 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-CA: Separating Common and Salient Factors with Diffusion Models
Jun 04, 2026Contrastive Analysis aims to separate factors that are common between two data distributions from those that are salient to only one of them. Existing contrastive methods are based on generative models (e.g., VAEs or GANs) that often suffer from limited reconstruction and image quality, which hampers effective latent factor separation and limits their applicability to high-fidelity image generation and edition. We propose a novel conditioning framework for diffusion models that enables contrastive decomposition without compromising generation quality. We first train a prompt-free, image-conditioned diffusion model, and then learn to decompose the conditioning into a common and a salient factor, using weak supervision. We prove that the additive contrastive factorization, commonly assumed in prior work, is identifiable under mild conditions. This factorization enables targeted operations by swapping or interpolating only the salient factor.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Learning Common and Salient Generative Factors Between Two Image Datasets
Dec 14, 2025Recent advancements in image synthesis have enabled high-quality image generation and manipulation. Most works focus on: 1) conditional manipulation, where an image is modified conditioned on a given attribute, or 2) disentangled representation learning, where each latent direction should represent a distinct semantic attribute. In this paper, we focus on a different and less studied research problem, called Contrastive Analysis (CA). Given two image datasets, we want to separate the common generative factors, shared across the two datasets, from the salient ones, specific to only one dataset. Compared to existing methods, which use attributes as supervised signals for editing (e.g., glasses, gender), the proposed method is weaker, since it only uses the dataset signal. We propose a novel framework for CA, that can be adapted to both GAN and Diffusion models, to learn both common and salient factors. By defining new and well-adapted learning strategies and losses, we ensure a relevant separation between common and salient factors, preserving a high-quality generation. We evaluate our approach on diverse datasets, covering human faces, animal images and medical scans. Our framework demonstrates superior separation ability and image quality synthesis compared to prior methods.
Unsupervised Feature Learning by Deep Sparse Coding
Dec 20, 2013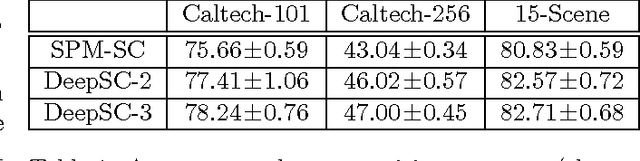
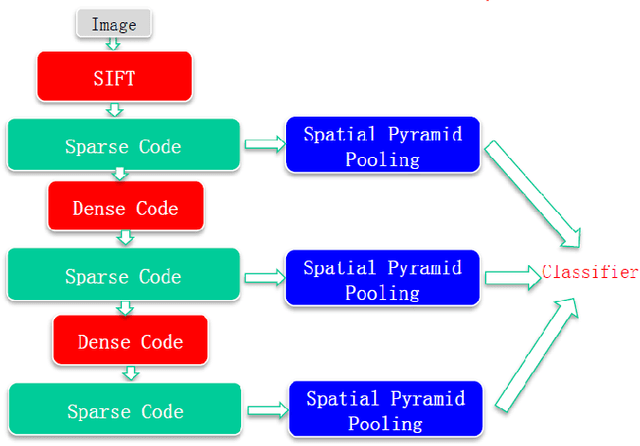
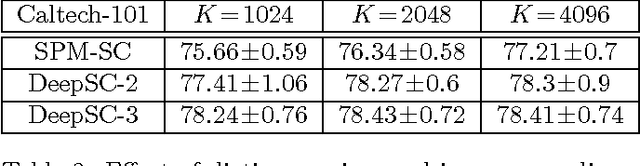

In this paper, we propose a new unsupervised feature learning framework, namely Deep Sparse Coding (DeepSC), that extends sparse coding to a multi-layer architecture for visual object recognition tasks. The main innovation of the framework is that it connects the sparse-encoders from different layers by a sparse-to-dense module. The sparse-to-dense module is a composition of a local spatial pooling step and a low-dimensional embedding process, which takes advantage of the spatial smoothness information in the image. As a result, the new method is able to learn several levels of sparse representation of the image which capture features at a variety of abstraction levels and simultaneously preserve the spatial smoothness between the neighboring image patches. Combining the feature representations from multiple layers, DeepSC achieves the state-of-the-art performance on multiple object recognition tasks.