. TianJi achieves a convergence time acceleration ratio of up to 4.37 compared to related comparison systems. When scaled to eight computational nodes, TianJi shows a convergence time speedup of 1.6 and a throughput speedup of 7.13 relative to XingTian, demonstrating its capability to accelerate training and scalability. In data transmission efficiency experiments, TianJi significantly outperforms other systems, approaching hardware limits. TianJi also shows effectiveness in on-policy algorithms, achieving convergence time acceleration ratios of 4.36 and 2.95 compared to RLlib and XingTian. TianJi is accessible at https://github.com/HiPRL/TianJi.git.
Angel or Devil: Discriminating Hard Samples and Anomaly Contaminations for Unsupervised Time Series Anomaly Detection
Oct 26, 2024



Training in unsupervised time series anomaly detection is constantly plagued by the discrimination between harmful `anomaly contaminations' and beneficial `hard normal samples'. These two samples exhibit analogous loss behavior that conventional loss-based methodologies struggle to differentiate. To tackle this problem, we propose a novel approach that supplements traditional loss behavior with `parameter behavior', enabling a more granular characterization of anomalous patterns. Parameter behavior is formalized by measuring the parametric response to minute perturbations in input samples. Leveraging the complementary nature of parameter and loss behaviors, we further propose a dual Parameter-Loss Data Augmentation method (termed PLDA), implemented within the reinforcement learning paradigm. During the training phase of anomaly detection, PLDA dynamically augments the training data through an iterative process that simultaneously mitigates anomaly contaminations while amplifying informative hard normal samples. PLDA demonstrates remarkable versatility, which can serve as an additional component that seamlessly integrated with existing anomaly detectors to enhance their detection performance. Extensive experiments on ten datasets show that PLDA significantly improves the performance of four distinct detectors by up to 8\%, outperforming three state-of-the-art data augmentation methods.
Real-Time 3D Occupancy Prediction via Geometric-Semantic Disentanglement
Jul 18, 2024Occupancy prediction plays a pivotal role in autonomous driving (AD) due to the fine-grained geometric perception and general object recognition capabilities. However, existing methods often incur high computational costs, which contradicts the real-time demands of AD. To this end, we first evaluate the speed and memory usage of most public available methods, aiming to redirect the focus from solely prioritizing accuracy to also considering efficiency. We then identify a core challenge in achieving both fast and accurate performance: \textbf{the strong coupling between geometry and semantic}. To address this issue, 1) we propose a Geometric-Semantic Dual-Branch Network (GSDBN) with a hybrid BEV-Voxel representation. In the BEV branch, a BEV-level temporal fusion module and a U-Net encoder is introduced to extract dense semantic features. In the voxel branch, a large-kernel re-parameterized 3D convolution is proposed to refine sparse 3D geometry and reduce computation. Moreover, we propose a novel BEV-Voxel lifting module that projects BEV features into voxel space for feature fusion of the two branches. In addition to the network design, 2) we also propose a Geometric-Semantic Decoupled Learning (GSDL) strategy. This strategy initially learns semantics with accurate geometry using ground-truth depth, and then gradually mixes predicted depth to adapt the model to the predicted geometry. Extensive experiments on the widely-used Occ3D-nuScenes benchmark demonstrate the superiority of our method, which achieves a 39.4 mIoU with 20.0 FPS. This result is $\sim 3 \times$ faster and +1.9 mIoU higher compared to FB-OCC, the winner of CVPR2023 3D Occupancy Prediction Challenge. Our code will be made open-source.
MixTEA: Semi-supervised Entity Alignment with Mixture Teaching
Nov 08, 2023



Semi-supervised entity alignment (EA) is a practical and challenging task because of the lack of adequate labeled mappings as training data. Most works address this problem by generating pseudo mappings for unlabeled entities. However, they either suffer from the erroneous (noisy) pseudo mappings or largely ignore the uncertainty of pseudo mappings. In this paper, we propose a novel semi-supervised EA method, termed as MixTEA, which guides the model learning with an end-to-end mixture teaching of manually labeled mappings and probabilistic pseudo mappings. We firstly train a student model using few labeled mappings as standard. More importantly, in pseudo mapping learning, we propose a bi-directional voting (BDV) strategy that fuses the alignment decisions in different directions to estimate the uncertainty via the joint matching confidence score. Meanwhile, we also design a matching diversity-based rectification (MDR) module to adjust the pseudo mapping learning, thus reducing the negative influence of noisy mappings. Extensive results on benchmark datasets as well as further analyses demonstrate the superiority and the effectiveness of our proposed method.
Multi-scale Recurrent LSTM and Transformer Network for Depth Completion
Sep 28, 2023Lidar depth completion is a new and hot topic of depth estimation. In this task, it is the key and difficult point to fuse the features of color space and depth space. In this paper, we migrate the classic LSTM and Transformer modules from NLP to depth completion and redesign them appropriately. Specifically, we use Forget gate, Update gate, Output gate, and Skip gate to achieve the efficient fusion of color and depth features and perform loop optimization at multiple scales. Finally, we further fuse the deep features through the Transformer multi-head attention mechanism. Experimental results show that without repetitive network structure and post-processing steps, our method can achieve state-of-the-art performance by adding our modules to a simple encoder-decoder network structure. Our method ranks first on the current mainstream autonomous driving KITTI benchmark dataset. It can also be regarded as a backbone network for other methods, which likewise achieves state-of-the-art performance.
USD: Unknown Sensitive Detector Empowered by Decoupled Objectness and Segment Anything Model
Jun 04, 2023Open World Object Detection (OWOD) is a novel and challenging computer vision task that enables object detection with the ability to detect unknown objects. Existing methods typically estimate the object likelihood with an additional objectness branch, but ignore the conflict in learning objectness and classification boundaries, which oppose each other on the semantic manifold and training objective. To address this issue, we propose a simple yet effective learning strategy, namely Decoupled Objectness Learning (DOL), which divides the learning of these two boundaries into suitable decoder layers. Moreover, detecting unknown objects comprehensively requires a large amount of annotations, but labeling all unknown objects is both difficult and expensive. Therefore, we propose to take advantage of the recent Large Vision Model (LVM), specifically the Segment Anything Model (SAM), to enhance the detection of unknown objects. Nevertheless, the output results of SAM contain noise, including backgrounds and fragments, so we introduce an Auxiliary Supervision Framework (ASF) that uses a pseudo-labeling and a soft-weighting strategies to alleviate the negative impact of noise. Extensive experiments on popular benchmarks, including Pascal VOC and MS COCO, demonstrate the effectiveness of our approach. Our proposed Unknown Sensitive Detector (USD) outperforms the recent state-of-the-art methods in terms of Unknown Recall, achieving significant improvements of 14.3\%, 15.5\%, and 8.9\% on the M-OWODB, and 27.1\%, 29.1\%, and 25.1\% on the S-OWODB.
Improving Knowledge Graph Entity Alignment with Graph Augmentation
Apr 28, 2023Entity alignment (EA) which links equivalent entities across different knowledge graphs (KGs) plays a crucial role in knowledge fusion. In recent years, graph neural networks (GNNs) have been successfully applied in many embedding-based EA methods. However, existing GNN-based methods either suffer from the structural heterogeneity issue that especially appears in the real KG distributions or ignore the heterogeneous representation learning for unseen (unlabeled) entities, which would lead the model to overfit on few alignment seeds (i.e., training data) and thus cause unsatisfactory alignment performance. To enhance the EA ability, we propose GAEA, a novel EA approach based on graph augmentation. In this model, we design a simple Entity-Relation (ER) Encoder to generate latent representations for entities via jointly modeling comprehensive structural information and rich relation semantics. Moreover, we use graph augmentation to create two graph views for margin-based alignment learning and contrastive entity representation learning, thus mitigating structural heterogeneity and further improving the model's alignment performance. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of our method.
Pseudo-label Correction and Learning For Semi-Supervised Object Detection
Mar 06, 2023



Pseudo-Labeling has emerged as a simple yet effective technique for semi-supervised object detection (SSOD). However, the inevitable noise problem in pseudo-labels significantly degrades the performance of SSOD methods. Recent advances effectively alleviate the classification noise in SSOD, while the localization noise which is a non-negligible part of SSOD is not well-addressed. In this paper, we analyse the localization noise from the generation and learning phases, and propose two strategies, namely pseudo-label correction and noise-unaware learning. For pseudo-label correction, we introduce a multi-round refining method and a multi-vote weighting method. The former iteratively refines the pseudo boxes to improve the stability of predictions, while the latter smoothly self-corrects pseudo boxes by weighing the scores of surrounding jittered boxes. For noise-unaware learning, we introduce a loss weight function that is negatively correlated with the Intersection over Union (IoU) in the regression task, which pulls the predicted boxes closer to the object and improves localization accuracy. Our proposed method, Pseudo-label Correction and Learning (PCL), is extensively evaluated on the MS COCO and PASCAL VOC benchmarks. On MS COCO, PCL outperforms the supervised baseline by 12.16, 12.11, and 9.57 mAP and the recent SOTA (SoftTeacher) by 3.90, 2.54, and 2.43 mAP under 1\%, 5\%, and 10\% labeling ratios, respectively. On PASCAL VOC, PCL improves the supervised baseline by 5.64 mAP and the recent SOTA (Unbiased Teacherv2) by 1.04 mAP on AP$^{50}$.
Adversarial Learning-based Stance Classifier for COVID-19-related Health Policies
Sep 13, 2022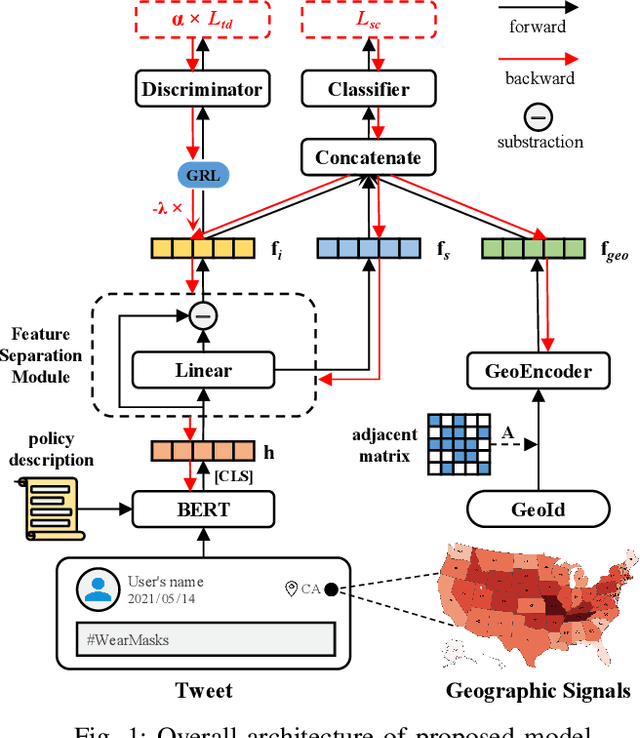
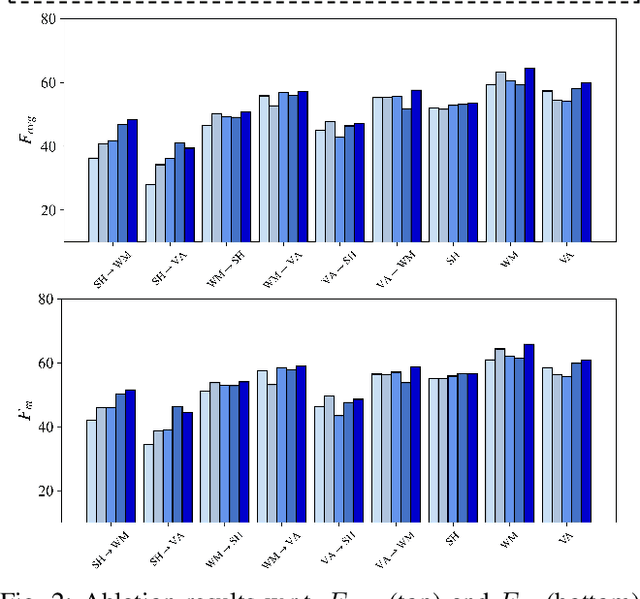
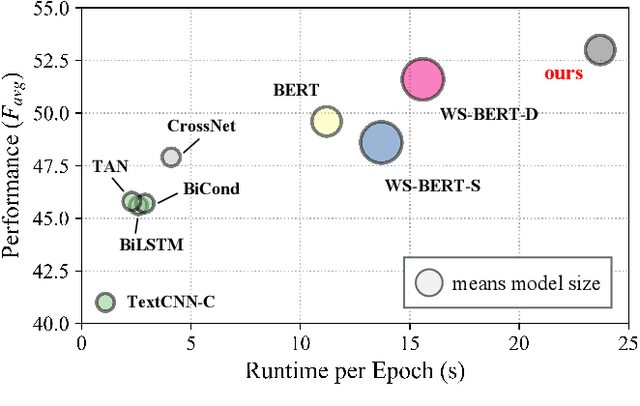
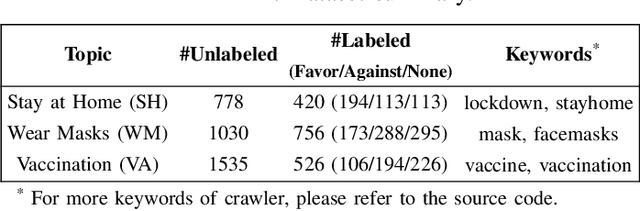
The ongoing COVID-19 pandemic has caused immeasurable losses for people worldwide. To contain the spread of virus and further alleviate the crisis, various health policies (e.g., stay-at-home orders) have been issued which spark heat discussion as users turn to share their attitudes on social media. In this paper, we consider a more realistic scenario on stance detection (i.e., cross-target and zero-shot settings) for the pandemic and propose an adversarial learning-based stance classifier to automatically identify the public attitudes toward COVID-19-related health policies. Specifically, we adopt adversarial learning which allows the model to train on a large amount of labeled data and capture transferable knowledge from source topics, so as to enable generalize to the emerging health policy with sparse labeled data. Meanwhile, a GeoEncoder is designed which encourages model to learn unobserved contextual factors specified by each region and represents them as non-text information to enhance model's deeper understanding. We evaluate the performance of a broad range of baselines in stance detection task for COVID-19-related policies, and experimental results show that our proposed method achieves state-of-the-art performance in both cross-target and zero-shot settings.
EpiGNN: Exploring Spatial Transmission with Graph Neural Network for Regional Epidemic Forecasting
Aug 23, 2022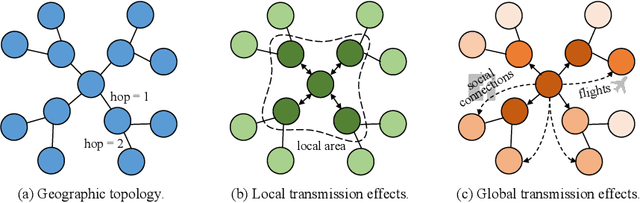
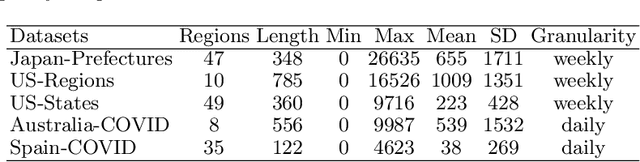
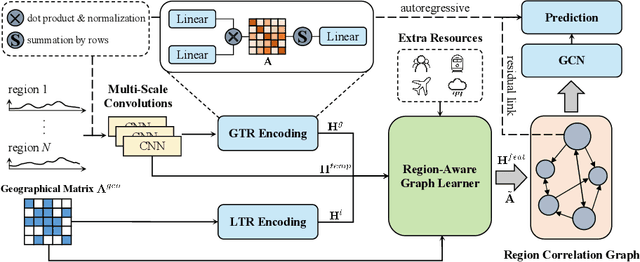
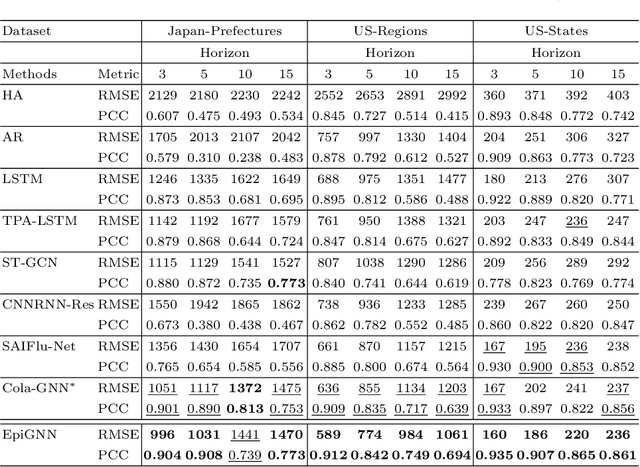
Epidemic forecasting is the key to effective control of epidemic transmission and helps the world mitigate the crisis that threatens public health. To better understand the transmission and evolution of epidemics, we propose EpiGNN, a graph neural network-based model for epidemic forecasting. Specifically, we design a transmission risk encoding module to characterize local and global spatial effects of regions in epidemic processes and incorporate them into the model. Meanwhile, we develop a Region-Aware Graph Learner (RAGL) that takes transmission risk, geographical dependencies, and temporal information into account to better explore spatial-temporal dependencies and makes regions aware of related regions' epidemic situations. The RAGL can also combine with external resources, such as human mobility, to further improve prediction performance. Comprehensive experiments on five real-world epidemic-related datasets (including influenza and COVID-19) demonstrate the effectiveness of our proposed method and show that EpiGNN outperforms state-of-the-art baselines by 9.48% in RMSE.