 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Power of Noise Priors: Enhancing Diffusion Models for Mobile Traffic Prediction
Jan 23, 2025



Accurate prediction of mobile traffic, \textit{i.e.,} network traffic from cellular base stations, is crucial for optimizing network performance and supporting urban development. However, the non-stationary nature of mobile traffic, driven by human activity and environmental changes, leads to both regular patterns and abrupt variations. Diffusion models excel in capturing such complex temporal dynamics due to their ability to capture the inherent uncertainties. Most existing approaches prioritize designing novel denoising networks but often neglect the critical role of noise itself, potentially leading to sub-optimal performance. In this paper, we introduce a novel perspective by emphasizing the role of noise in the denoising process. Our analysis reveals that noise fundamentally shapes mobile traffic predictions, exhibiting distinct and consistent patterns. We propose NPDiff, a framework that decomposes noise into \textit{prior} and \textit{residual} components, with the \textit{prior} derived from data dynamics, enhancing the model's ability to capture both regular and abrupt variations. NPDiff can seamlessly integrate with various diffusion-based prediction models, delivering predictions that are effective, efficient, and robust. Extensive experiments demonstrate that it achieves superior performance with an improvement over 30\%, offering a new perspective on leveraging diffusion models in this domain.
An Imbalanced Learning-based Sampling Method for Physics-informed Neural Networks
Jan 20, 2025
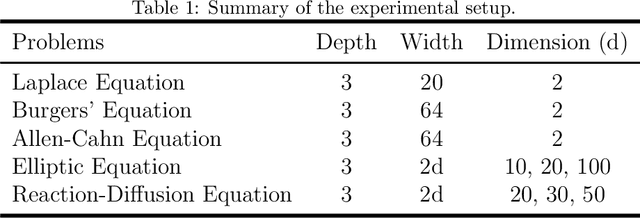


This paper introduces Residual-based Smote (RSmote), an innovative local adaptive sampling technique tailored to improve the performance of Physics-Informed Neural Networks (PINNs) through imbalanced learning strategies. Traditional residual-based adaptive sampling methods, while effective in enhancing PINN accuracy, often struggle with efficiency and high memory consumption, particularly in high-dimensional problems. RSmote addresses these challenges by targeting regions with high residuals and employing oversampling techniques from imbalanced learning to refine the sampling process. Our approach is underpinned by a rigorous theoretical analysis that supports the effectiveness of RSmote in managing computational resources more efficiently. Through extensive evaluations, we benchmark RSmote against the state-of-the-art Residual-based Adaptive Distribution (RAD) method across a variety of dimensions and differential equations. The results demonstrate that RSmote not only achieves or exceeds the accuracy of RAD but also significantly reduces memory usage, making it particularly advantageous in high-dimensional scenarios. These contributions position RSmote as a robust and resource-efficient solution for solving complex partial differential equations, especially when computational constraints are a critical consideration.
Experimental Demonstration of an Optical Neural PDE Solver via On-Chip PINN Training
Jan 01, 2025


Partial differential equation (PDE) is an important math tool in science and engineering. This paper experimentally demonstrates an optical neural PDE solver by leveraging the back-propagation-free on-photonic-chip training of physics-informed neural networks.
Is Large Language Model Good at Triple Set Prediction? An Empirical Study
Dec 24, 2024



The core of the Knowledge Graph Completion (KGC) task is to predict and complete the missing relations or nodes in a KG. Common KGC tasks are mostly about inferring unknown elements with one or two elements being known in a triple. In comparison, the Triple Set Prediction (TSP) task is a more realistic knowledge graph completion task. It aims to predict all elements of unknown triples based on the information from known triples. In recent years, large language models (LLMs) have exhibited significant advancements in language comprehension, demonstrating considerable potential for KGC tasks. However, the potential of LLM on the TSP task has not yet to be investigated. Thus in this paper we proposed a new framework to explore the strengths and limitations of LLM in the TSP task. Specifically, the framework consists of LLM-based rule mining and LLM-based triple set prediction. The relation list of KG embedded within rich semantic information is first leveraged to prompt LLM in the generation of rules. This process is both efficient and independent of statistical information, making it easier to mine effective and realistic rules. For each subgraph, the specified rule is applied in conjunction with the relevant triples within that subgraph to guide the LLM in predicting the missing triples. Subsequently, the predictions from all subgraphs are consolidated to derive the complete set of predicted triples on KG. Finally, the method is evaluated on the relatively complete CFamily dataset. The experimental results indicate that when LLMs are required to adhere to a large amount of factual knowledge to predict missing triples, significant hallucinations occurs, leading to a noticeable decline in performance. To further explore the causes of this phenomenon, this paper presents a comprehensive analysis supported by a detailed case study.
A Universal Model for Human Mobility Prediction
Dec 19, 2024



Predicting human mobility is crucial for urban planning, traffic control, and emergency response. Mobility behaviors can be categorized into individual and collective, and these behaviors are recorded by diverse mobility data, such as individual trajectory and crowd flow. As different modalities of mobility data, individual trajectory and crowd flow have a close coupling relationship. Crowd flows originate from the bottom-up aggregation of individual trajectories, while the constraints imposed by crowd flows shape these individual trajectories. Existing mobility prediction methods are limited to single tasks due to modal gaps between individual trajectory and crowd flow. In this work, we aim to unify mobility prediction to break through the limitations of task-specific models. We propose a universal human mobility prediction model (named UniMob), which can be applied to both individual trajectory and crowd flow. UniMob leverages a multi-view mobility tokenizer that transforms both trajectory and flow data into spatiotemporal tokens, facilitating unified sequential modeling through a diffusion transformer architecture. To bridge the gap between the different characteristics of these two data modalities, we implement a novel bidirectional individual and collective alignment mechanism. This mechanism enables learning common spatiotemporal patterns from different mobility data, facilitating mutual enhancement of both trajectory and flow predictions. Extensive experiments on real-world datasets validate the superiority of our model over state-of-the-art baselines in trajectory and flow prediction. Especially in noisy and scarce data scenarios, our model achieves the highest performance improvement of more than 14% and 25% in MAPE and Accuracy@5.
Seeker: Towards Exception Safety Code Generation with Intermediate Language Agents Framework
Dec 16, 2024



In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open-source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Block, and Distorted Handling Solution. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi-agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices in real development scenarios, providing valuable insights for future improvements in code reliability.
Edge Contrastive Learning: An Augmentation-Free Graph Contrastive Learning Model
Dec 15, 2024



Graph contrastive learning (GCL) aims to learn representations from unlabeled graph data in a self-supervised manner and has developed rapidly in recent years. However, edgelevel contrasts are not well explored by most existing GCL methods. Most studies in GCL only regard edges as auxiliary information while updating node features. One of the primary obstacles of edge-based GCL is the heavy computation burden. To tackle this issue, we propose a model that can efficiently learn edge features for GCL, namely AugmentationFree Edge Contrastive Learning (AFECL) to achieve edgeedge contrast. AFECL depends on no augmentation consisting of two parts. Firstly, we design a novel edge feature generation method, where edge features are computed by embedding concatenation of their connected nodes. Secondly, an edge contrastive learning scheme is developed, where edges connecting the same nodes are defined as positive pairs, and other edges are defined as negative pairs. Experimental results show that compared with recent state-of-the-art GCL methods or even some supervised GNNs, AFECL achieves SOTA performance on link prediction and semi-supervised node classification of extremely scarce labels. The source code is available at https://github.com/YujunLi361/AFECL.
Memory-enhanced Invariant Prompt Learning for Urban Flow Prediction under Distribution Shifts
Dec 07, 2024



Urban flow prediction is a classic spatial-temporal forecasting task that estimates the amount of future traffic flow for a given location. Though models represented by Spatial-Temporal Graph Neural Networks (STGNNs) have established themselves as capable predictors, they tend to suffer from distribution shifts that are common with the urban flow data due to the dynamics and unpredictability of spatial-temporal events. Unfortunately, in spatial-temporal applications, the dynamic environments can hardly be quantified via a fixed number of parameters, whereas learning time- and location-specific environments can quickly become computationally prohibitive. In this paper, we propose a novel framework named Memory-enhanced Invariant Prompt learning (MIP) for urban flow prediction under constant distribution shifts. Specifically, MIP is equipped with a learnable memory bank that is trained to memorize the causal features within the spatial-temporal graph. By querying a trainable memory bank that stores the causal features, we adaptively extract invariant and variant prompts (i.e., patterns) for a given location at every time step. Then, instead of intervening the raw data based on simulated environments, we directly perform intervention on variant prompts across space and time. With the intervened variant prompts in place, we use invariant learning to minimize the variance of predictions, so as to ensure that the predictions are only made with invariant features. With extensive comparative experiments on two public urban flow datasets, we thoroughly demonstrate the robustness of MIP against OOD data.
Noise Matters: Diffusion Model-based Urban Mobility Generation with Collaborative Noise Priors
Dec 06, 2024With global urbanization, the focus on sustainable cities has largely grown, driving research into equity, resilience, and urban planning, which often relies on mobility data. The rise of web-based apps and mobile devices has provided valuable user data for mobility-related research. However, real-world mobility data is costly and raises privacy concerns. To protect privacy while retaining key features of real-world movement, the demand for synthetic data has steadily increased. Recent advances in diffusion models have shown great potential for mobility trajectory generation due to their ability to model randomness and uncertainty. However, existing approaches often directly apply identically distributed (i.i.d.) noise sampling from image generation techniques, which fail to account for the spatiotemporal correlations and social interactions that shape urban mobility patterns. In this paper, we propose CoDiffMob, a diffusion method for urban mobility generation with collaborative noise priors, we emphasize the critical role of noise in diffusion models for generating mobility data. By leveraging both individual movement characteristics and population-wide dynamics, we construct novel collaborative noise priors that provide richer and more informative guidance throughout the generation process. Extensive experiments demonstrate the superiority of our method, with generated data accurately capturing both individual preferences and collective patterns, achieving an improvement of over 32\%. Furthermore, it can effectively replace web-derived mobility data to better support downstream applications, while safeguarding user privacy and fostering a more secure and ethical web. This highlights its tremendous potential for applications in sustainable city-related research.
Understanding World or Predicting Future? A Comprehensive Survey of World Models
Nov 21, 2024



The concept of world models has garnered significant attention due to advancements in multimodal large language models such as GPT-4 and video generation models such as Sora, which are central to the pursuit of artificial general intelligence. This survey offers a comprehensive review of the literature on world models. Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics. This review presents a systematic categorization of world models, emphasizing two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making. Initially, we examine the current progress in these two categories. We then explore the application of world models in key domains, including autonomous driving, robotics, and social simulacra, with a focus on how each domain utilizes these aspects. Finally, we outline key challenges and provide insights into potential future research directions.