 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
MuLan: A Study of Fact Mutability in Language Models
Apr 03, 2024



Facts are subject to contingencies and can be true or false in different circumstances. One such contingency is time, wherein some facts mutate over a given period, e.g., the president of a country or the winner of a championship. Trustworthy language models ideally identify mutable facts as such and process them accordingly. We create MuLan, a benchmark for evaluating the ability of English language models to anticipate time-contingency, covering both 1:1 and 1:N relations. We hypothesize that mutable facts are encoded differently than immutable ones, hence being easier to update. In a detailed evaluation of six popular large language models, we consistently find differences in the LLMs' confidence, representations, and update behavior, depending on the mutability of a fact. Our findings should inform future work on the injection of and induction of time-contingent knowledge to/from LLMs.
Multimodal Large Language Models to Support Real-World Fact-Checking
Mar 06, 2024Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
Answerability in Retrieval-Augmented Open-Domain Question Answering
Mar 03, 2024



The performance of Open-Domain Question Answering (ODQA) retrieval systems can exhibit sub-optimal behavior, providing text excerpts with varying degrees of irrelevance. Unfortunately, many existing ODQA datasets lack examples specifically targeting the identification of irrelevant text excerpts. Previous attempts to address this gap have relied on a simplistic approach of pairing questions with random text excerpts. This paper aims to investigate the effectiveness of models trained using this randomized strategy, uncovering an important limitation in their ability to generalize to irrelevant text excerpts with high semantic overlap. As a result, we observed a substantial decrease in predictive accuracy, from 98% to 1%. To address this limitation, we discovered an efficient approach for training models to recognize such excerpts. By leveraging unanswerable pairs from the SQuAD 2.0 dataset, our models achieve a nearly perfect (~100%) accuracy when confronted with these challenging text excerpts.
Cultural Adaptation of Recipes
Oct 26, 2023Building upon the considerable advances in Large Language Models (LLMs), we are now equipped to address more sophisticated tasks demanding a nuanced understanding of cross-cultural contexts. A key example is recipe adaptation, which goes beyond simple translation to include a grasp of ingredients, culinary techniques, and dietary preferences specific to a given culture. We introduce a new task involving the translation and cultural adaptation of recipes between Chinese and English-speaking cuisines. To support this investigation, we present CulturalRecipes, a unique dataset comprised of automatically paired recipes written in Mandarin Chinese and English. This dataset is further enriched with a human-written and curated test set. In this intricate task of cross-cultural recipe adaptation, we evaluate the performance of various methods, including GPT-4 and other LLMs, traditional machine translation, and information retrieval techniques. Our comprehensive analysis includes both automatic and human evaluation metrics. While GPT-4 exhibits impressive abilities in adapting Chinese recipes into English, it still lags behind human expertise when translating English recipes into Chinese. This underscores the multifaceted nature of cultural adaptations. We anticipate that these insights will significantly contribute to future research on culturally-aware language models and their practical application in culturally diverse contexts.
Large Language Models Converge on Brain-Like Word Representations
Jun 02, 2023One of the greatest puzzles of all time is how understanding arises from neural mechanics. Our brains are networks of billions of biological neurons transmitting chemical and electrical signals along their connections. Large language models are networks of millions or billions of digital neurons, implementing functions that read the output of other functions in complex networks. The failure to see how meaning would arise from such mechanics has led many cognitive scientists and philosophers to various forms of dualism -- and many artificial intelligence researchers to dismiss large language models as stochastic parrots or jpeg-like compressions of text corpora. We show that human-like representations arise in large language models. Specifically, the larger neural language models get, the more their representations are structurally similar to neural response measurements from brain imaging.
Retrieval-augmented Multi-label Text Classification
May 22, 2023Multi-label text classification (MLC) is a challenging task in settings of large label sets, where label support follows a Zipfian distribution. In this paper, we address this problem through retrieval augmentation, aiming to improve the sample efficiency of classification models. Our approach closely follows the standard MLC architecture of a Transformer-based encoder paired with a set of classification heads. In our case, however, the input document representation is augmented through cross-attention to similar documents retrieved from the training set and represented in a task-specific manner. We evaluate this approach on four datasets from the legal and biomedical domains, all of which feature highly skewed label distributions. Our experiments show that retrieval augmentation substantially improves model performance on the long tail of infrequent labels especially so for lower-resource training scenarios and more challenging long-document data scenarios.
An Exploration of Encoder-Decoder Approaches to Multi-Label Classification for Legal and Biomedical Text
May 09, 2023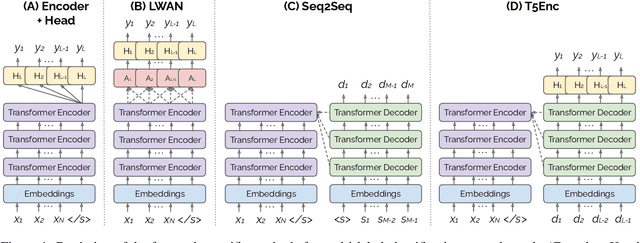
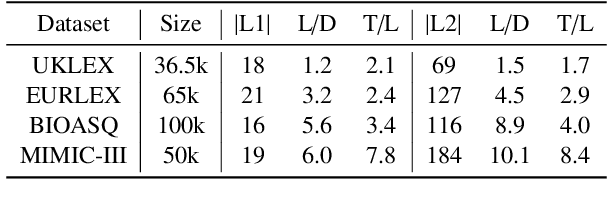
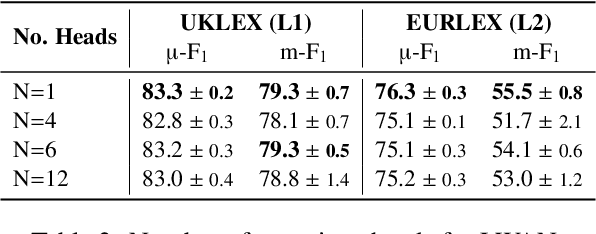
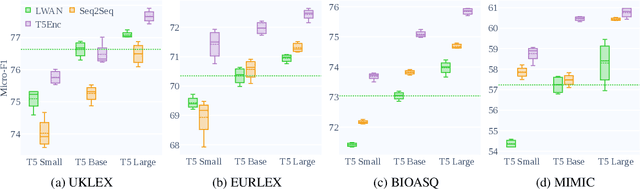
Standard methods for multi-label text classification largely rely on encoder-only pre-trained language models, whereas encoder-decoder models have proven more effective in other classification tasks. In this study, we compare four methods for multi-label classification, two based on an encoder only, and two based on an encoder-decoder. We carry out experiments on four datasets -- two in the legal domain and two in the biomedical domain, each with two levels of label granularity -- and always depart from the same pre-trained model, T5. Our results show that encoder-decoder methods outperform encoder-only methods, with a growing advantage on more complex datasets and labeling schemes of finer granularity. Using encoder-decoder models in a non-autoregressive fashion, in particular, yields the best performance overall, so we further study this approach through ablations to better understand its strengths.
Implications of the Convergence of Language and Vision Model Geometries
Feb 13, 2023Large-scale pretrained language models (LMs) are said to ``lack the ability to connect [their] utterances to the world'' (Bender and Koller, 2020). If so, we would expect LM representations to be unrelated to representations in computer vision models. To investigate this, we present an empirical evaluation across three different LMs (BERT, GPT2, and OPT) and three computer vision models (VMs, including ResNet, SegFormer, and MAE). Our experiments show that LMs converge towards representations that are partially isomorphic to those of VMs, with dispersion, and polysemy both factoring into the alignability of vision and language spaces. We discuss the implications of this finding.
SmallCap: Lightweight Image Captioning Prompted with Retrieval Augmentation
Sep 30, 2022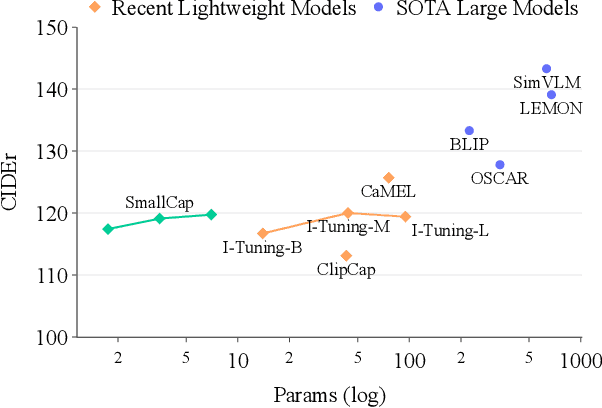
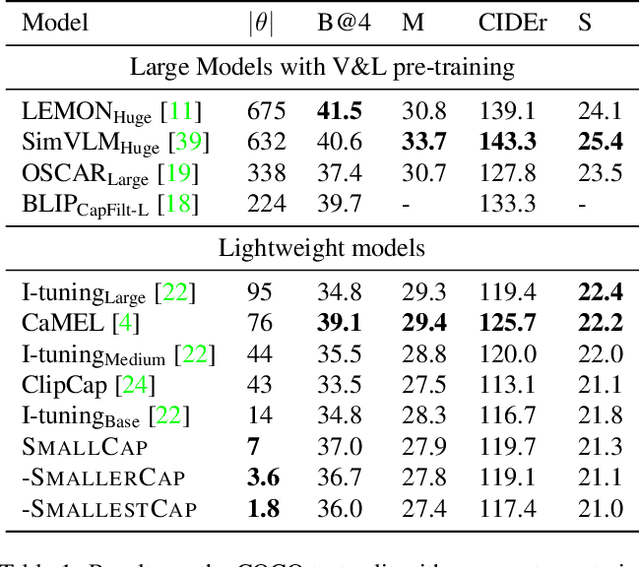
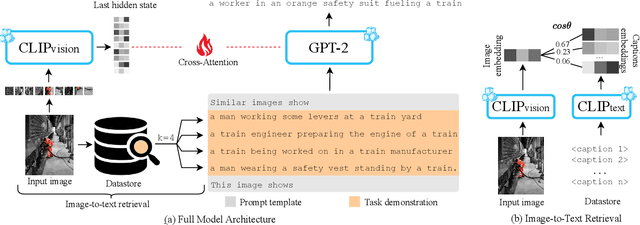
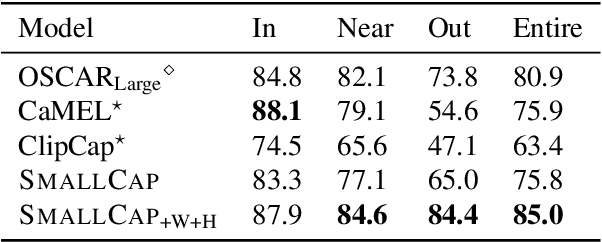
Recent advances in image captioning have focused on scaling the data and model size, substantially increasing the cost of pre-training and finetuning. As an alternative to large models, we present SmallCap, which generates a caption conditioned on an input image and related captions retrieved from a datastore. Our model is lightweight and fast to train as the only learned parameters are in newly introduced cross-attention layers between a pre-trained CLIP encoder and GPT-2 decoder. SmallCap can transfer to new domains without additional finetuning and exploit large-scale data in a training-free fashion because the contents of the datastore can be readily replaced. Our experiments show that SmallCap, trained only on COCO, has competitive performance on this benchmark, and also transfers to other domains without retraining, solely through retrieval from target-domain data. Further improvement is achieved through the training-free exploitation of diverse human-labeled and web data, which proves effective for other domains, including the nocaps image captioning benchmark, designed to test generalization to unseen visual concepts.