 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Pseudo-Labeling with Reinforcement Learning for Semi-Supervised Domain Adaptation
Dec 07, 2020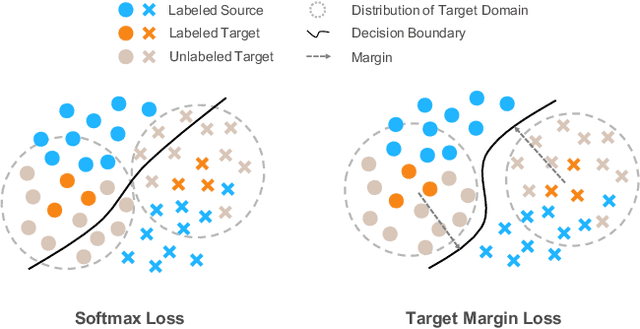
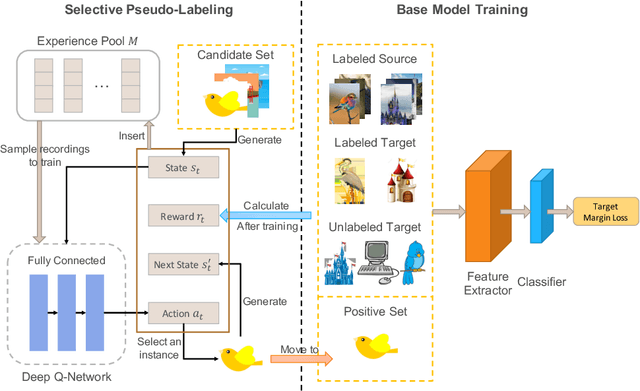
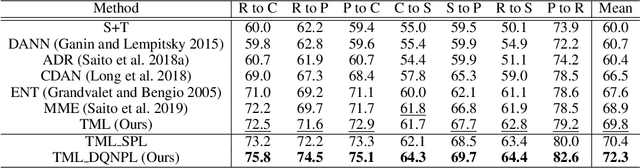
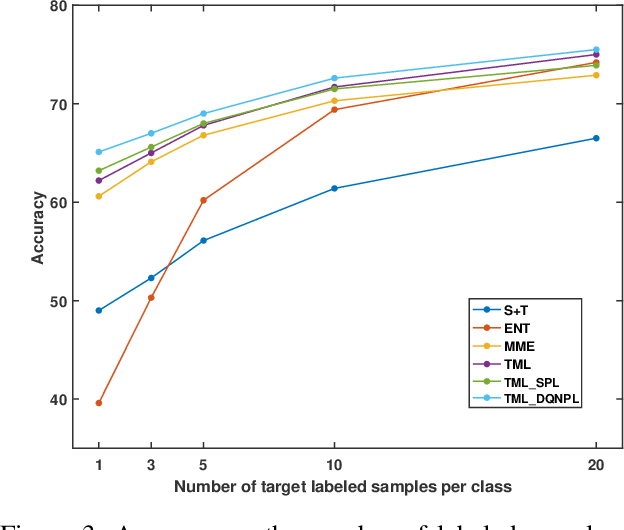
Recent domain adaptation methods have demonstrated impressive improvement on unsupervised domain adaptation problems. However, in the semi-supervised domain adaptation (SSDA) setting where the target domain has a few labeled instances available, these methods can fail to improve performance. Inspired by the effectiveness of pseudo-labels in domain adaptation, we propose a reinforcement learning based selective pseudo-labeling method for semi-supervised domain adaptation. It is difficult for conventional pseudo-labeling methods to balance the correctness and representativeness of pseudo-labeled data. To address this limitation, we develop a deep Q-learning model to select both accurate and representative pseudo-labeled instances. Moreover, motivated by large margin loss's capacity on learning discriminative features with little data, we further propose a novel target margin loss for our base model training to improve its discriminability. Our proposed method is evaluated on several benchmark datasets for SSDA, and demonstrates superior performance to all the comparison methods.
Domain Adaptation with Incomplete Target Domains
Dec 03, 2020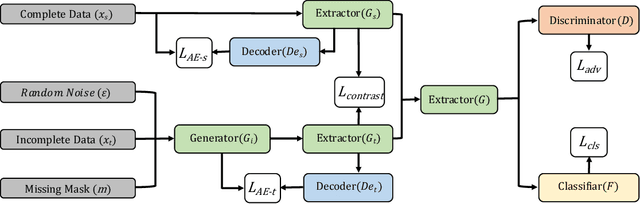
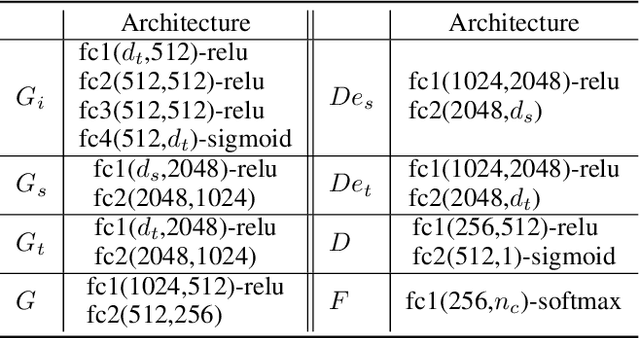
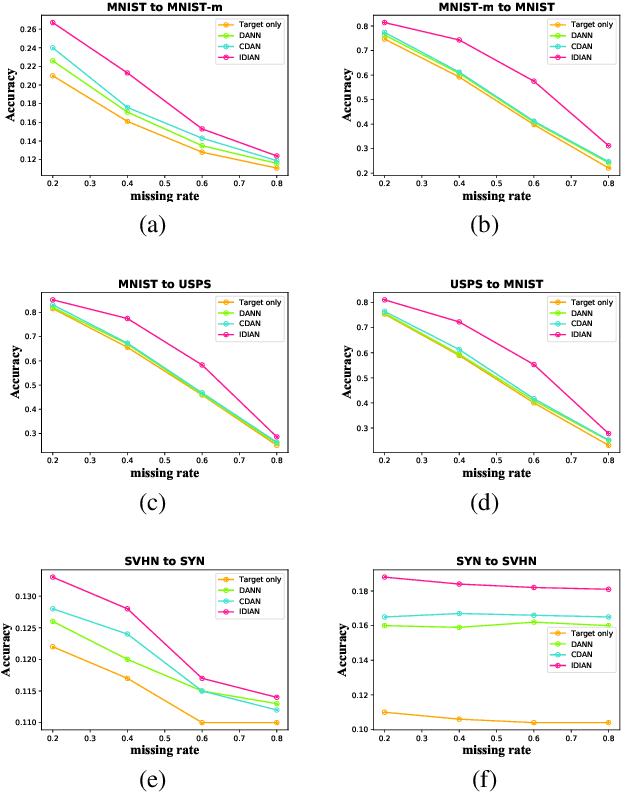

Domain adaptation, as a task of reducing the annotation cost in a target domain by exploiting the existing labeled data in an auxiliary source domain, has received a lot of attention in the research community. However, the standard domain adaptation has assumed perfectly observed data in both domains, while in real world applications the existence of missing data can be prevalent. In this paper, we tackle a more challenging domain adaptation scenario where one has an incomplete target domain with partially observed data. We propose an Incomplete Data Imputation based Adversarial Network (IDIAN) model to address this new domain adaptation challenge. In the proposed model, we design a data imputation module to fill the missing feature values based on the partial observations in the target domain, while aligning the two domains via deep adversarial adaption. We conduct experiments on both cross-domain benchmark tasks and a real world adaptation task with imperfect target domains. The experimental results demonstrate the effectiveness of the proposed method.
Bi-Dimensional Feature Alignment for Cross-Domain Object Detection
Nov 14, 2020
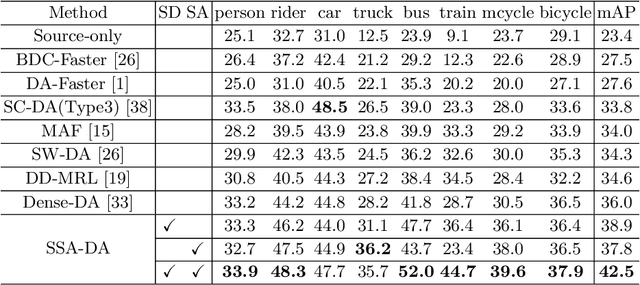
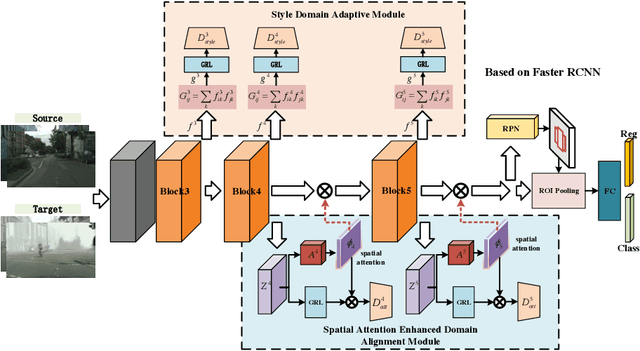
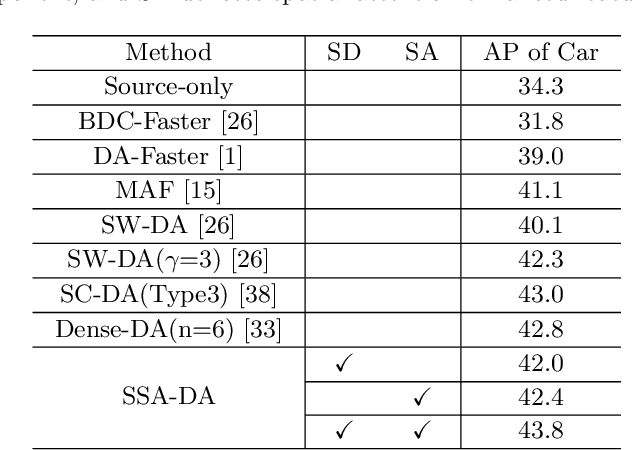
Recently the problem of cross-domain object detection has started drawing attention in the computer vision community. In this paper, we propose a novel unsupervised cross-domain detection model that exploits the annotated data in a source domain to train an object detector for a different target domain. The proposed model mitigates the cross-domain representation divergence for object detection by performing cross-domain feature alignment in two dimensions, the depth dimension and the spatial dimension. In the depth dimension of channel layers, it uses inter-channel information to bridge the domain divergence with respect to image style alignment. In the dimension of spatial layers, it deploys spatial attention modules to enhance detection relevant regions and suppress irrelevant regions with respect to cross-domain feature alignment. Experiments are conducted on a number of benchmark cross-domain detection datasets. The empirical results show the proposed method outperforms the state-of-the-art comparison methods.
Ensemble Model with Batch Spectral Regularization and Data Blending for Cross-Domain Few-Shot Learning with Unlabeled Data
Jun 09, 2020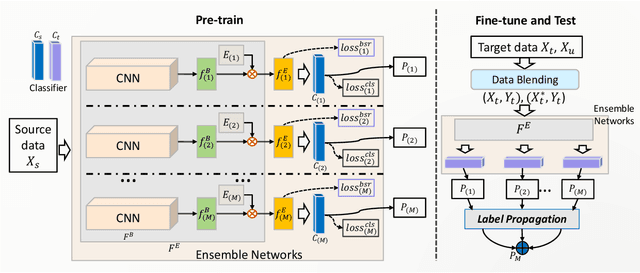
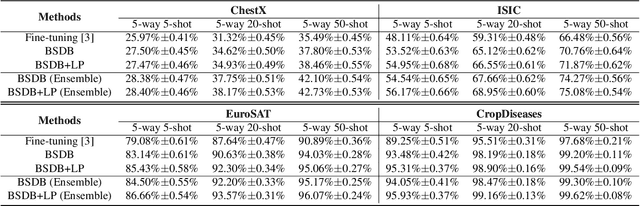
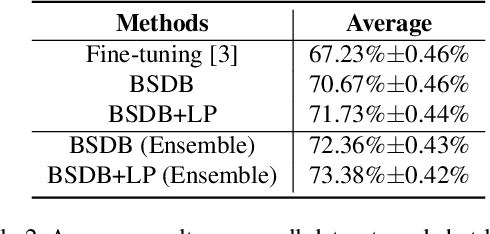
In this paper, we present our proposed ensemble model with batch spectral regularization and data blending mechanisms for the Track 2 problem of the cross-domain few-shot learning (CD-FSL) challenge. We build a multi-branch ensemble framework by using diverse feature transformation matrices, while deploying batch spectral feature regularization on each branch to improve the model's transferability. Moreover, we propose a data blending method to exploit the unlabeled data and augment the sparse support set in the target domain. Our proposed model demonstrates effective performance on the CD-FSL benchmark tasks.
A Transductive Multi-Head Model for Cross-Domain Few-Shot Learning
Jun 08, 2020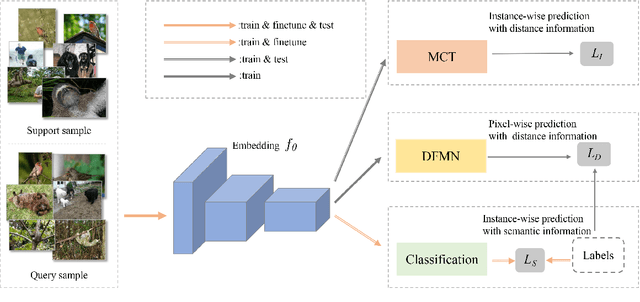
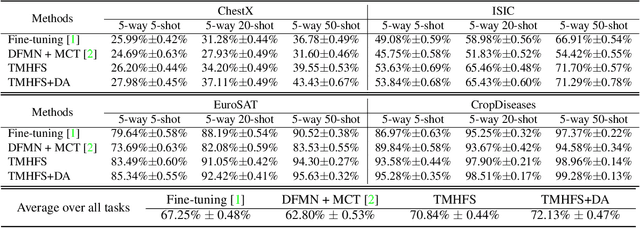
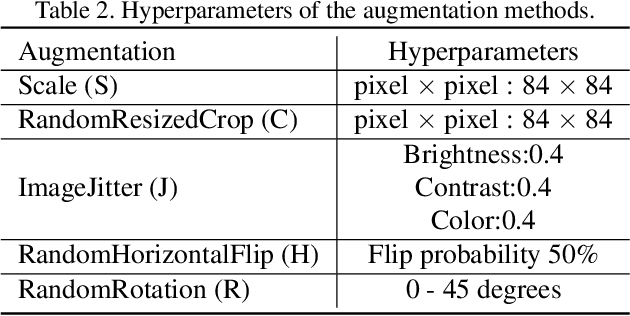
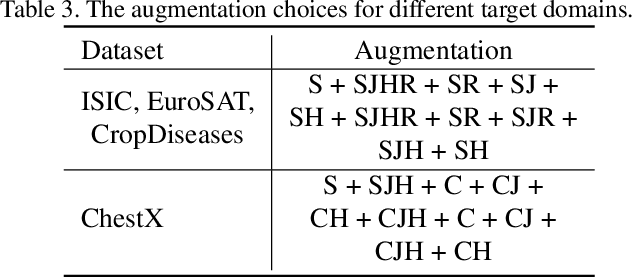
In this paper, we present a new method, Transductive Multi-Head Few-Shot learning (TMHFS), to address the Cross-Domain Few-Shot Learning (CD-FSL) challenge. The TMHFS method extends the Meta-Confidence Transduction (MCT) and Dense Feature-Matching Networks (DFMN) method [2] by introducing a new prediction head, i.e, an instance-wise global classification network based on semantic information, after the common feature embedding network. We train the embedding network with the multiple heads, i.e,, the MCT loss, the DFMN loss and the semantic classifier loss, simultaneously in the source domain. For the few-shot learning in the target domain, we first perform fine-tuning on the embedding network with only the semantic global classifier and the support instances, and then use the MCT part to predict labels of the query set with the fine-tuned embedding network. Moreover, we further exploit data augmentation techniques during the fine-tuning and test stages to improve the prediction performance. The experimental results demonstrate that the proposed methods greatly outperform the strong baseline, fine-tuning, on four different target domains.
Feature Transformation Ensemble Model with Batch Spectral Regularization for Cross-Domain Few-Shot Classification
May 21, 2020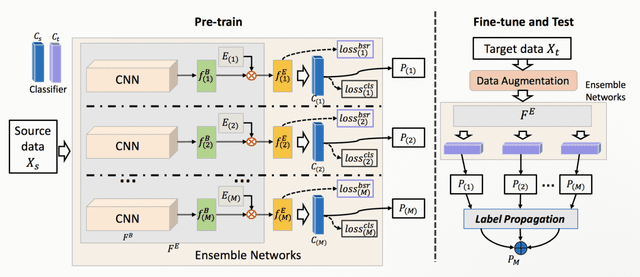
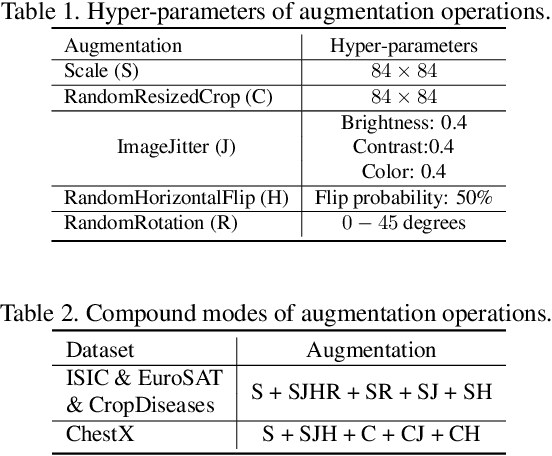
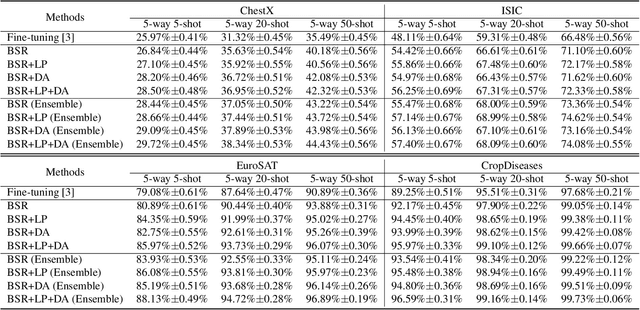
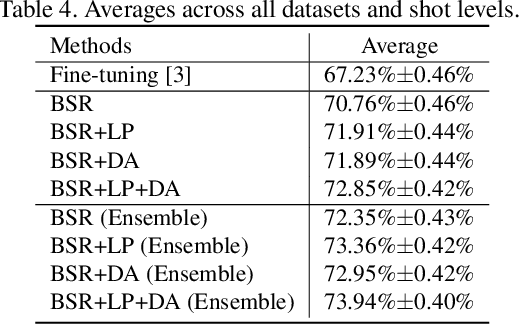
In this paper, we propose a feature transformation ensemble model with batch spectral regularization for the Cross-domain few-shot learning (CD-FSL) challenge. Specifically, we proposes to construct an ensemble prediction model by performing diverse feature transformations after a feature extraction network. On each branch prediction network of the model we use a batch spectral regularization term to suppress the singular values of the feature matrix during pre-training to improve the generalization ability of the model. The proposed model can then be fine tuned in the target domain to address few-shot classification. We also further apply label propagation, entropy minimization and data augmentation to mitigate the shortage of labeled data in target domains. Experiments are conducted on a number of CD-FSL benchmark tasks with four target domains and the results demonstrate the superiority of our proposed model.
Multi-Level Generative Models for Partial Label Learning with Non-random Label Noise
May 11, 2020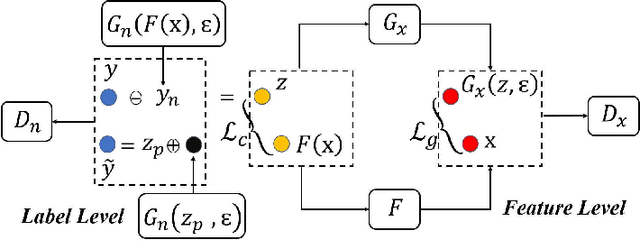
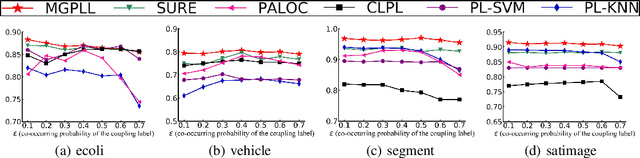
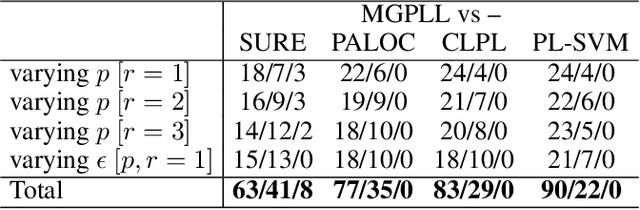
Partial label (PL) learning tackles the problem where each training instance is associated with a set of candidate labels that include both the true label and irrelevant noise labels. In this paper, we propose a novel multi-level generative model for partial label learning (MGPLL), which tackles the problem by learning both a label level adversarial generator and a feature level adversarial generator under a bi-directional mapping framework between the label vectors and the data samples. Specifically, MGPLL uses a conditional noise label generation network to model the non-random noise labels and perform label denoising, and uses a multi-class predictor to map the training instances to the denoised label vectors, while a conditional data feature generator is used to form an inverse mapping from the denoised label vectors to data samples. Both the noise label generator and the data feature generator are learned in an adversarial manner to match the observed candidate labels and data features respectively. Extensive experiments are conducted on synthesized and real-world partial label datasets. The proposed approach demonstrates the state-of-the-art performance for partial label learning.
Unsupervised Domain Adaptation with Progressive Domain Augmentation
Apr 24, 2020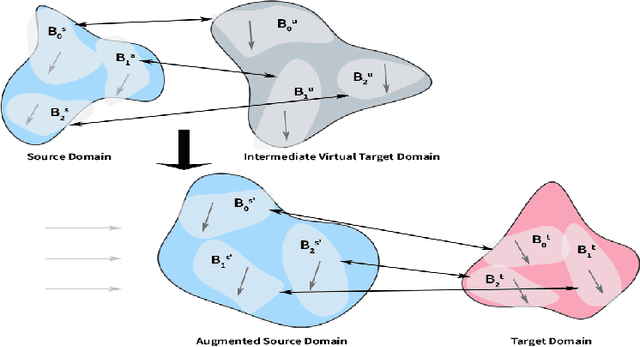
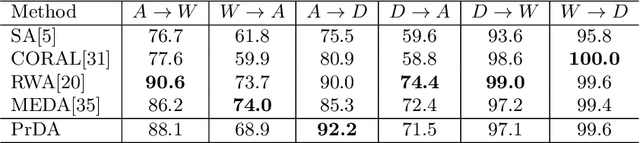


Domain adaptation aims to exploit a label-rich source domain for learning classifiers in a different label-scarce target domain. It is particularly challenging when there are significant divergences between the two domains. In the paper, we propose a novel unsupervised domain adaptation method based on progressive domain augmentation. The proposed method generates virtual intermediate domains via domain interpolation, progressively augments the source domain and bridges the source-target domain divergence by conducting multiple subspace alignment on the Grassmann manifold. We conduct experiments on multiple domain adaptation tasks and the results shows the proposed method achieves the state-of-the-art performance.
Mutual Learning Network for Multi-Source Domain Adaptation
Mar 29, 2020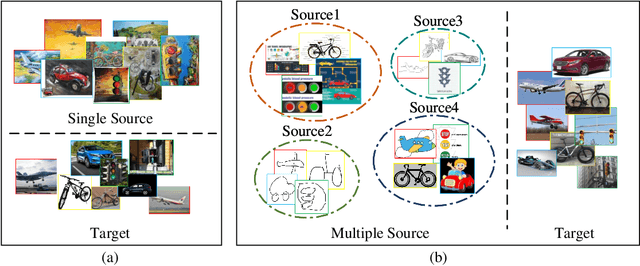
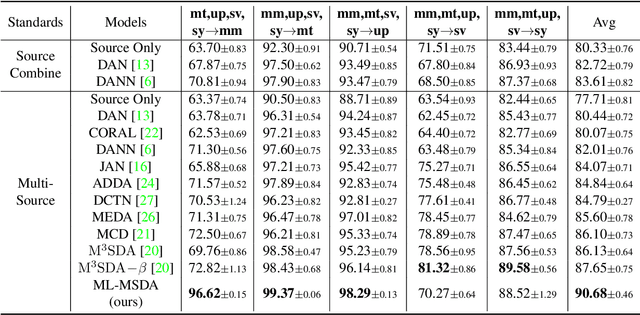
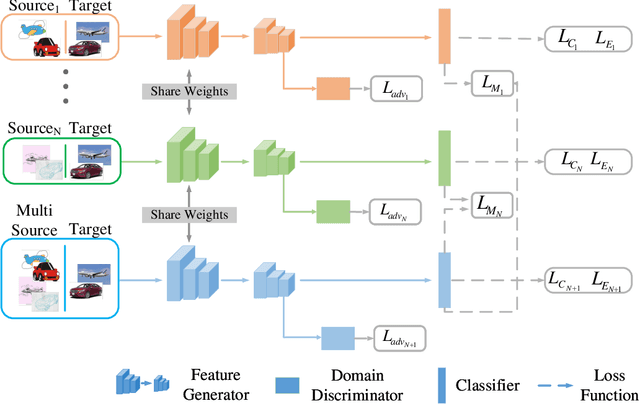
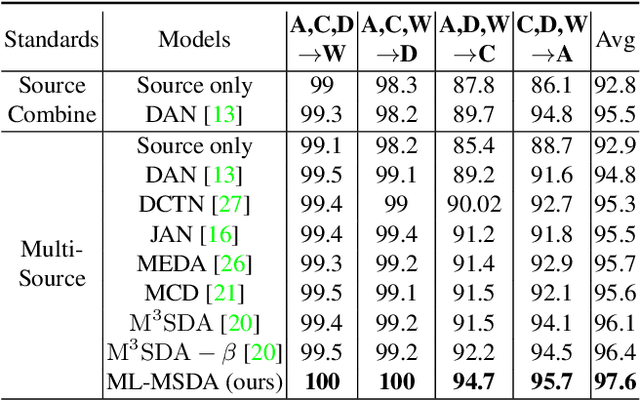
Early Unsupervised Domain Adaptation (UDA) methods have mostly assumed the setting of a single source domain, where all the labeled source data come from the same distribution. However, in practice the labeled data can come from multiple source domains with different distributions. In such scenarios, the single source domain adaptation methods can fail due to the existence of domain shifts across different source domains and multi-source domain adaptation methods need to be designed. In this paper, we propose a novel multi-source domain adaptation method, Mutual Learning Network for Multiple Source Domain Adaptation (ML-MSDA). Under the framework of mutual learning, the proposed method pairs the target domain with each single source domain to train a conditional adversarial domain adaptation network as a branch network, while taking the pair of the combined multi-source domain and target domain to train a conditional adversarial adaptive network as the guidance network. The multiple branch networks are aligned with the guidance network to achieve mutual learning by enforcing JS-divergence regularization over their prediction probability distributions on the corresponding target data. We conduct extensive experiments on multiple multi-source domain adaptation benchmark datasets. The results show the proposed ML-MSDA method outperforms the comparison methods and achieves the state-of-the-art performance.
Adaptive Object Detection with Dual Multi-Label Prediction
Mar 29, 2020
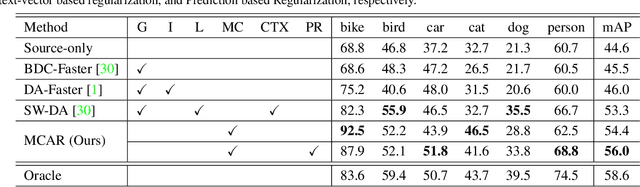
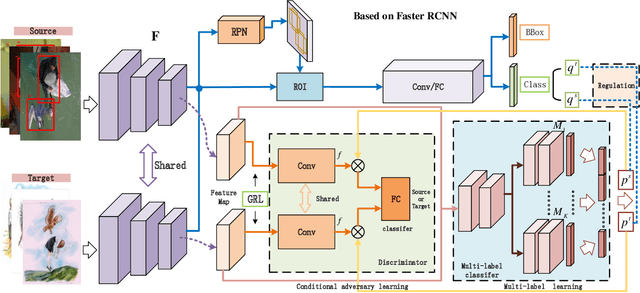
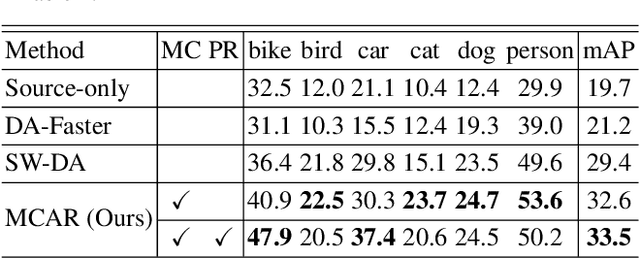
In this paper, we propose a novel end-to-end unsupervised deep domain adaptation model for adaptive object detection by exploiting multi-label object recognition as a dual auxiliary task. The model exploits multi-label prediction to reveal the object category information in each image and then uses the prediction results to perform conditional adversarial global feature alignment, such that the multi-modal structure of image features can be tackled to bridge the domain divergence at the global feature level while preserving the discriminability of the features. Moreover, we introduce a prediction consistency regularization mechanism to assist object detection, which uses the multi-label prediction results as an auxiliary regularization information to ensure consistent object category discoveries between the object recognition task and the object detection task. Experiments are conducted on a few benchmark datasets and the results show the proposed model outperforms the state-of-the-art comparison methods.