 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Guided Representation Learning with Applications to Visual Synthesis
Oct 21, 2020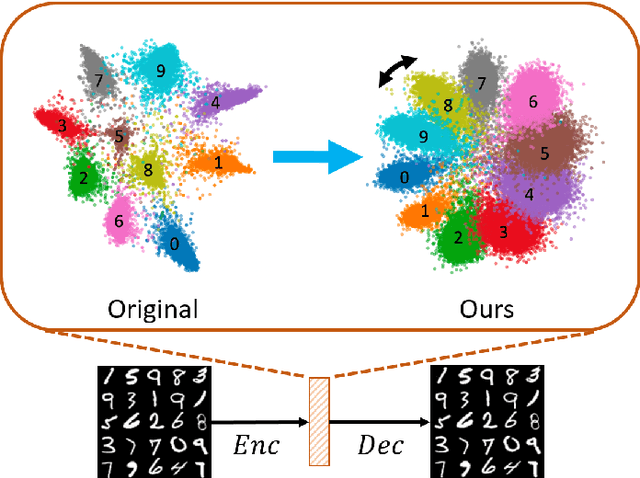

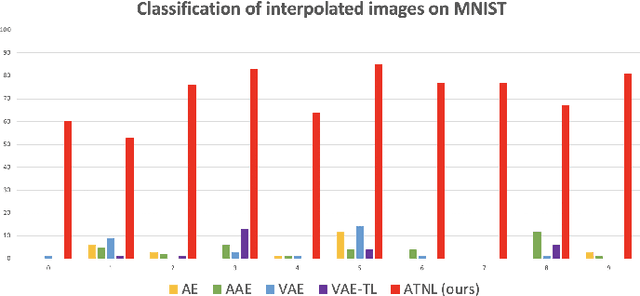
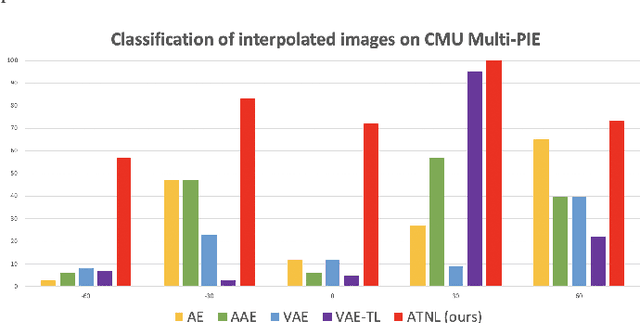
Learning interpretable and interpolatable latent representations has been an emerging research direction, allowing researchers to understand and utilize the derived latent space for further applications such as visual synthesis or recognition. While most existing approaches derive an interpolatable latent space and induces smooth transition in image appearance, it is still not clear how to observe desirable representations which would contain semantic information of interest. In this paper, we aim to learn meaningful representations and simultaneously perform semantic-oriented and visually-smooth interpolation. To this end, we propose an angular triplet-neighbor loss (ATNL) that enables learning a latent representation whose distribution matches the semantic information of interest. With the latent space guided by ATNL, we further utilize spherical semantic interpolation for generating semantic warping of images, allowing synthesis of desirable visual data. Experiments on MNIST and CMU Multi-PIE datasets qualitatively and quantitatively verify the effectiveness of our method.
Semantics-Guided Clustering with Deep Progressive Learning for Semi-Supervised Person Re-identification
Oct 02, 2020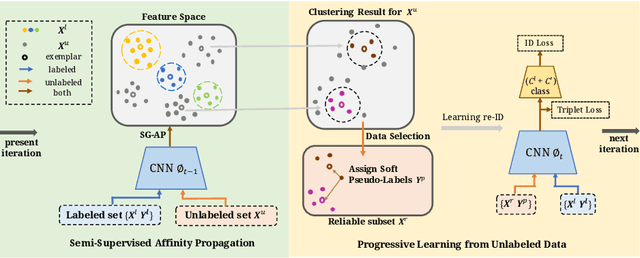
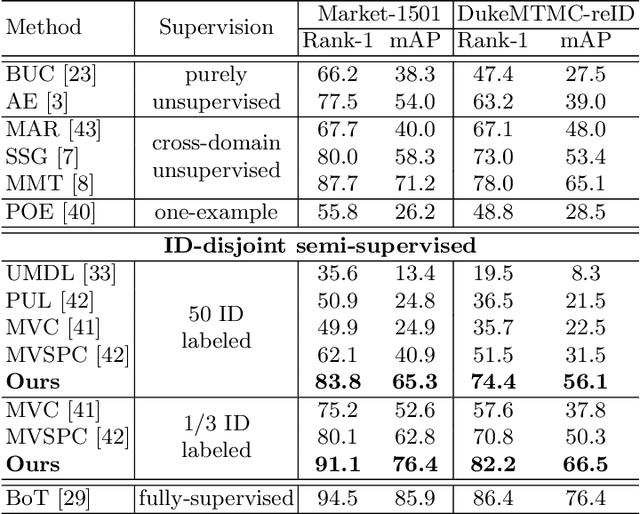
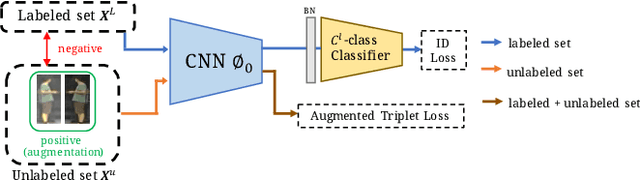
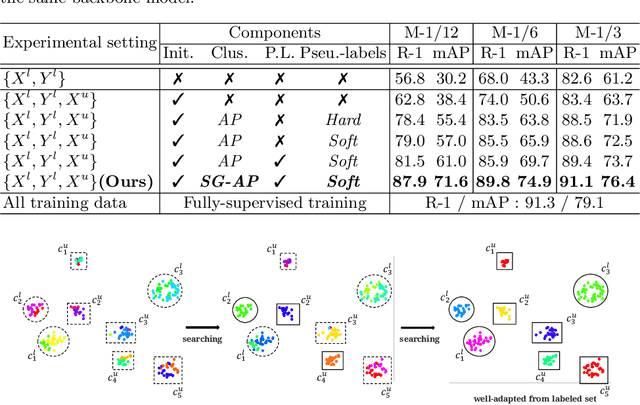
Person re-identification (re-ID) requires one to match images of the same person across camera views. As a more challenging task, semi-supervised re-ID tackles the problem that only a number of identities in training data are fully labeled, while the remaining are unlabeled. Assuming that such labeled and unlabeled training data share disjoint identity labels, we propose a novel framework of Semantics-Guided Clustering with Deep Progressive Learning (SGC-DPL) to jointly exploit the above data. By advancing the proposed Semantics-Guided Affinity Propagation (SG-AP), we are able to assign pseudo-labels to selected unlabeled data in a progressive fashion, under the semantics guidance from the labeled ones. As a result, our approach is able to augment the labeled training data in the semi-supervised setting. Our experiments on two large-scale person re-ID benchmarks demonstrate the superiority of our SGC-DPL over state-of-the-art methods across different degrees of supervision. In extension, the generalization ability of our SGC-DPL is also verified in other tasks like vehicle re-ID or image retrieval with the semi-supervised setting.
Transforming Multi-Concept Attention into Video Summarization
Jun 03, 2020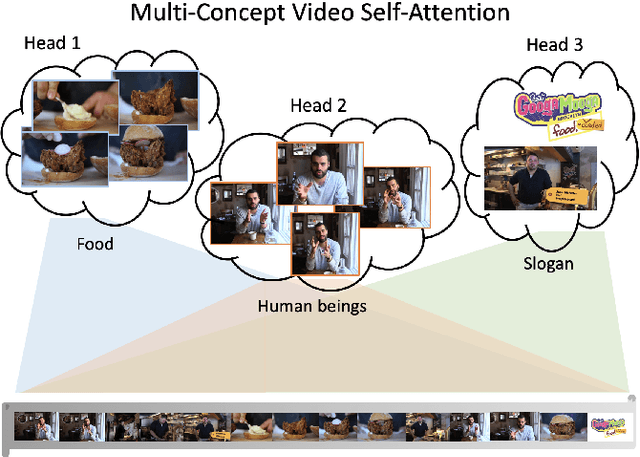
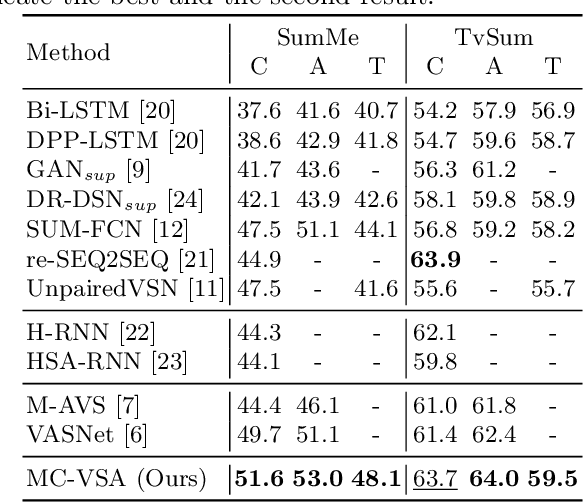
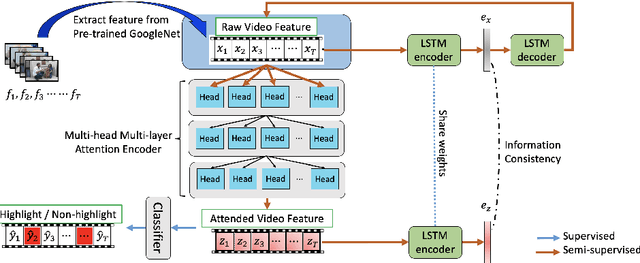

Video summarization is among challenging tasks in computer vision, which aims at identifying highlight frames or shots over a lengthy video input. In this paper, we propose an novel attention-based framework for video summarization with complex video data. Unlike previous works which only apply attention mechanism on the correspondence between frames, our multi-concept video self-attention (MC-VSA) model is presented to identify informative regions across temporal and concept video features, which jointly exploit context diversity over time and space for summarization purposes. Together with consistency between video and summary enforced in our framework, our model can be applied to both labeled and unlabeled data, making our method preferable to real-world applications. Extensive and complete experiments on two benchmarks demonstrate the effectiveness of our model both quantitatively and qualitatively, and confirms its superiority over the stateof-the-arts.
Learning Shape Representations for Clothing Variations in Person Re-Identification
Mar 16, 2020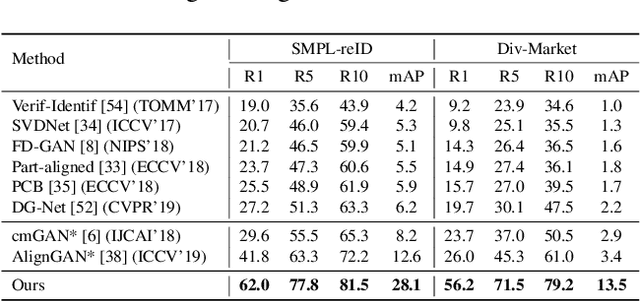

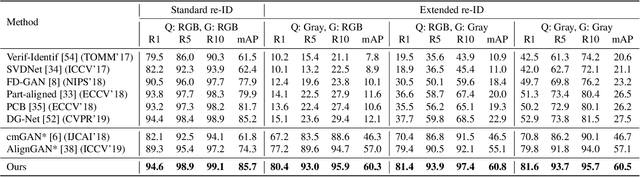

Person re-identification (re-ID) aims to recognize instances of the same person contained in multiple images taken across different cameras. Existing methods for re-ID tend to rely heavily on the assumption that both query and gallery images of the same person have the same clothing. Unfortunately, this assumption may not hold for datasets captured over long periods of time (e.g., weeks, months or years). To tackle the re-ID problem in the context of clothing changes, we propose a novel representation learning model which is able to generate a body shape feature representation without being affected by clothing color or patterns. We call our model the Color Agnostic Shape Extraction Network (CASE-Net). CASE-Net learns a representation of identity that depends only on body shape via adversarial learning and feature disentanglement. Due to the lack of large-scale re-ID datasets which contain clothing changes for the same person, we propose two synthetic datasets for evaluation. We create a rendered dataset SMPL-reID with different clothes patterns and a synthesized dataset Div-Market with different clothing color to simulate two types of clothing changes. The quantitative and qualitative results across 5 datasets (SMPL-reID, Div-Market, two benchmark re-ID datasets, a cross-modality re-ID dataset) confirm the robustness and superiority of our approach against several state-of-the-art approaches
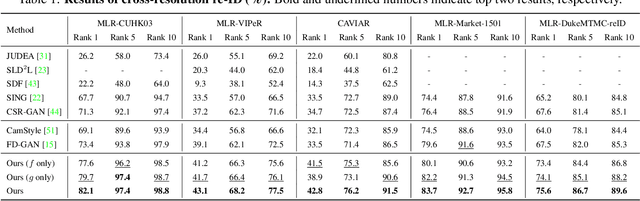
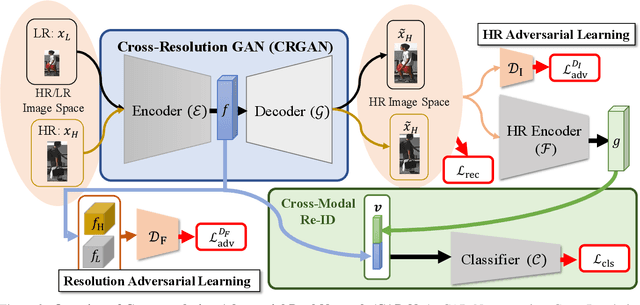
Cross-Resolution Adversarial Dual Network for Person Re-Identification and Beyond
Feb 19, 2020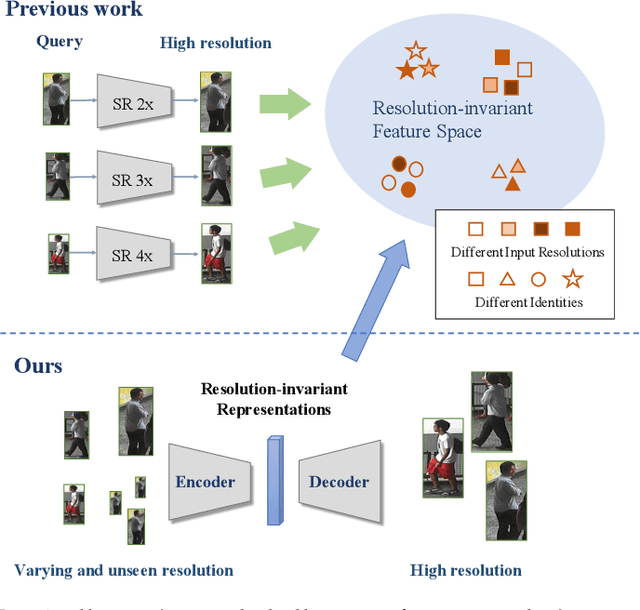
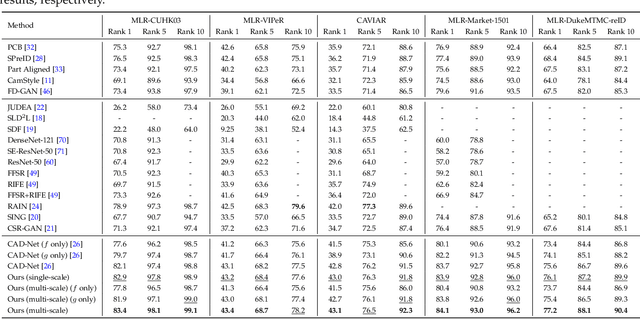
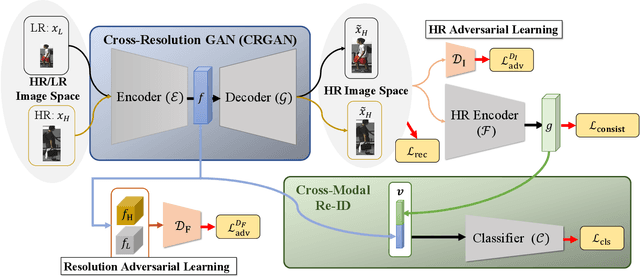
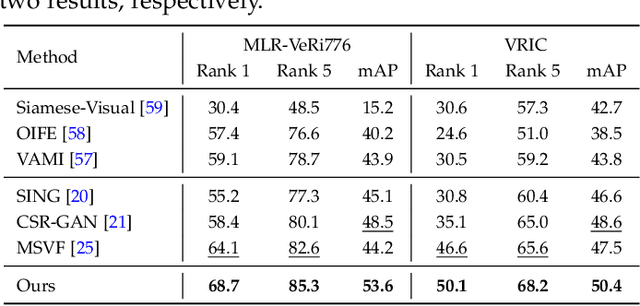
Person re-identification (re-ID) aims at matching images of the same person across camera views. Due to varying distances between cameras and persons of interest, resolution mismatch can be expected, which would degrade re-ID performance in real-world scenarios. To overcome this problem, we propose a novel generative adversarial network to address cross-resolution person re-ID, allowing query images with varying resolutions. By advancing adversarial learning techniques, our proposed model learns resolution-invariant image representations while being able to recover the missing details in low-resolution input images. The resulting features can be jointly applied for improving re-ID performance due to preserving resolution invariance and recovering re-ID oriented discriminative details. Extensive experimental results on five standard person re-ID benchmarks confirm the effectiveness of our method and the superiority over the state-of-the-art approaches, especially when the input resolutions are not seen during training. Furthermore, the experimental results on two vehicle re-ID benchmarks also confirm the generalization of our model on cross-resolution visual tasks. The extensions of semi-supervised settings further support the use of our proposed approach to real-world scenarios and applications.
Cross-Dataset Person Re-Identification via Unsupervised Pose Disentanglement and Adaptation
Sep 20, 2019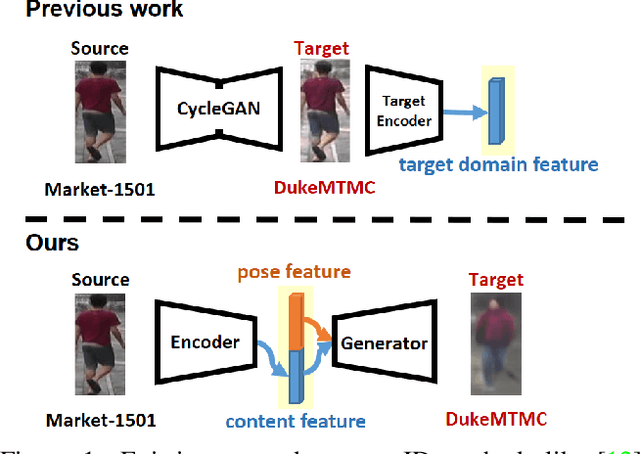
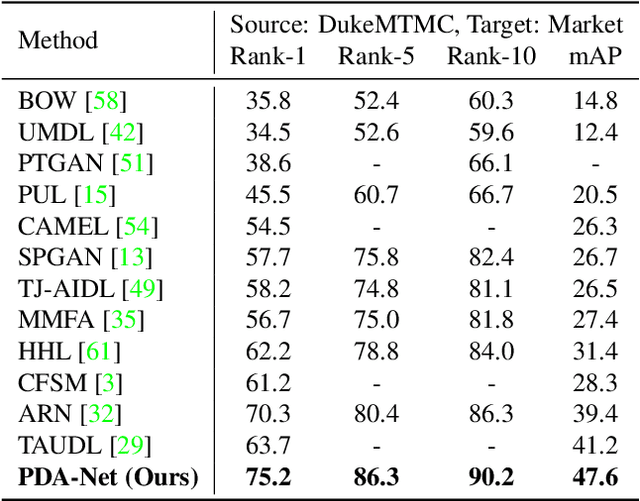
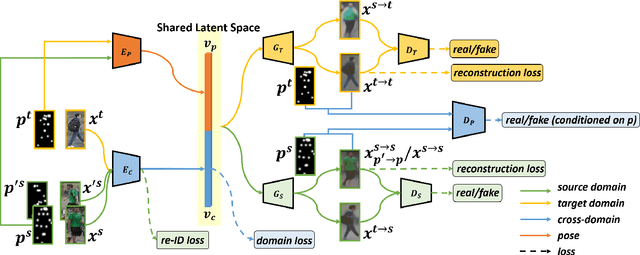
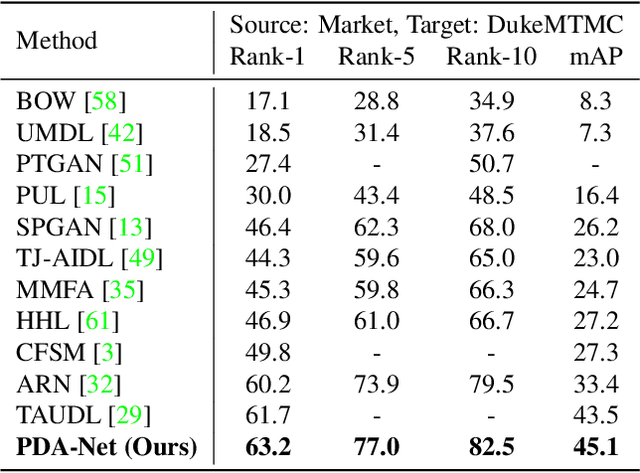
Person re-identification (re-ID) aims at recognizing the same person from images taken across different cameras. To address this challenging task, existing re-ID models typically rely on a large amount of labeled training data, which is not practical for real-world applications. To alleviate this limitation, researchers now targets at cross-dataset re-ID which focuses on generalizing the discriminative ability to the unlabeled target domain when given a labeled source domain dataset. To achieve this goal, our proposed Pose Disentanglement and Adaptation Network (PDA-Net) aims at learning deep image representation with pose and domain information properly disentangled. With the learned cross-domain pose invariant feature space, our proposed PDA-Net is able to perform pose disentanglement across domains without supervision in identities, and the resulting features can be applied to cross-dataset re-ID. Both of our qualitative and quantitative results on two benchmark datasets confirm the effectiveness of our approach and its superiority over the state-of-the-art cross-dataset Re-ID approaches.
Recover and Identify: A Generative Dual Model for Cross-Resolution Person Re-Identification
Aug 16, 2019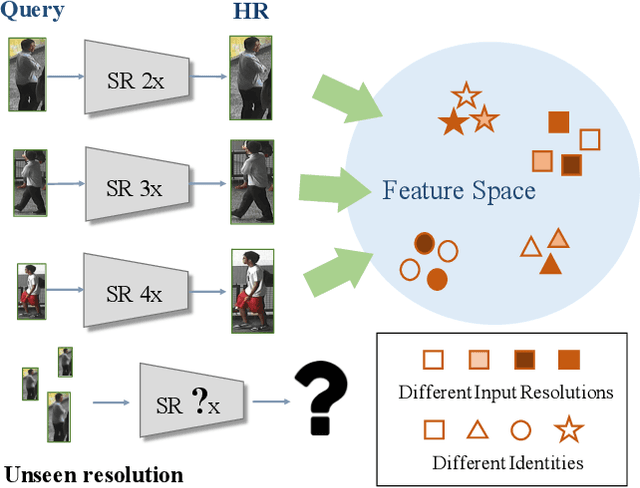

Person re-identification (re-ID) aims at matching images of the same identity across camera views. Due to varying distances between cameras and persons of interest, resolution mismatch can be expected, which would degrade person re-ID performance in real-world scenarios. To overcome this problem, we propose a novel generative adversarial network to address cross-resolution person re-ID, allowing query images with varying resolutions. By advancing adversarial learning techniques, our proposed model learns resolution-invariant image representations while being able to recover the missing details in low-resolution input images. The resulting features can be jointly applied for improving person re-ID performance due to preserving resolution invariance and recovering re-ID oriented discriminative details. Our experiments on five benchmark datasets confirm the effectiveness of our approach and its superiority over the state-of-the-art methods, especially when the input resolutions are unseen during training.
Learning Resolution-Invariant Deep Representations for Person Re-Identification
Jul 25, 2019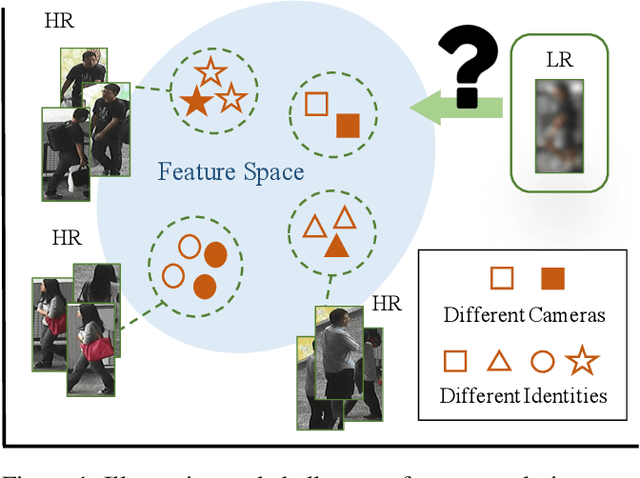
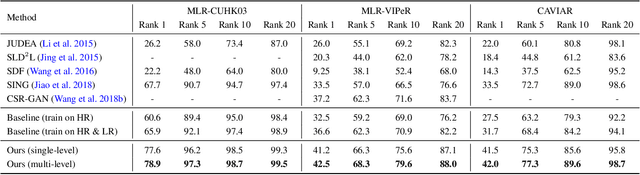
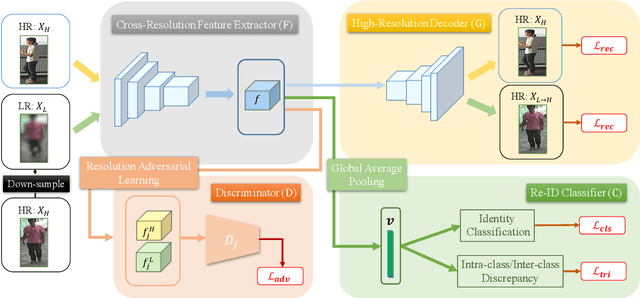
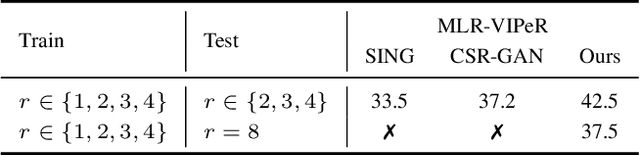
Person re-identification (re-ID) solves the task of matching images across cameras and is among the research topics in vision community. Since query images in real-world scenarios might suffer from resolution loss, how to solve the resolution mismatch problem during person re-ID becomes a practical problem. Instead of applying separate image super-resolution models, we propose a novel network architecture of Resolution Adaptation and re-Identification Network (RAIN) to solve cross-resolution person re-ID. Advancing the strategy of adversarial learning, we aim at extracting resolution-invariant representations for re-ID, while the proposed model is learned in an end-to-end training fashion. Our experiments confirm that the use of our model can recognize low-resolution query images, even if the resolution is not seen during training. Moreover, the extension of our model for semi-supervised re-ID further confirms the scalability of our proposed method for real-world scenarios and applications.
Dual-modality seq2seq network for audio-visual event localization
Feb 20, 2019
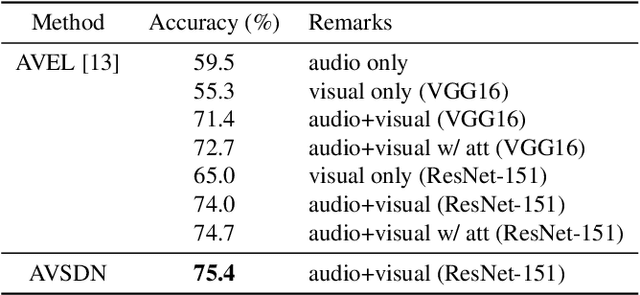
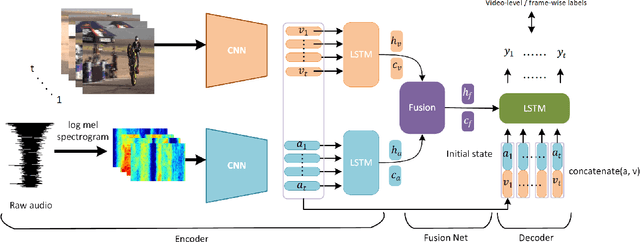
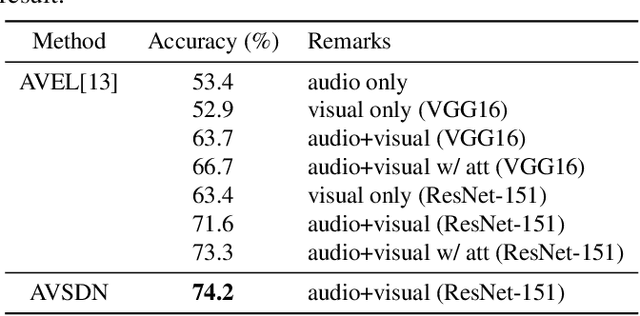
Audio-visual event localization requires one to identify theevent which is both visible and audible in a video (eitherat a frame or video level). To address this task, we pro-pose a deep neural network named Audio-Visual sequence-to-sequence dual network (AVSDN). By jointly taking bothaudio and visual features at each time segment as inputs, ourproposed model learns global and local event information ina sequence to sequence manner, which can be realized in ei-ther fully supervised or weakly supervised settings. Empiricalresults confirm that our proposed method performs favorablyagainst recent deep learning approaches in both settings.
Deep Reinforcement Learning for Playing 2.5D Fighting Games
May 05, 2018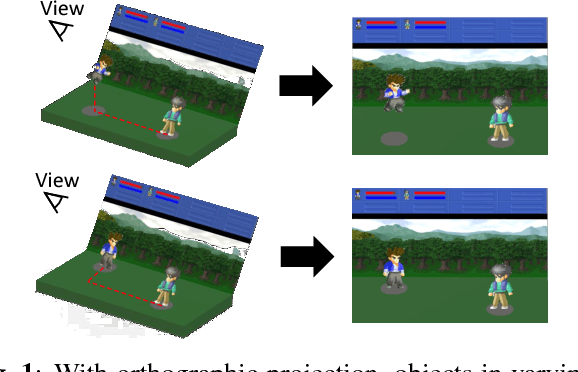
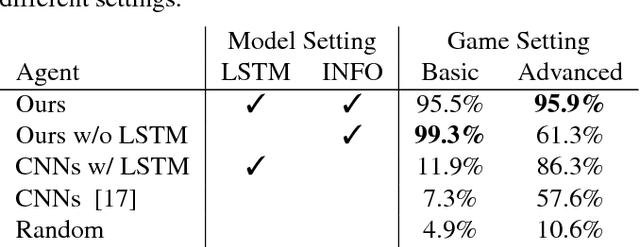
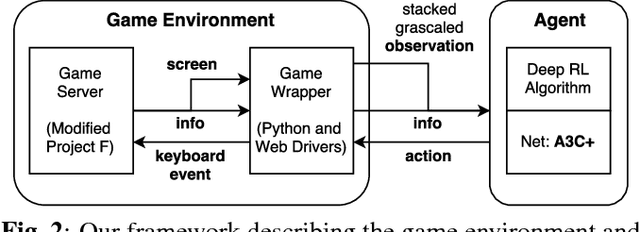
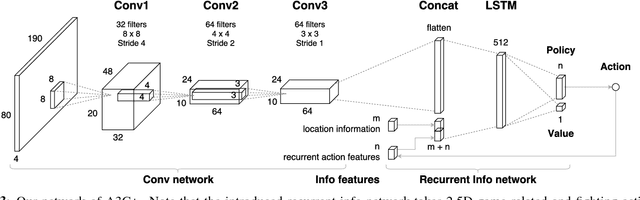
Deep reinforcement learning has shown its success in game playing. However, 2.5D fighting games would be a challenging task to handle due to ambiguity in visual appearances like height or depth of the characters. Moreover, actions in such games typically involve particular sequential action orders, which also makes the network design very difficult. Based on the network of Asynchronous Advantage Actor-Critic (A3C), we create an OpenAI-gym-like gaming environment with the game of Little Fighter 2 (LF2), and present a novel A3C+ network for learning RL agents. The introduced model includes a Recurrent Info network, which utilizes game-related info features with recurrent layers to observe combo skills for fighting. In the experiments, we consider LF2 in different settings, which successfully demonstrates the use of our proposed model for learning 2.5D fighting games.