 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Subset Sum Matching Problem
Aug 26, 2025



This paper presents a new combinatorial optimisation task, the Subset Sum Matching Problem (SSMP), which is an abstraction of common financial applications such as trades reconciliation. We present three algorithms, two suboptimal and one optimal, to solve this problem. We also generate a benchmark to cover different instances of SSMP varying in complexity, and carry out an experimental evaluation to assess the performance of the approaches.
LENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
May 21, 2025Multimodal Large Language Models (MLLMs) have achieved significant advances in integrating visual and linguistic information, yet their ability to reason about complex and real-world scenarios remains limited. The existing benchmarks are usually constructed in the task-oriented manner without guarantee that different task samples come from the same data distribution, thus they often fall short in evaluating the synergistic effects of lower-level perceptual capabilities on higher-order reasoning. To lift this limitation, we contribute Lens, a multi-level benchmark with 3.4K contemporary images and 60K+ human-authored questions covering eight tasks and 12 daily scenarios, forming three progressive task tiers, i.e., perception, understanding, and reasoning. One feature is that each image is equipped with rich annotations for all tasks. Thus, this dataset intrinsically supports to evaluate MLLMs to handle image-invariable prompts, from basic perception to compositional reasoning. In addition, our images are manully collected from the social media, in which 53% were published later than Jan. 2025. We evaluate 15+ frontier MLLMs such as Qwen2.5-VL-72B, InternVL3-78B, GPT-4o and two reasoning models QVQ-72B-preview and Kimi-VL. These models are released later than Dec. 2024, and none of them achieve an accuracy greater than 60% in the reasoning tasks. Project page: https://github.com/Lens4MLLMs/lens. ICCV 2025 workshop page: https://lens4mllms.github.io/mars2-workshop-iccv2025/
Testing and Improving the Robustness of Amortized Bayesian Inference for Cognitive Models
Dec 29, 2024Contaminant observations and outliers often cause problems when estimating the parameters of cognitive models, which are statistical models representing cognitive processes. In this study, we test and improve the robustness of parameter estimation using amortized Bayesian inference (ABI) with neural networks. To this end, we conduct systematic analyses on a toy example and analyze both synthetic and real data using a popular cognitive model, the Drift Diffusion Models (DDM). First, we study the sensitivity of ABI to contaminants with tools from robust statistics: the empirical influence function and the breakdown point. Next, we propose a data augmentation or noise injection approach that incorporates a contamination distribution into the data-generating process during training. We examine several candidate distributions and evaluate their performance and cost in terms of accuracy and efficiency loss relative to a standard estimator. Introducing contaminants from a Cauchy distribution during training considerably increases the robustness of the neural density estimator as measured by bounded influence functions and a much higher breakdown point. Overall, the proposed method is straightforward and practical to implement and has a broad applicability in fields where outlier detection or removal is challenging.
Abstract Visual Reasoning: An Algebraic Approach for Solving Raven's Progressive Matrices
Mar 21, 2023



We introduce algebraic machine reasoning, a new reasoning framework that is well-suited for abstract reasoning. Effectively, algebraic machine reasoning reduces the difficult process of novel problem-solving to routine algebraic computation. The fundamental algebraic objects of interest are the ideals of some suitably initialized polynomial ring. We shall explain how solving Raven's Progressive Matrices (RPMs) can be realized as computational problems in algebra, which combine various well-known algebraic subroutines that include: Computing the Gr\"obner basis of an ideal, checking for ideal containment, etc. Crucially, the additional algebraic structure satisfied by ideals allows for more operations on ideals beyond set-theoretic operations. Our algebraic machine reasoning framework is not only able to select the correct answer from a given answer set, but also able to generate the correct answer with only the question matrix given. Experiments on the I-RAVEN dataset yield an overall $93.2\%$ accuracy, which significantly outperforms the current state-of-the-art accuracy of $77.0\%$ and exceeds human performance at $84.4\%$ accuracy.
How Robust are Limit Order Book Representations under Data Perturbation?
Oct 10, 2021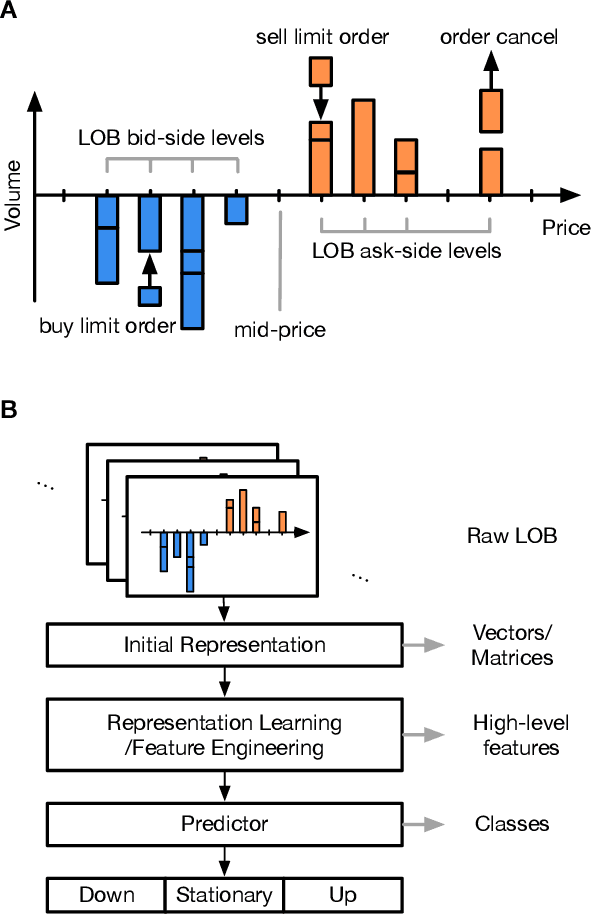
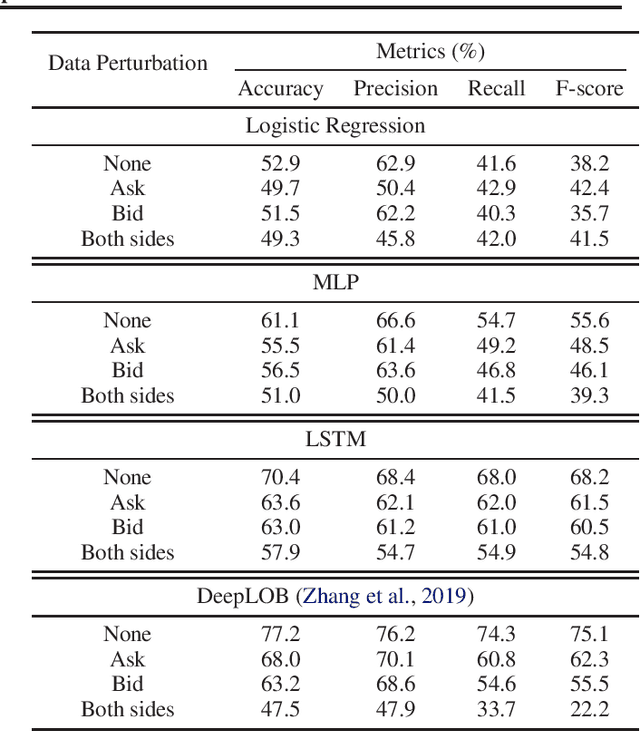
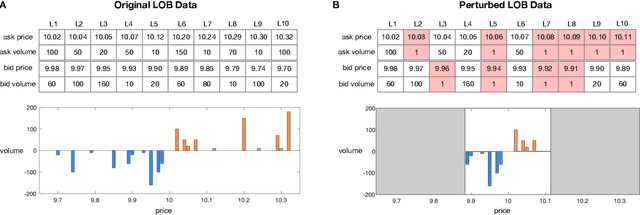
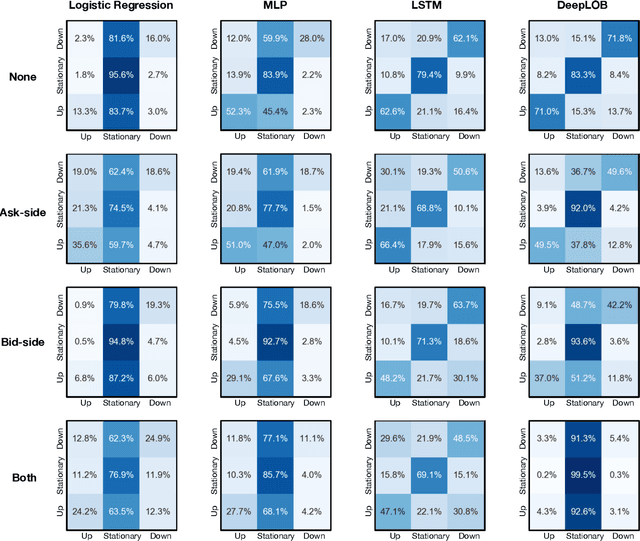
The success of machine learning models in the financial domain is highly reliant on the quality of the data representation. In this paper, we focus on the representation of limit order book data and discuss the opportunities and challenges for learning representations of such data. We also experimentally analyse the issues associated with existing representations and present a guideline for future research in this area.