 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Jun 10, 2026Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably predict behavior. Recent work documented substantial SR-behavior dissociation in LLMs, but relied on broad personality traits (Big 5) that predict specific behaviors weakly, even in humans. Furthermore, the isolation of conversational sessions combined with weak context matching left open whether LLMs truly lack coherence or whether the conditions needed to detect such coherence were not met. We contrast Big 5 with the Theory of Planned Behavior (TPB), which measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits. We run experiments across four behavioral tasks and 11 frontier LLMs, while also varying session context and identity induction. We find that SR-behavior coherence exists but is selective. 1) Within a shared conversation, the Theory of Planned Behavior reaches human-level coherence; Big 5 does not. 2) Across separate conversations, coherence survives only for behaviors anchored outside the immediate prompt, such as implicit bias shaped by training, and collapses when behavior is strongly primed by context, as with sycophancy. 3) Persona prompting makes self-reports more consistent across conversations, but does not bring behavior into alignment. These findings suggest that coarse personality frameworks, such as Big 5 may not be the best tools for testing deployment behavior. More task- and behavior-specific instruments are needed, and even these must be evaluated across tasks and contexts.
Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems
Apr 14, 2026Large language models (LLMs) have transformed AI research thanks to their powerful internal capabilities and knowledge. However, existing LLMs still fail to effectively incorporate the massive external knowledge when interacting with the world. Although retrieval-augmented LLMs are proposed to mitigate the issue, they are still fundamentally constrained by the context length of LLMs, as they can only retrieve top-K raw data chunks from the external knowledge base which often consists of millions of data chunks. Here we propose Thought-Retriever, a novel model-agnostic algorithm that helps LLMs generate output conditioned on arbitrarily long external data, without being constrained by the context length or number of retrieved data chunks. Our key insight is to let an LLM fully leverage its intermediate responses generated when solving past user queries (thoughts), filtering meaningless and redundant thoughts, organizing them in thought memory, and retrieving the relevant thoughts when addressing new queries. This effectively equips LLM-based agents with a self-evolving long-term memory that grows more capable through continuous interaction. Besides algorithmic innovation, we further meticulously prepare a novel benchmark, AcademicEval, which requires an LLM to faithfully leverage ultra-long context to answer queries based on real-world academic papers. Extensive experiments on AcademicEval and two other public datasets validate that Thought-Retriever remarkably outperforms state-of-the-art baselines, achieving an average increase of at least 7.6% in F1 score and 16% in win rate across various tasks. More importantly, we further demonstrate two exciting findings: (1) Thought-Retriever can indeed help LLM self-evolve after solving more user queries; (2) Thought-Retriever learns to leverage deeper thoughts to answer more abstract user queries.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Large Language Model Reasoning Failures
Feb 05, 2026Large Language Models (LLMs) have exhibited remarkable reasoning capabilities, achieving impressive results across a wide range of tasks. Despite these advances, significant reasoning failures persist, occurring even in seemingly simple scenarios. To systematically understand and address these shortcomings, we present the first comprehensive survey dedicated to reasoning failures in LLMs. We introduce a novel categorization framework that distinguishes reasoning into embodied and non-embodied types, with the latter further subdivided into informal (intuitive) and formal (logical) reasoning. In parallel, we classify reasoning failures along a complementary axis into three types: fundamental failures intrinsic to LLM architectures that broadly affect downstream tasks; application-specific limitations that manifest in particular domains; and robustness issues characterized by inconsistent performance across minor variations. For each reasoning failure, we provide a clear definition, analyze existing studies, explore root causes, and present mitigation strategies. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. We additionally release a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at https://github.com/Peiyang-Song/Awesome-LLM-Reasoning-Failures, to provide an easy entry point to this area.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
Adaptation of Agentic AI
Dec 22, 2025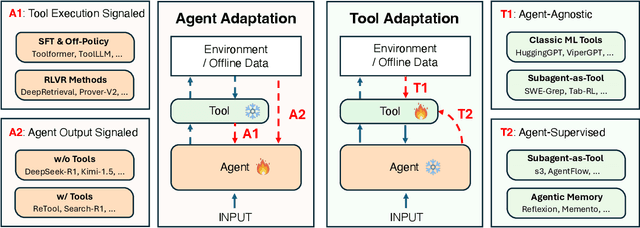
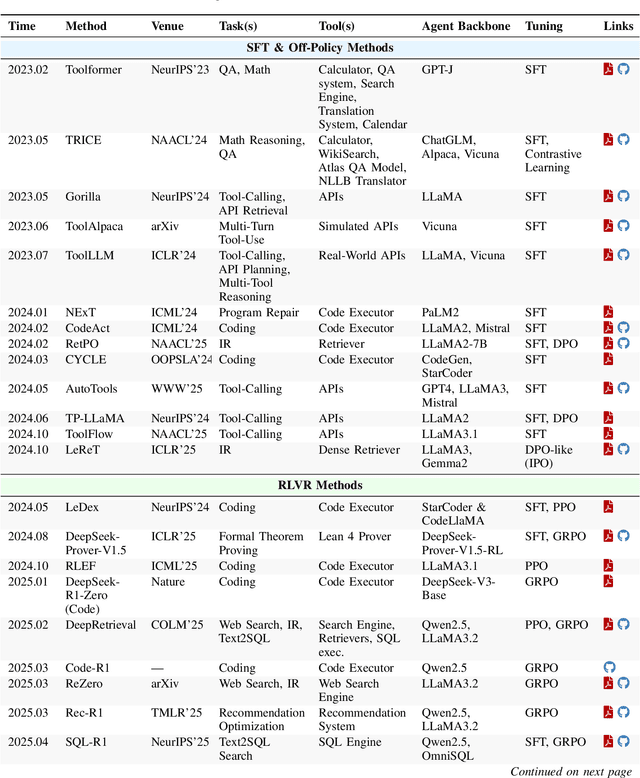
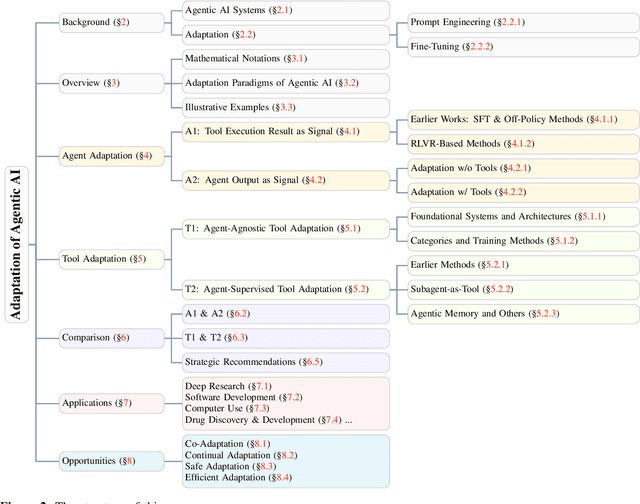
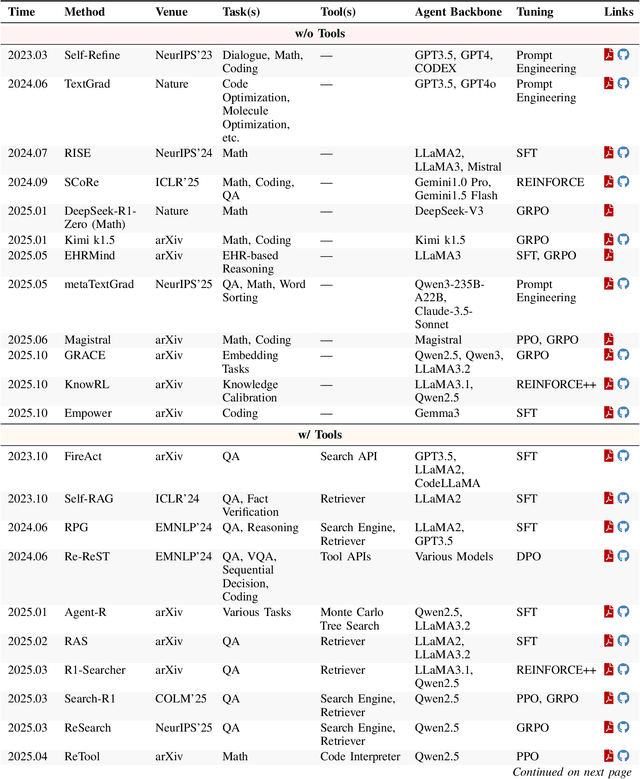
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
Sep 03, 2025Personality traits have long been studied as predictors of human behavior.Recent advances in Large Language Models (LLMs) suggest similar patterns may emerge in artificial systems, with advanced LLMs displaying consistent behavioral tendencies resembling human traits like agreeableness and self-regulation. Understanding these patterns is crucial, yet prior work primarily relied on simplified self-reports and heuristic prompting, with little behavioral validation. In this study, we systematically characterize LLM personality across three dimensions: (1) the dynamic emergence and evolution of trait profiles throughout training stages; (2) the predictive validity of self-reported traits in behavioral tasks; and (3) the impact of targeted interventions, such as persona injection, on both self-reports and behavior. Our findings reveal that instructional alignment (e.g., RLHF, instruction tuning) significantly stabilizes trait expression and strengthens trait correlations in ways that mirror human data. However, these self-reported traits do not reliably predict behavior, and observed associations often diverge from human patterns. While persona injection successfully steers self-reports in the intended direction, it exerts little or inconsistent effect on actual behavior. By distinguishing surface-level trait expression from behavioral consistency, our findings challenge assumptions about LLM personality and underscore the need for deeper evaluation in alignment and interpretability.
Paper Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance
Sep 06, 2024



As scientific research proliferates, researchers face the daunting task of navigating and reading vast amounts of literature. Existing solutions, such as document QA, fail to provide personalized and up-to-date information efficiently. We present Paper Copilot, a self-evolving, efficient LLM system designed to assist researchers, based on thought-retrieval, user profile and high performance optimization. Specifically, Paper Copilot can offer personalized research services, maintaining a real-time updated database. Quantitative evaluation demonstrates that Paper Copilot saves 69.92\% of time after efficient deployment. This paper details the design and implementation of Paper Copilot, highlighting its contributions to personalized academic support and its potential to streamline the research process.
ChatGPT Based Data Augmentation for Improved Parameter-Efficient Debiasing of LLMs
Feb 19, 2024Large Language models (LLMs), while powerful, exhibit harmful social biases. Debiasing is often challenging due to computational costs, data constraints, and potential degradation of multi-task language capabilities. This work introduces a novel approach utilizing ChatGPT to generate synthetic training data, aiming to enhance the debiasing of LLMs. We propose two strategies: Targeted Prompting, which provides effective debiasing for known biases but necessitates prior specification of bias in question; and General Prompting, which, while slightly less effective, offers debiasing across various categories. We leverage resource-efficient LLM debiasing using adapter tuning and compare the effectiveness of our synthetic data to existing debiasing datasets. Our results reveal that: (1) ChatGPT can efficiently produce high-quality training data for debiasing other LLMs; (2) data produced via our approach surpasses existing datasets in debiasing performance while also preserving internal knowledge of a pre-trained LLM; and (3) synthetic data exhibits generalizability across categories, effectively mitigating various biases, including intersectional ones. These findings underscore the potential of synthetic data in advancing the fairness of LLMs with minimal retraining cost.
Exploring Social Bias in Downstream Applications of Text-to-Image Foundation Models
Dec 05, 2023



Text-to-image diffusion models have been adopted into key commercial workflows, such as art generation and image editing. Characterising the implicit social biases they exhibit, such as gender and racial stereotypes, is a necessary first step in avoiding discriminatory outcomes. While existing studies on social bias focus on image generation, the biases exhibited in alternate applications of diffusion-based foundation models remain under-explored. We propose methods that use synthetic images to probe two applications of diffusion models, image editing and classification, for social bias. Using our methodology, we uncover meaningful and significant inter-sectional social biases in \textit{Stable Diffusion}, a state-of-the-art open-source text-to-image model. Our findings caution against the uninformed adoption of text-to-image foundation models for downstream tasks and services.