 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Preconditioning in Overparameterized Low-Rank Matrix Sensing
Feb 02, 2023



We propose $\textsf{ScaledGD($\lambda$)}$, a preconditioned gradient descent method to tackle the low-rank matrix sensing problem when the true rank is unknown, and when the matrix is possibly ill-conditioned. Using overparametrized factor representations, $\textsf{ScaledGD($\lambda$)}$ starts from a small random initialization, and proceeds by gradient descent with a specific form of damped preconditioning to combat bad curvatures induced by overparameterization and ill-conditioning. At the expense of light computational overhead incurred by preconditioners, $\textsf{ScaledGD($\lambda$)}$ is remarkably robust to ill-conditioning compared to vanilla gradient descent ($\textsf{GD}$) even with overprameterization. Specifically, we show that, under the Gaussian design, $\textsf{ScaledGD($\lambda$)}$ converges to the true low-rank matrix at a constant linear rate after a small number of iterations that scales only logarithmically with respect to the condition number and the problem dimension. This significantly improves over the convergence rate of vanilla $\textsf{GD}$ which suffers from a polynomial dependency on the condition number. Our work provides evidence on the power of preconditioning in accelerating the convergence without hurting generalization in overparameterized learning.
Fast Computation of Optimal Transport via Entropy-Regularized Extragradient Methods
Jan 30, 2023Efficient computation of the optimal transport distance between two distributions serves as an algorithm subroutine that empowers various applications. This paper develops a scalable first-order optimization-based method that computes optimal transport to within $\varepsilon$ additive accuracy with runtime $\widetilde{O}( n^2/\varepsilon)$, where $n$ denotes the dimension of the probability distributions of interest. Our algorithm achieves the state-of-the-art computational guarantees among all first-order methods, while exhibiting favorable numerical performance compared to classical algorithms like Sinkhorn and Greenkhorn. Underlying our algorithm designs are two key elements: (a) converting the original problem into a bilinear minimax problem over probability distributions; (b) exploiting the extragradient idea -- in conjunction with entropy regularization and adaptive learning rates -- to accelerate convergence.
Deep Unfolded Tensor Robust PCA with Self-supervised Learning
Dec 21, 2022Tensor robust principal component analysis (RPCA), which seeks to separate a low-rank tensor from its sparse corruptions, has been crucial in data science and machine learning where tensor structures are becoming more prevalent. While powerful, existing tensor RPCA algorithms can be difficult to use in practice, as their performance can be sensitive to the choice of additional hyperparameters, which are not straightforward to tune. In this paper, we describe a fast and simple self-supervised model for tensor RPCA using deep unfolding by only learning four hyperparameters. Despite its simplicity, our model expunges the need for ground truth labels while maintaining competitive or even greater performance compared to supervised deep unfolding. Furthermore, our model is capable of operating in extreme data-starved scenarios. We demonstrate these claims on a mix of synthetic data and real-world tasks, comparing performance against previously studied supervised deep unfolding methods and Bayesian optimization baselines.
Asynchronous Gradient Play in Zero-Sum Multi-agent Games
Nov 16, 2022


Finding equilibria via gradient play in competitive multi-agent games has been attracting a growing amount of attention in recent years, with emphasis on designing efficient strategies where the agents operate in a decentralized and symmetric manner with guaranteed convergence. While significant efforts have been made in understanding zero-sum two-player matrix games, the performance in zero-sum multi-agent games remains inadequately explored, especially in the presence of delayed feedbacks, leaving the scalability and resiliency of gradient play open to questions. In this paper, we make progress by studying asynchronous gradient plays in zero-sum polymatrix games under delayed feedbacks. We first establish that the last iterate of entropy-regularized optimistic multiplicative weight updates (OMWU) method converges linearly to the quantal response equilibrium (QRE), the solution concept under bounded rationality, in the absence of delays. While the linear convergence continues to hold even when the feedbacks are randomly delayed under mild statistical assumptions, it converges at a noticeably slower rate due to a smaller tolerable range of learning rates. Moving beyond, we demonstrate entropy-regularized OMWU -- by adopting two-timescale learning rates in a delay-aware manner -- enjoys faster last-iterate convergence under fixed delays, and continues to converge provably even when the delays are arbitrarily bounded in an average-iterate manner. Our methods also lead to finite-time guarantees to approximate the Nash equilibrium (NE) by moderating the amount of regularization. To the best of our knowledge, this work is the first that aims to understand asynchronous gradient play in zero-sum polymatrix games under a wide range of delay assumptions, highlighting the role of learning rates separation.
Faster Last-iterate Convergence of Policy Optimization in Zero-Sum Markov Games
Oct 04, 2022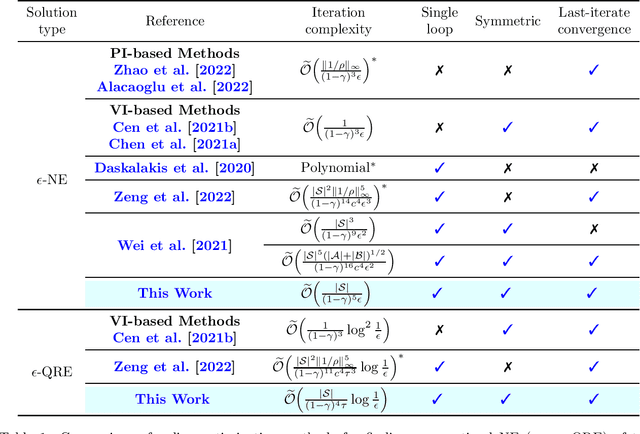
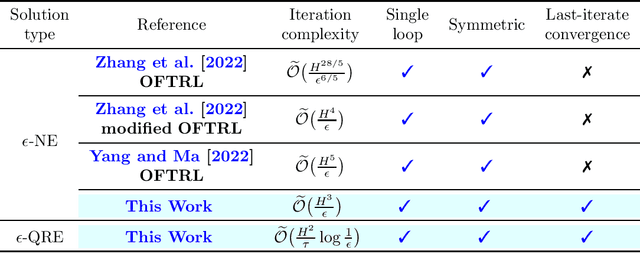
Multi-Agent Reinforcement Learning (MARL) -- where multiple agents learn to interact in a shared dynamic environment -- permeates across a wide range of critical applications. While there has been substantial progress on understanding the global convergence of policy optimization methods in single-agent RL, designing and analysis of efficient policy optimization algorithms in the MARL setting present significant challenges, which unfortunately, remain highly inadequately addressed by existing theory. In this paper, we focus on the most basic setting of competitive multi-agent RL, namely two-player zero-sum Markov games, and study equilibrium finding algorithms in both the infinite-horizon discounted setting and the finite-horizon episodic setting. We propose a single-loop policy optimization method with symmetric updates from both agents, where the policy is updated via the entropy-regularized optimistic multiplicative weights update (OMWU) method and the value is updated on a slower timescale. We show that, in the full-information tabular setting, the proposed method achieves a finite-time last-iterate linear convergence to the quantal response equilibrium of the regularized problem, which translates to a sublinear last-iterate convergence to the Nash equilibrium by controlling the amount of regularization. Our convergence results improve upon the best known iteration complexities, and lead to a better understanding of policy optimization in competitive Markov games.
Minimax-Optimal Multi-Agent RL in Zero-Sum Markov Games With a Generative Model
Aug 22, 2022This paper is concerned with two-player zero-sum Markov games -- arguably the most basic setting in multi-agent reinforcement learning -- with the goal of learning a Nash equilibrium (NE) sample-optimally. All prior results suffer from at least one of the two obstacles: the curse of multiple agents and the barrier of long horizon, regardless of the sampling protocol in use. We take a step towards settling this problem, assuming access to a flexible sampling mechanism: the generative model. Focusing on non-stationary finite-horizon Markov games, we develop a learning algorithm $\mathsf{Nash}\text{-}\mathsf{Q}\text{-}\mathsf{FTRL}$ and an adaptive sampling scheme that leverage the optimism principle in adversarial learning (particularly the Follow-the-Regularized-Leader (FTRL) method), with a delicate design of bonus terms that ensure certain decomposability under the FTRL dynamics. Our algorithm learns an $\varepsilon$-approximate Markov NE policy using $$ \widetilde{O}\bigg( \frac{H^4 S(A+B)}{\varepsilon^2} \bigg) $$ samples, where $S$ is the number of states, $H$ is the horizon, and $A$ (resp.~$B$) denotes the number of actions for the max-player (resp.~min-player). This is nearly un-improvable in a minimax sense. Along the way, we derive a refined regret bound for FTRL that makes explicit the role of variance-type quantities, which might be of independent interest.
Local Geometry of Nonconvex Spike Deconvolution from Low-Pass Measurements
Aug 22, 2022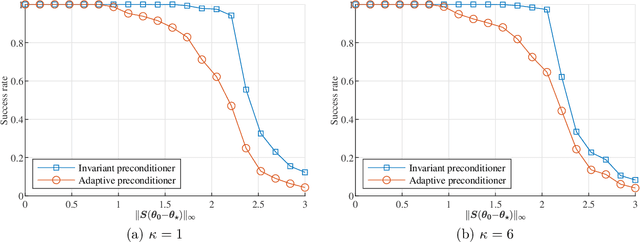
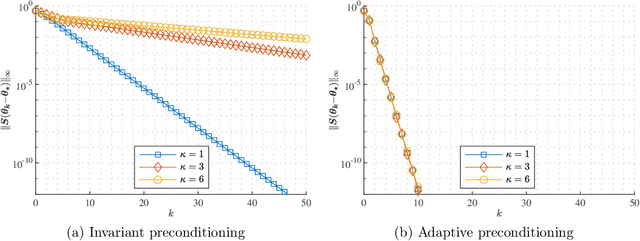
Spike deconvolution is the problem of recovering the point sources from their convolution with a known point spread function, which plays a fundamental role in many sensing and imaging applications. In this paper, we investigate the local geometry of recovering the parameters of point sources$\unicode{x2014}$including both amplitudes and locations$\unicode{x2014}$by minimizing a natural nonconvex least-squares loss function measuring the observation residuals. We propose preconditioned variants of gradient descent (GD), where the search direction is scaled via some carefully designed preconditioning matrices. We begin with a simple fixed preconditioner design, which adjusts the learning rates of the locations at a different scale from those of the amplitudes, and show it achieves a linear rate of convergence$\unicode{x2014}$in terms of entrywise errors$\unicode{x2014}$when initialized close to the ground truth, as long as the separation between the true spikes is sufficiently large. However, the convergence rate slows down significantly when the dynamic range of the source amplitudes is large. To bridge this issue, we introduce an adaptive preconditioner design, which compensates for the learning rates of different sources in an iteration-varying manner based on the current estimate. The adaptive design provably leads to an accelerated convergence rate that is independent of the dynamic range, highlighting the benefit of adaptive preconditioning in nonconvex spike deconvolution. Numerical experiments are provided to corroborate the theoretical findings.
Distributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity
Aug 11, 2022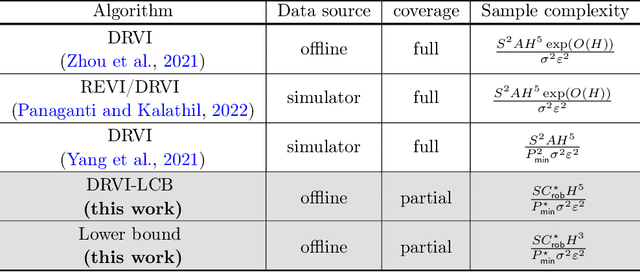
This paper concerns the central issues of model robustness and sample efficiency in offline reinforcement learning (RL), which aims to learn to perform decision making from history data without active exploration. Due to uncertainties and variabilities of the environment, it is critical to learn a robust policy -- with as few samples as possible -- that performs well even when the deployed environment deviates from the nominal one used to collect the history dataset. We consider a distributionally robust formulation of offline RL, focusing on a tabular non-stationary finite-horizon robust Markov decision process with an uncertainty set specified by the Kullback-Leibler divergence. To combat with sample scarcity, a model-based algorithm that combines distributionally robust value iteration with the principle of pessimism in the face of uncertainty is proposed, by penalizing the robust value estimates with a carefully designed data-driven penalty term. Under a mild and tailored assumption of the history dataset that measures distribution shift without requiring full coverage of the state-action space, we establish the finite-sample complexity of the proposed algorithm, and further show it is almost unimprovable in light of a nearly-matching information-theoretic lower bound up to a polynomial factor of the horizon length. To the best our knowledge, this provides the first provably near-optimal robust offline RL algorithm that learns under model uncertainty and partial coverage.
SoteriaFL: A Unified Framework for Private Federated Learning with Communication Compression
Jun 20, 2022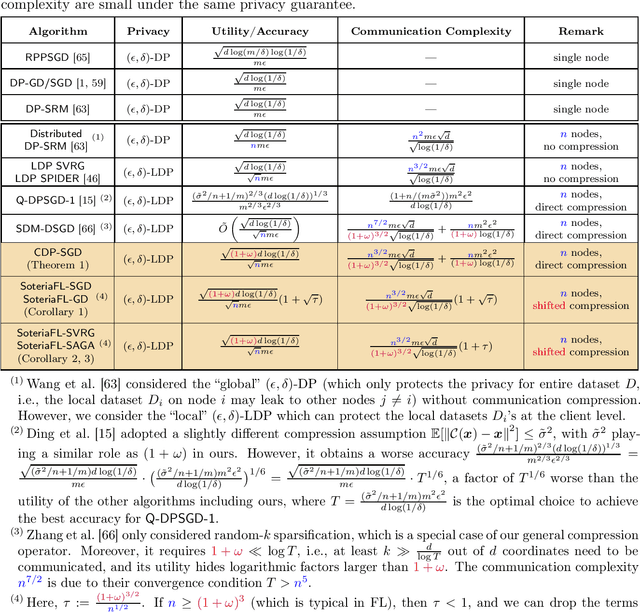

To enable large-scale machine learning in bandwidth-hungry environments such as wireless networks, significant progress has been made recently in designing communication-efficient federated learning algorithms with the aid of communication compression. On the other end, privacy-preserving, especially at the client level, is another important desideratum that has not been addressed simultaneously in the presence of advanced communication compression techniques yet. In this paper, we propose a unified framework that enhances the communication efficiency of private federated learning with communication compression. Exploiting both general compression operators and local differential privacy, we first examine a simple algorithm that applies compression directly to differentially-private stochastic gradient descent, and identify its limitations. We then propose a unified framework SoteriaFL for private federated learning, which accommodates a general family of local gradient estimators including popular stochastic variance-reduced gradient methods and the state-of-the-art shifted compression scheme. We provide a comprehensive characterization of its performance trade-offs in terms of privacy, utility, and communication complexity, where SoteraFL is shown to achieve better communication complexity without sacrificing privacy nor utility than other private federated learning algorithms without communication compression.
Fast and Provable Tensor Robust Principal Component Analysis via Scaled Gradient Descent
Jun 18, 2022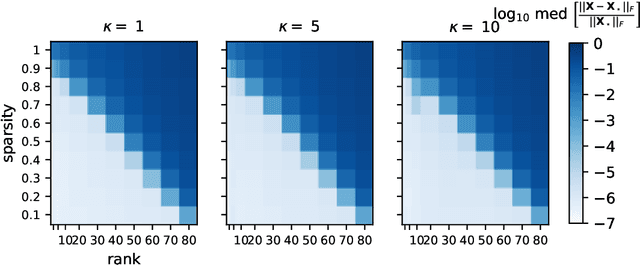


An increasing number of data science and machine learning problems rely on computation with tensors, which better capture the multi-way relationships and interactions of data than matrices. When tapping into this critical advantage, a key challenge is to develop computationally efficient and provably correct algorithms for extracting useful information from tensor data that are simultaneously robust to corruptions and ill-conditioning. This paper tackles tensor robust principal component analysis (RPCA), which aims to recover a low-rank tensor from its observations contaminated by sparse corruptions, under the Tucker decomposition. To minimize the computation and memory footprints, we propose to directly recover the low-dimensional tensor factors -- starting from a tailored spectral initialization -- via scaled gradient descent (ScaledGD), coupled with an iteration-varying thresholding operation to adaptively remove the impact of corruptions. Theoretically, we establish that the proposed algorithm converges linearly to the true low-rank tensor at a constant rate that is independent with its condition number, as long as the level of corruptions is not too large. Empirically, we demonstrate that the proposed algorithm achieves better and more scalable performance than state-of-the-art matrix and tensor RPCA algorithms through synthetic experiments and real-world applications.