 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianDream: A Feed-Forward 3D Gaussian World Model for Robotic Manipulation
May 20, 2026Vision-language-action (VLA) policies have advanced language-conditioned robotic manipulation by transferring semantic priors from pretrained vision-language models to action generation. Yet, standard action-imitation training often provides limited explicit supervision for 3D geometry, dense visual structure, and short-horizon environment evolution, which are critical for physically precise manipulation. We introduce \textbf{GaussianDream}, a feed-forward 3D Gaussian world-model plug-in that turns robot trajectories into structured spatial-temporal supervision. The key idea is to couple current Gaussian reconstruction with horizon-conditioned future Gaussian prediction during training, forcing a compact spatio-temporal prefix to be decodable into renderable 3D Gaussian states. This enables dense RGB rendering, depth, and pseudo 3D scene-flow supervision without requiring test-time Gaussian decoding. At inference, GaussianDream discards all auxiliary decoding heads and retains only the learned prefix to condition action generation, avoiding rendering, video rollout, or additional planning during closed-loop control. Experiments on LIBERO, RoboCasa Human-50, and real-robot tasks demonstrate strong and highly competitive performance, achieving \textbf{98.4\%} average success on LIBERO, \textbf{52.6\%} on RoboCasa Human-50, and \textbf{50.0\%} in real-world evaluation.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Autonomous Vehicle Benchmarking using Unbiased Metrics
Jun 03, 2020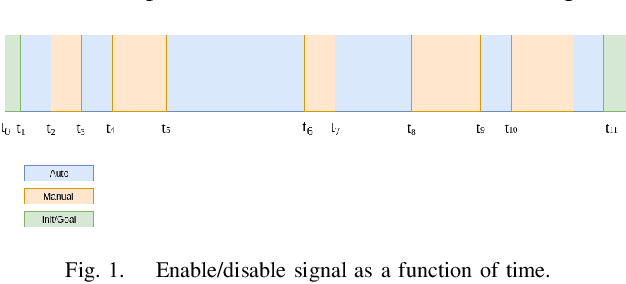
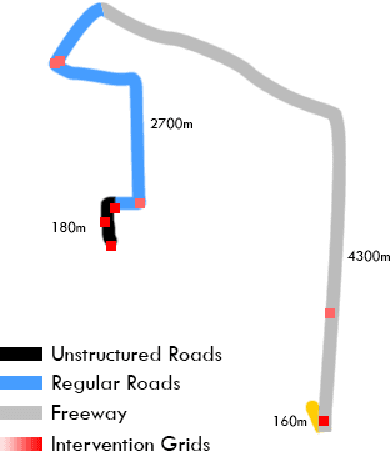

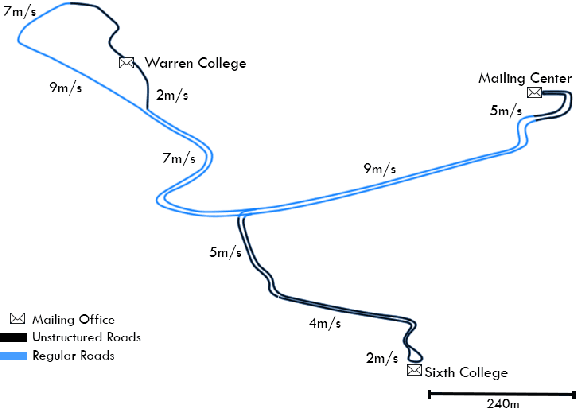
With the recent development of autonomous vehicle technology, there have been active efforts on the deployment of this technology at different scales that include urban and highway driving. While many of the prototypes showcased have shown to operate under specific cases, little effort has been made to better understand their shortcomings and generalizability to new areas. Distance, uptime and number of manual disengagements performed during autonomous driving provide a high-level idea on the performance of an autonomous system but without proper data normalization, testing location information, and the number of vehicles involved in testing, the disengagement reports alone do not fully encompass system performance and robustness. Thus, in this study a complete set of metrics are proposed for benchmarking autonomous vehicle systems in a variety of scenarios that can be extended for comparison with human drivers. These metrics have been used to benchmark UC San Diego's autonomous vehicle platforms during early deployments for micro-transit and autonomous mail delivery applications.