 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Generative Planners in Verifiable Logic: A Hybrid Architecture for Trustworthy Embodied AI
Feb 09, 2026Large Language Models (LLMs) show promise as planners for embodied AI, but their stochastic nature lacks formal reasoning, preventing strict safety guarantees for physical deployment. Current approaches often rely on unreliable LLMs for safety checks or simply reject unsafe plans without offering repairs. We introduce the Verifiable Iterative Refinement Framework (VIRF), a neuro-symbolic architecture that shifts the paradigm from passive safety gatekeeping to active collaboration. Our core contribution is a tutor-apprentice dialogue where a deterministic Logic Tutor, grounded in a formal safety ontology, provides causal and pedagogical feedback to an LLM planner. This enables intelligent plan repairs rather than mere avoidance. We also introduce a scalable knowledge acquisition pipeline that synthesizes safety knowledge bases from real-world documents, correcting blind spots in existing benchmarks. In challenging home safety tasks, VIRF achieves a perfect 0 percent Hazardous Action Rate (HAR) and a 77.3 percent Goal-Condition Rate (GCR), which is the highest among all baselines. It is highly efficient, requiring only 1.1 correction iterations on average. VIRF demonstrates a principled pathway toward building fundamentally trustworthy and verifiably safe embodied agents.
TransMPC: Transformer-based Explicit MPC with Variable Prediction Horizon
Sep 09, 2025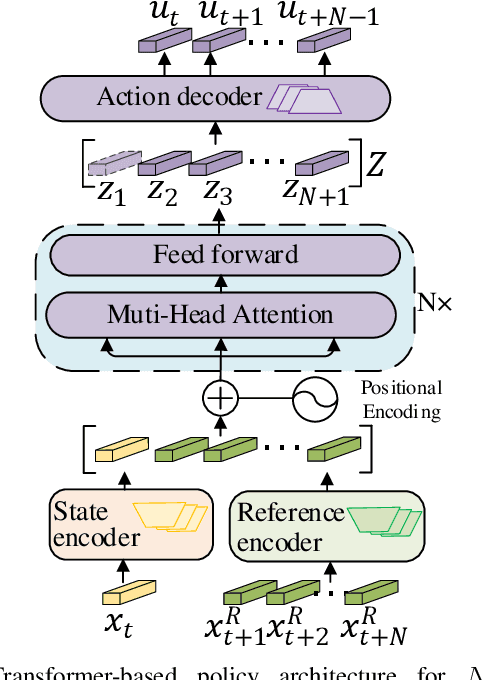
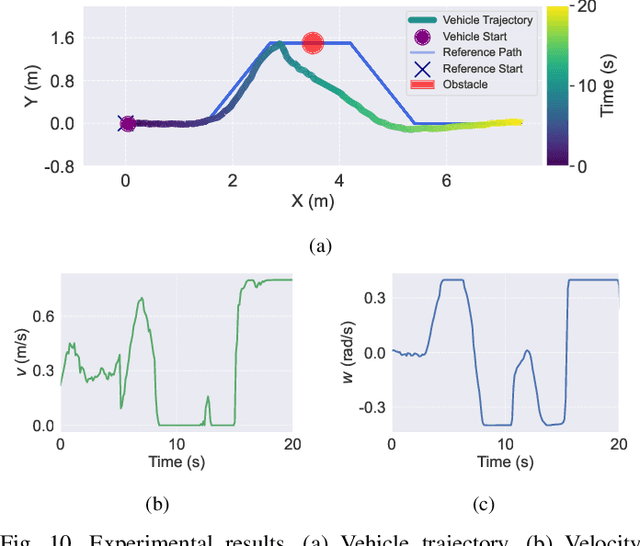

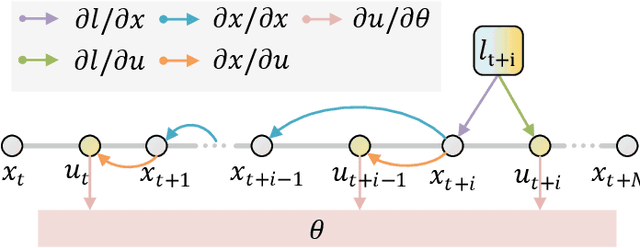
Traditional online Model Predictive Control (MPC) methods often suffer from excessive computational complexity, limiting their practical deployment. Explicit MPC mitigates online computational load by pre-computing control policies offline; however, existing explicit MPC methods typically rely on simplified system dynamics and cost functions, restricting their accuracy for complex systems. This paper proposes TransMPC, a novel Transformer-based explicit MPC algorithm capable of generating highly accurate control sequences in real-time for complex dynamic systems. Specifically, we formulate the MPC policy as an encoder-only Transformer leveraging bidirectional self-attention, enabling simultaneous inference of entire control sequences in a single forward pass. This design inherently accommodates variable prediction horizons while ensuring low inference latency. Furthermore, we introduce a direct policy optimization framework that alternates between sampling and learning phases. Unlike imitation-based approaches dependent on precomputed optimal trajectories, TransMPC directly optimizes the true finite-horizon cost via automatic differentiation. Random horizon sampling combined with a replay buffer provides independent and identically distributed (i.i.d.) training samples, ensuring robust generalization across varying states and horizon lengths. Extensive simulations and real-world vehicle control experiments validate the effectiveness of TransMPC in terms of solution accuracy, adaptability to varying horizons, and computational efficiency.