 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video-centralised Transformer for Video Face Clustering
Mar 24, 2022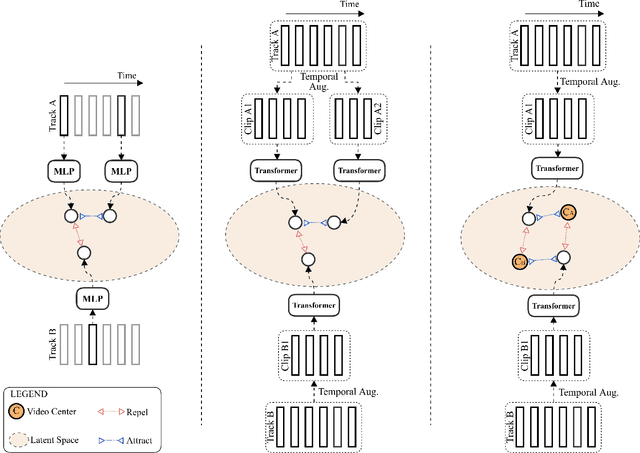

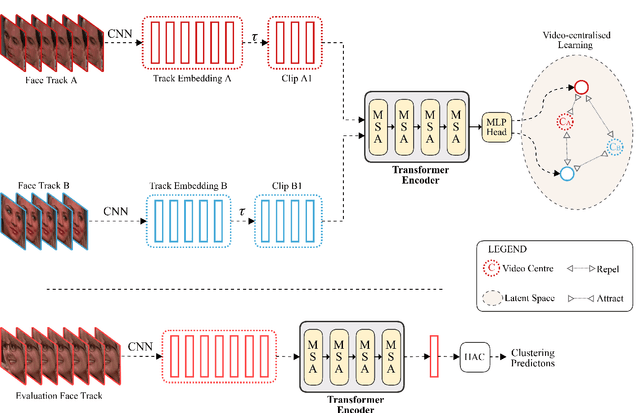
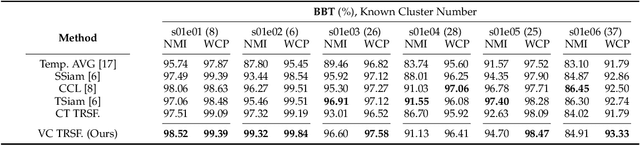
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.
Do Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022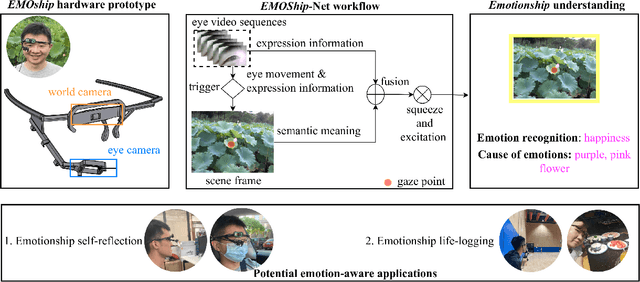

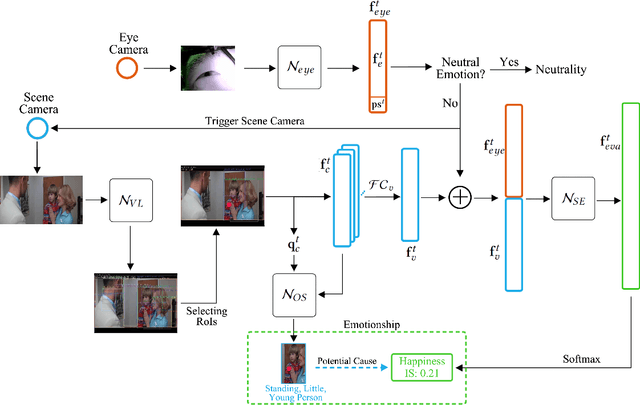
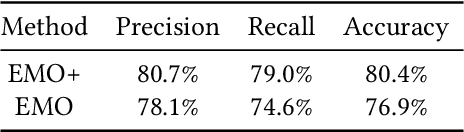
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021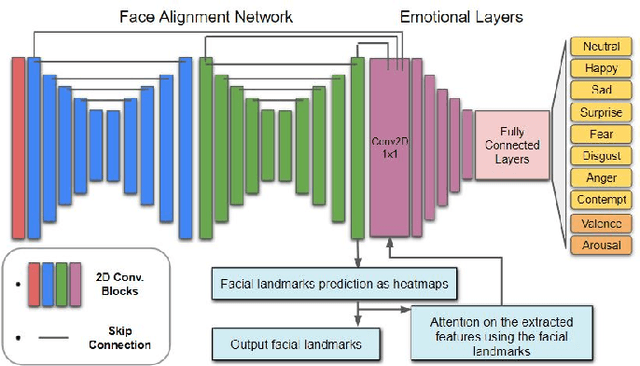
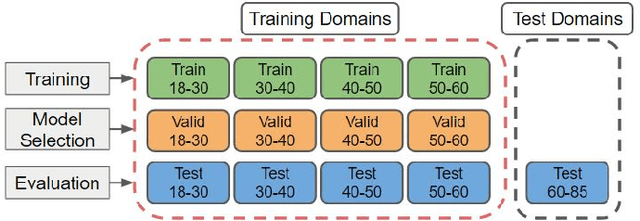
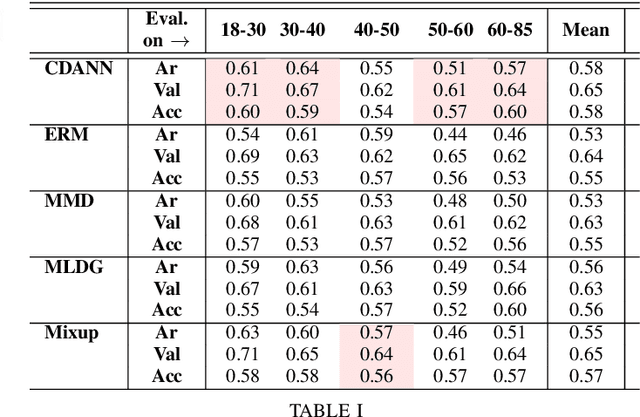
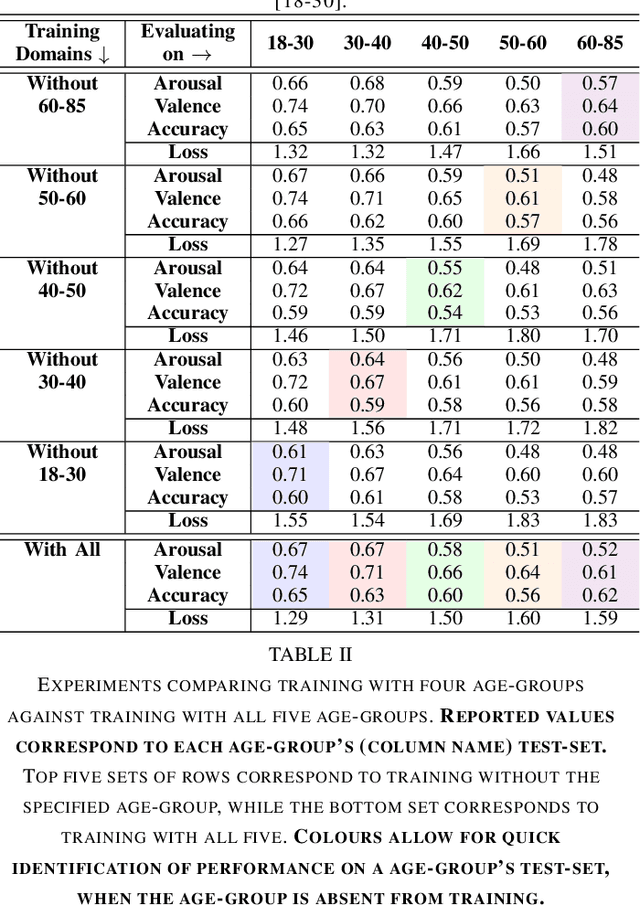
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.
FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild
Jun 21, 2021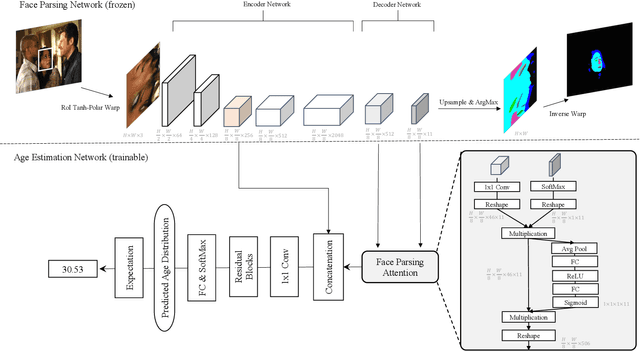
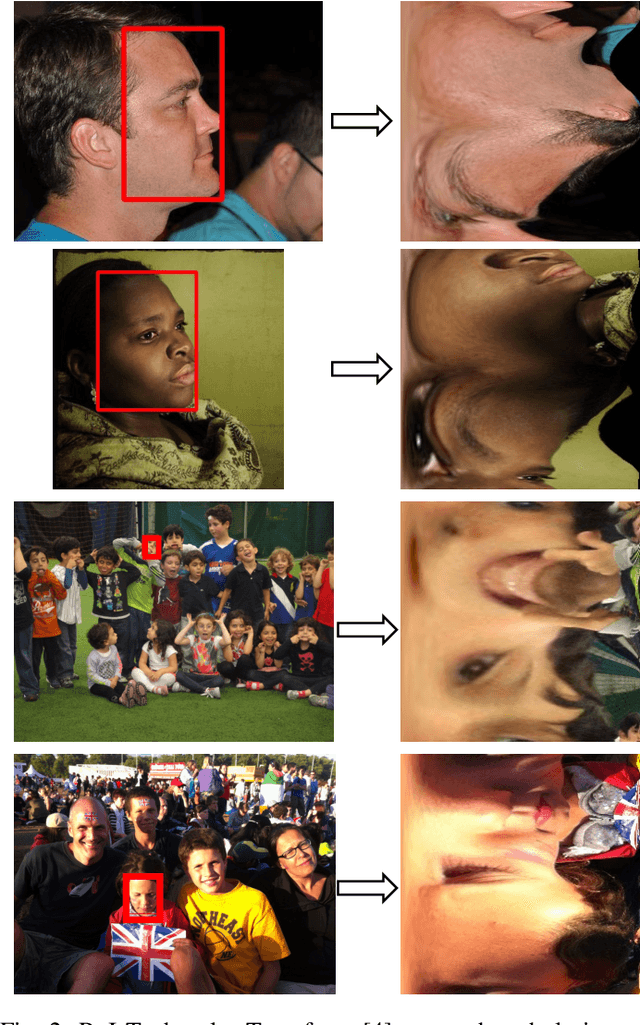

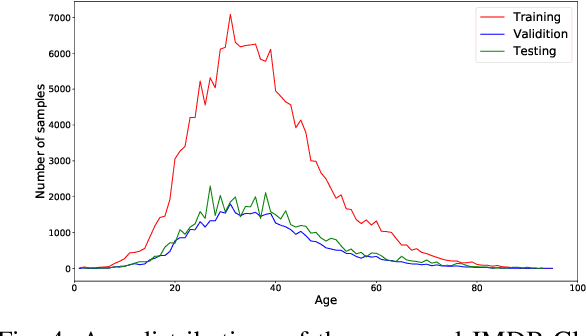
Image-based age estimation aims to predict a person's age from facial images. It is used in a variety of real-world applications. Although end-to-end deep models have achieved impressive results for age estimation on benchmark datasets, their performance in-the-wild still leaves much room for improvement due to the challenges caused by large variations in head pose, facial expressions, and occlusions. To address this issue, we propose a simple yet effective method to explicitly incorporate facial semantics into age estimation, so that the model would learn to correctly focus on the most informative facial components from unaligned facial images regardless of head pose and non-rigid deformation. To this end, we design a face parsing-based network to learn semantic information at different scales and a novel face parsing attention module to leverage these semantic features for age estimation. To evaluate our method on in-the-wild data, we also introduce a new challenging large-scale benchmark called IMDB-Clean. This dataset is created by semi-automatically cleaning the noisy IMDB-WIKI dataset using a constrained clustering method. Through comprehensive experiment on IMDB-Clean and other benchmark datasets, under both intra-dataset and cross-dataset evaluation protocols, we show that our method consistently outperforms all existing age estimation methods and achieves a new state-of-the-art performance. To the best of our knowledge, our work presents the first attempt of leveraging face parsing attention to achieve semantic-aware age estimation, which may be inspiring to other high level facial analysis tasks.
MemX: An Attention-Aware Smart Eyewear System for Personalized Moment Auto-capture
May 03, 2021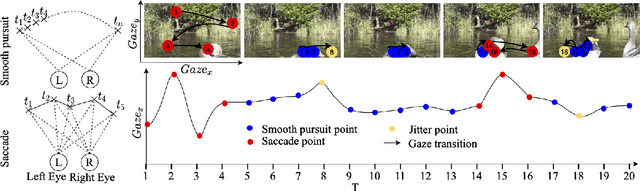

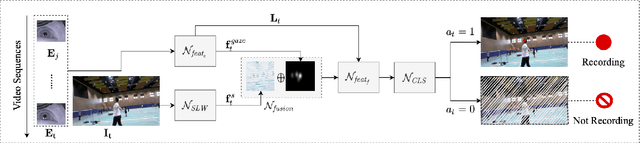
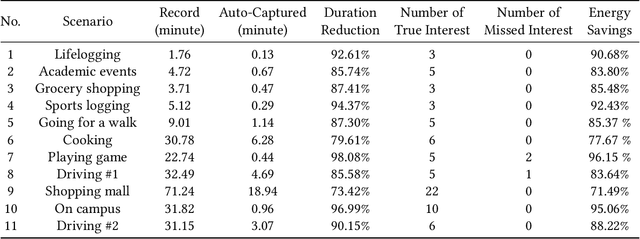
This work presents MemX: a biologically-inspired attention-aware eyewear system developed with the goal of pursuing the long-awaited vision of a personalized visual Memex. MemX captures human visual attention on the fly, analyzes the salient visual content, and records moments of personal interest in the form of compact video snippets. Accurate attentive scene detection and analysis on resource-constrained platforms is challenging because these tasks are computation and energy intensive. We propose a new temporal visual attention network that unifies human visual attention tracking and salient visual content analysis. Attention tracking focuses computation-intensive video analysis on salient regions, while video analysis makes human attention detection and tracking more accurate. Using the YouTube-VIS dataset and 30 participants, we experimentally show that MemX significantly improves the attention tracking accuracy over the eye-tracking-alone method, while maintaining high system energy efficiency. We have also conducted 11 in-field pilot studies across a range of daily usage scenarios, which demonstrate the feasibility and potential benefits of MemX.
A Reinforcement-Learning-Based Energy-Efficient Framework for Multi-Task Video Analytics Pipeline
May 02, 2021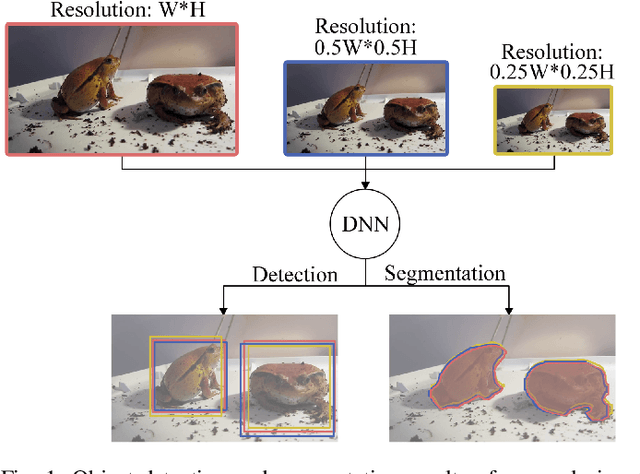
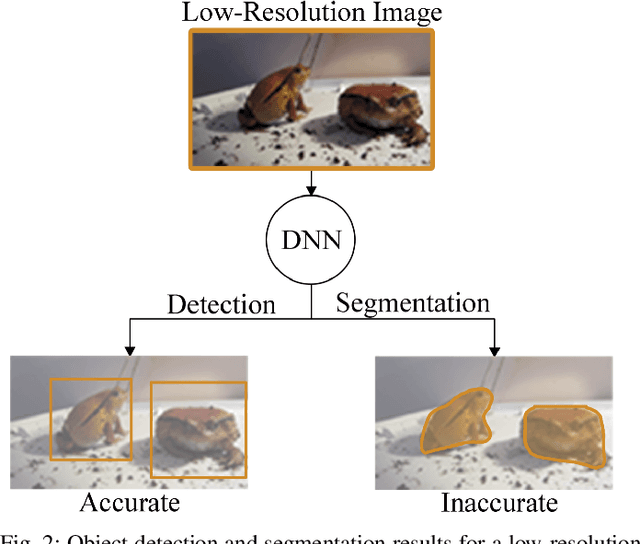
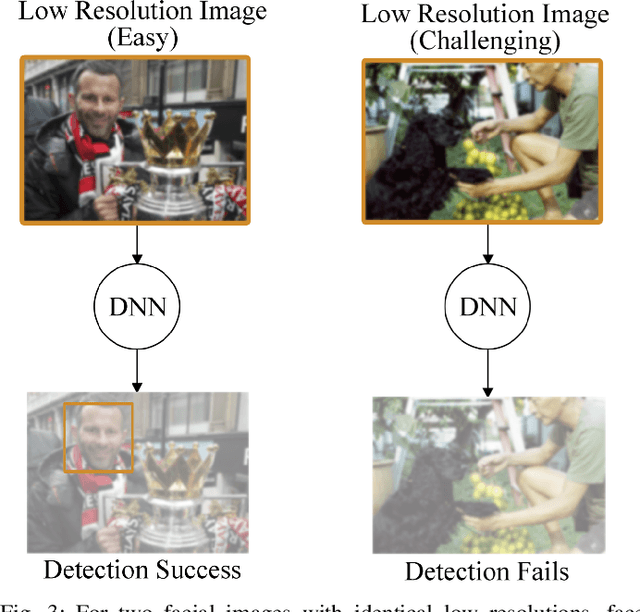
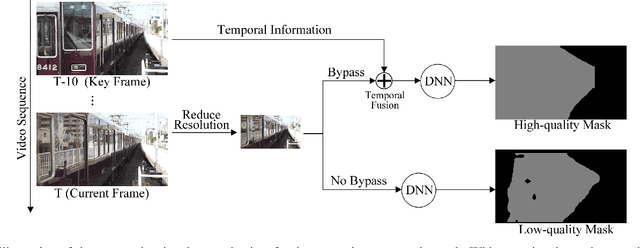
Deep-learning-based video processing has yielded transformative results in recent years. However, the video analytics pipeline is energy-intensive due to high data rates and reliance on complex inference algorithms, which limits its adoption in energy-constrained applications. Motivated by the observation of high and variable spatial redundancy and temporal dynamics in video data streams, we design and evaluate an adaptive-resolution optimization framework to minimize the energy use of multi-task video analytics pipelines. Instead of heuristically tuning the input data resolution of individual tasks, our framework utilizes deep reinforcement learning to dynamically govern the input resolution and computation of the entire video analytics pipeline. By monitoring the impact of varying resolution on the quality of high-dimensional video analytics features, hence the accuracy of video analytics results, the proposed end-to-end optimization framework learns the best non-myopic policy for dynamically controlling the resolution of input video streams to globally optimize energy efficiency. Governed by reinforcement learning, optical flow is incorporated into the framework to minimize unnecessary spatio-temporal redundancy that leads to re-computation, while preserving accuracy. The proposed framework is applied to video instance segmentation which is one of the most challenging computer vision tasks, and achieves better energy efficiency than all baseline methods of similar accuracy on the YouTube-VIS dataset.
RoI Tanh-polar Transformer Network for Face Parsing in the Wild
Feb 04, 2021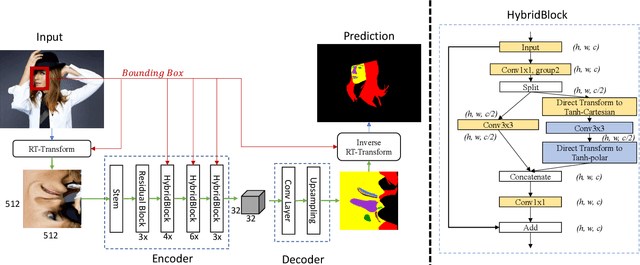


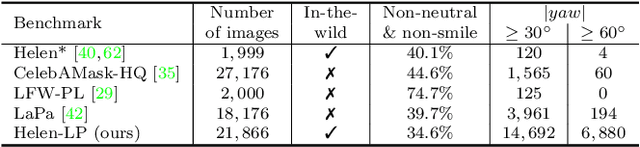
Face parsing aims to predict pixel-wise labels for facial components of a target face in an image. Existing approaches usually crop the target face from the input image with respect to a bounding box calculated during pre-processing, and thus can only parse inner facial Regions of Interest (RoIs). Peripheral regions like hair are ignored and nearby faces that are partially included in the bounding box can cause distractions. Moreover, these methods are only trained and evaluated on near-frontal portrait images and thus their performance for in-the-wild cases were unexplored. To address these issues, this paper makes three contributions. First, we introduce iBugMask dataset for face parsing in the wild containing 1,000 manually annotated images with large variations in sizes, poses, expressions and background, and Helen-LP, a large-pose training set containing 21,866 images generated using head pose augmentation. Second, we propose RoI Tanh-polar transform that warps the whole image to a Tanh-polar representation with a fixed ratio between the face area and the context, guided by the target bounding box. The new representation contains all information in the original image, and allows for rotation equivariance in the convolutional neural networks (CNNs). Third, we propose a hybrid residual representation learning block, coined HybridBlock, that contains convolutional layers in both the Tanh-polar space and the Tanh-Cartesian space, allowing for receptive fields of different shapes in CNNs. Through extensive experiments, we show that the proposed method significantly improves the state-of-the-art for face parsing in the wild.
Lip-reading with Densely Connected Temporal Convolutional Networks
Sep 29, 2020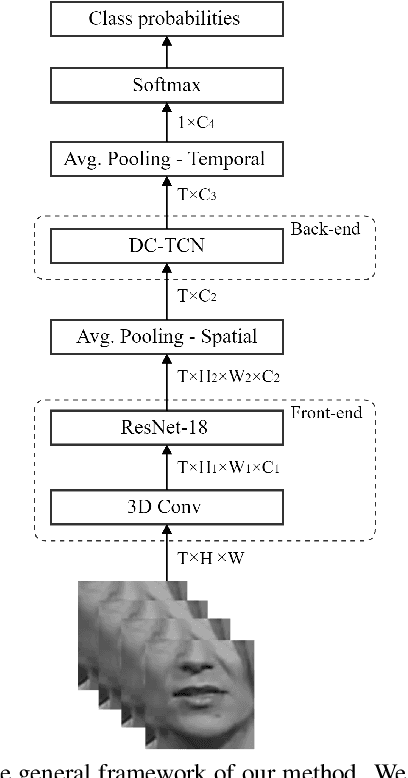
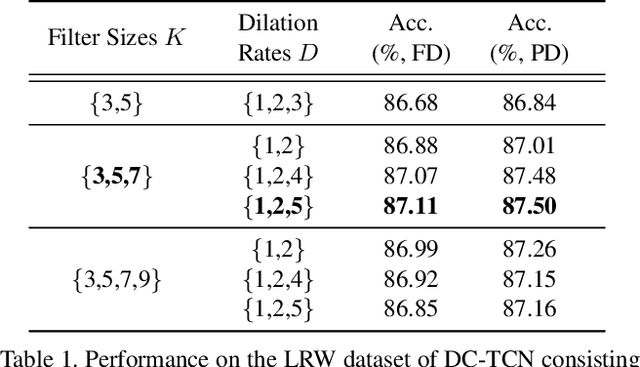
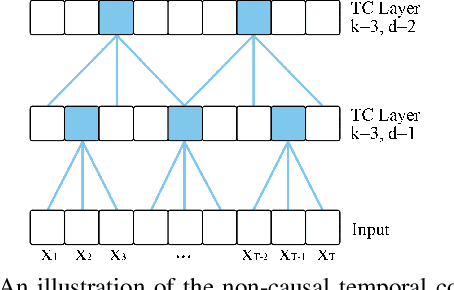
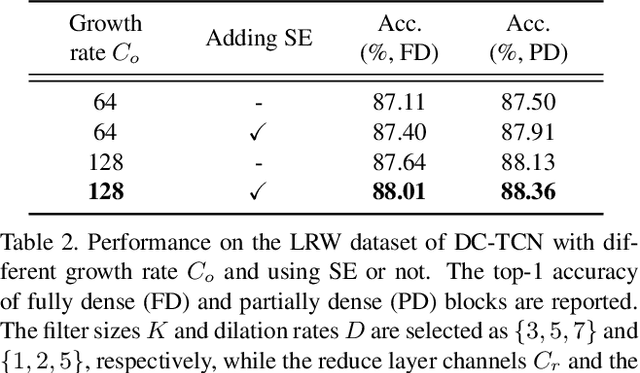
In this work, we present the Densely Connected Temporal Convolutional Network (DC-TCN) for lip-reading of isolated words. Although Temporal Convolutional Networks (TCN) have recently demonstrated great potential in many vision tasks, its receptive fields are not dense enough to model the complex temporal dynamics in lip-reading scenarios. To address this problem, we introduce dense connections into the network to capture more robust temporal features. Moreover, our approach utilises the Squeeze-and-Excitation block, a light-weight attention mechanism, to further enhance the model's classification power. Without bells and whistles, our DC-TCN method has achieved 88.36% accuracy on the Lip Reading in the Wild (LRW) dataset and 43.65% on the LRW-1000 dataset, which has surpassed all the baseline methods and is the new state-of-the-art on both datasets.
Dilated Convolutions with Lateral Inhibitions for Semantic Image Segmentation
Jun 16, 2020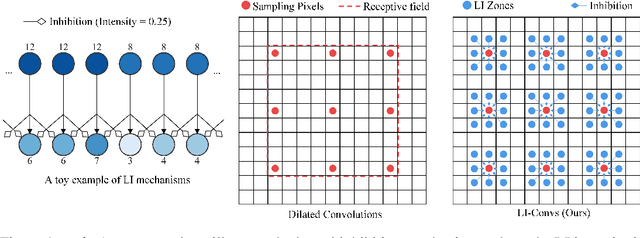
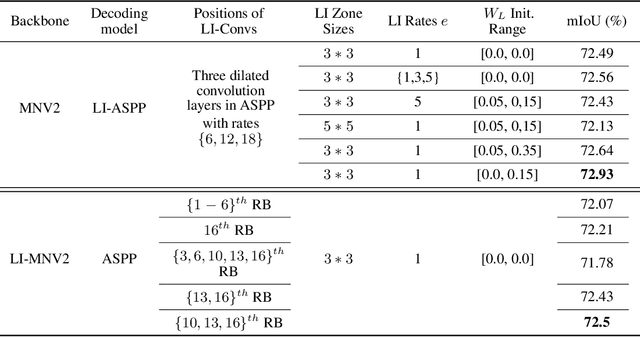

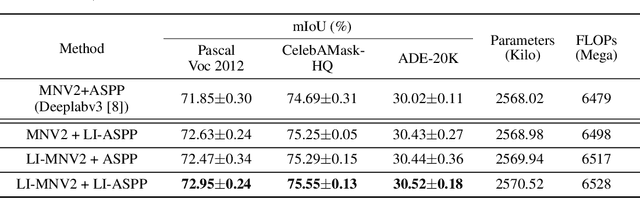
Dilated convolutions are widely used in deep semantic segmentation models as they can enlarge the filters' receptive field without adding additional weights nor sacrificing spatial resolution. However, as dilated convolutional filters do not possess positional knowledge about the pixels on semantically meaningful contours, they could lead to ambiguous predictions on object boundaries. In addition, although dilating the filter can expand its receptive field, the total number of sampled pixels remains unchanged, which usually comprises a small fraction of the receptive field's total area. Inspired by the Lateral Inhibition (LI) mechanisms in human visual systems, we propose the dilated convolution with lateral inhibitions (LI-Convs) to overcome these limitations. Introducing LI mechanisms improves the convolutional filter's sensitivity to semantic object boundaries. Moreover, since LI-Convs also implicitly take the pixels from the laterally inhibited zones into consideration, they can also extract features at a denser scale. By integrating LI-Convs into the Deeplabv3+ architecture, we propose the Lateral Inhibited Atrous Spatial Pyramid Pooling (LI-ASPP) and the Lateral Inhibited MobileNet-V2 (LI-MNV2). Experimental results on three benchmark datasets (PASCAL VOC 2012, CelebAMask-HQ and ADE20K) show that our LI-based segmentation models outperform the baseline on all of them, thus verify the effectiveness and generality of the proposed LI-Convs.
Shape Constrained Network for Eye Segmentation in the Wild
Oct 11, 2019

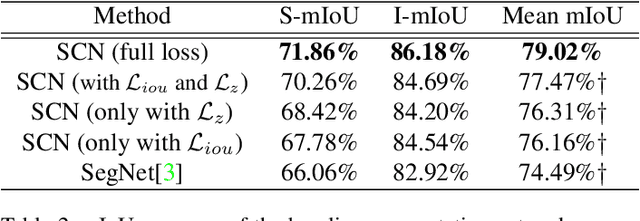
Semantic segmentation of eyes has long been a vital pre-processing step in many biometric applications. Majority of the works focus only on high resolution eye images, while little has been done to segment the eyes from low quality images in the wild. However, this is a particularly interesting and meaningful topic, as eyes play a crucial role in conveying the emotional state and mental well-being of a person. In this work, we take two steps toward solving this problem: (1) We collect and annotate a challenging eye segmentation dataset containing 8882 eye patches from 4461 facial images of different resolutions, illumination conditions and head poses; (2) We develop a novel eye segmentation method, Shape Constrained Network (SCN), that incorporates shape prior into the segmentation network training procedure. Specifically, we learn the shape prior from our dataset using VAE-GAN, and leverage the pre-trained encoder and discriminator to regularise the training of SegNet. To improve the accuracy and quality of predicted masks, we replace the loss of SegNet with three new losses: Intersection-over-Union (IoU) loss, shape discriminator loss and shape embedding loss. Extensive experiments shows that our method outperforms state-of-the-art segmentation and landmark detection methods in terms of mean IoU (mIoU) accuracy and the quality of segmentation masks. The eye segmentation database is available at https://www.dropbox.com/s/yvveouvxsvti08x/Eye_Segmentation_Database.zip?dl=0.