 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Face Reenactment
Aug 05, 2019
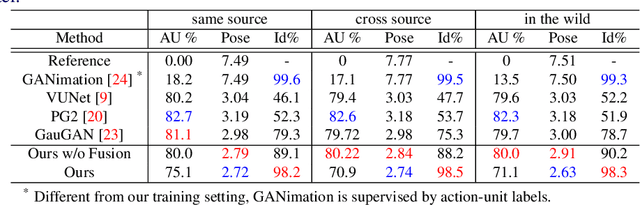
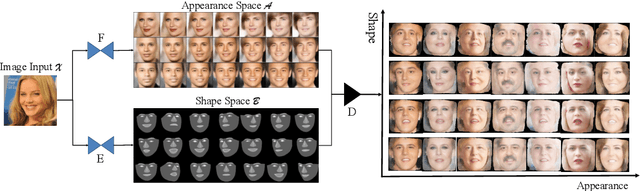
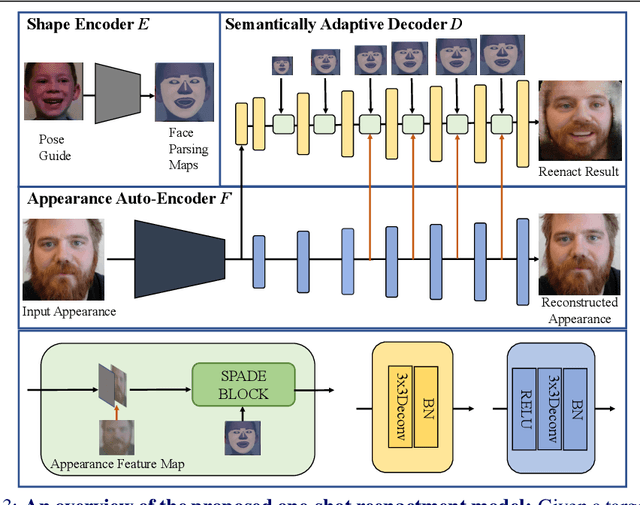
To enable realistic shape (e.g. pose and expression) transfer, existing face reenactment methods rely on a set of target faces for learning subject-specific traits. However, in real-world scenario end-users often only have one target face at hand, rendering existing methods inapplicable. In this work, we bridge this gap by proposing a novel one-shot face reenactment learning framework. Our key insight is that the one-shot learner should be able to disentangle and compose appearance and shape information for effective modeling. Specifically, the target face appearance and the source face shape are first projected into latent spaces with their corresponding encoders. Then these two latent spaces are associated by learning a shared decoder that aggregates multi-level features to produce the final reenactment results. To further improve the synthesizing quality on mustache and hair regions, we additionally propose FusionNet which combines the strengths of our learned decoder and the traditional warping method. Extensive experiments show that our one-shot face reenactment system achieves superior transfer fidelity as well as identity preserving capability than alternatives. More remarkably, our approach trained with only one target image per subject achieves competitive results to those using a set of target images, demonstrating the practical merit of this work. Code, models and an additional set of reenacted faces have been publicly released at the project page.
CMR motion artifact correction using generative adversarial nets
Feb 21, 2019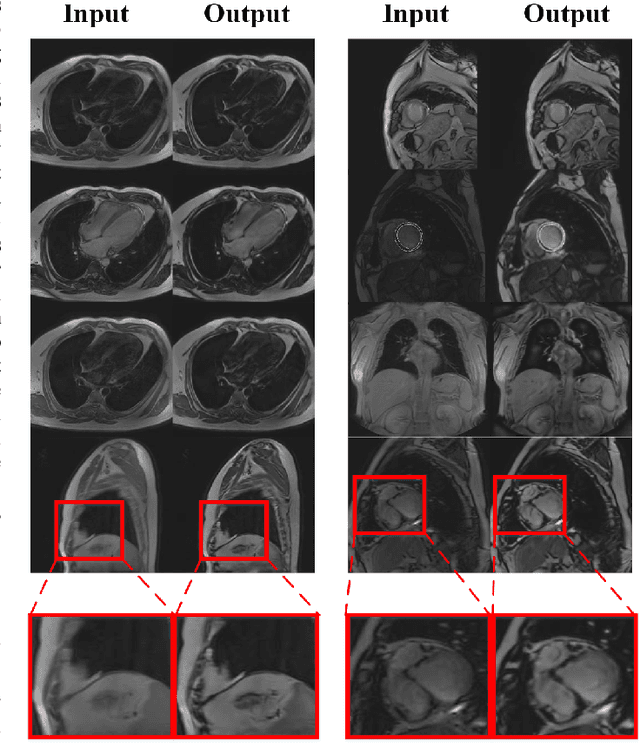
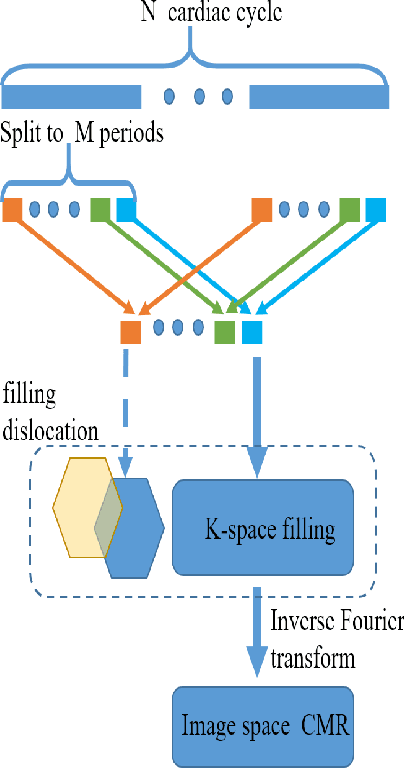
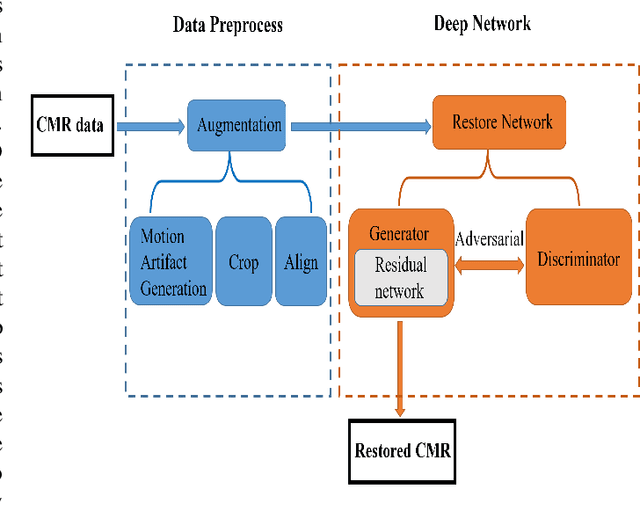
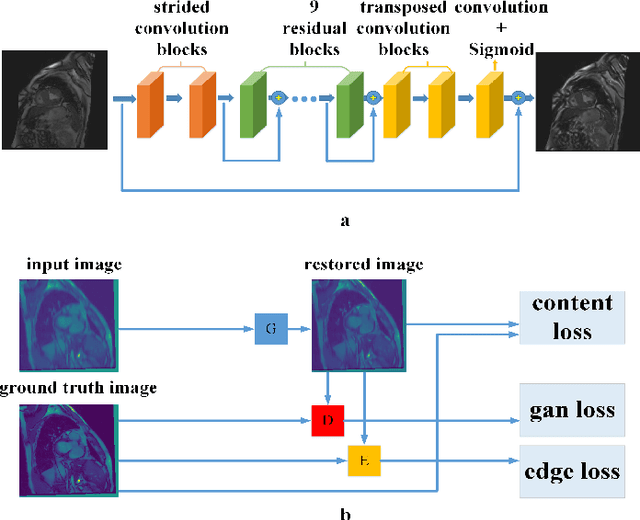
Cardiovascular Magnetic Resonance (CMR) plays an important role in the diagnoses and treatment of cardiovascular diseases while motion artifacts which are formed during the scanning process of CMR seriously affects doctors to find the exact focus. The current correction methods mainly focus on the K-space which is a grid of raw data obtained from the MR signal directly and then transfer to CMR image by inverse Fourier transform. They are neither effective nor efficient and can not be utilized in clinic. In this paper, we propose a novel approach for CMR motion artifact correction using deep learning. Specially, we use deep residual network (ResNet) as net framework and train our model in adversarial manner. Our approach is motivated by the connection between image motion blur and CMR motion artifact, so we can transfer methods from motion-deblur where deep learning has made great progress to CMR motion-correction successfully. To evaluate motion artifact correction methods, we propose a novel algorithm on how edge detection results are improved by deblurred algorithm. Boosted by deep learning and adversarial training algorithm, our model is trainable in an end-to-end manner, can be tested in real-time and achieves the state-of-art results for CMR correction.
ReenactGAN: Learning to Reenact Faces via Boundary Transfer
Jul 29, 2018
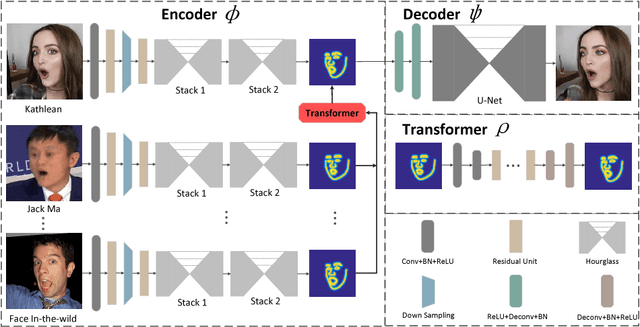
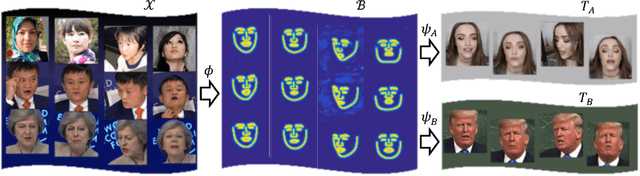
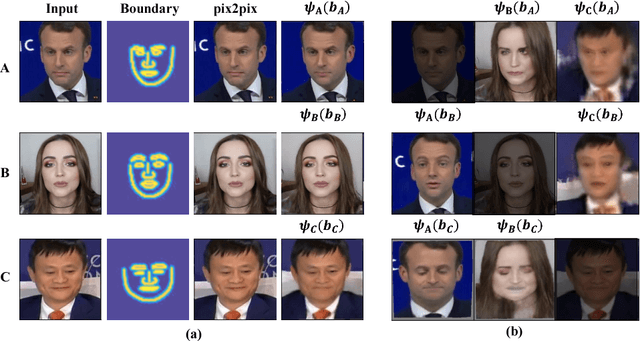
We present a novel learning-based framework for face reenactment. The proposed method, known as ReenactGAN, is capable of transferring facial movements and expressions from monocular video input of an arbitrary person to a target person. Instead of performing a direct transfer in the pixel space, which could result in structural artifacts, we first map the source face onto a boundary latent space. A transformer is subsequently used to adapt the boundary of source face to the boundary of target face. Finally, a target-specific decoder is used to generate the reenacted target face. Thanks to the effective and reliable boundary-based transfer, our method can perform photo-realistic face reenactment. In addition, ReenactGAN is appealing in that the whole reenactment process is purely feed-forward, and thus the reenactment process can run in real-time (30 FPS on one GTX 1080 GPU). Dataset and model will be publicly available at https://wywu.github.io/projects/ReenactGAN/ReenactGAN.html