 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan, Attend, Generate: Character-level Neural Machine Translation with Planning in the Decoder
Jun 23, 2017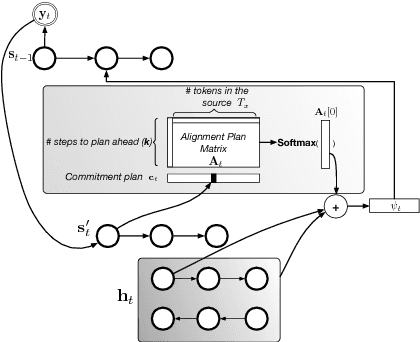
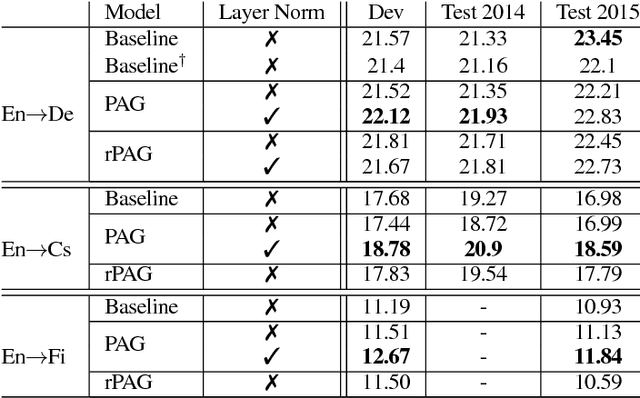
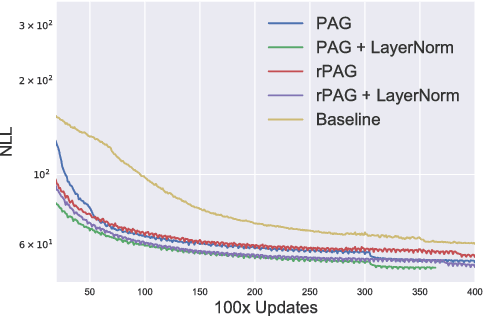

We investigate the integration of a planning mechanism into an encoder-decoder architecture with an explicit alignment for character-level machine translation. We develop a model that plans ahead when it computes alignments between the source and target sequences, constructing a matrix of proposed future alignments and a commitment vector that governs whether to follow or recompute the plan. This mechanism is inspired by the strategic attentive reader and writer (STRAW) model. Our proposed model is end-to-end trainable with fully differentiable operations. We show that it outperforms a strong baseline on three character-level decoder neural machine translation on WMT'15 corpus. Our analysis demonstrates that our model can compute qualitatively intuitive alignments and achieves superior performance with fewer parameters.
Deep Learning for Patient-Specific Kidney Graft Survival Analysis
May 29, 2017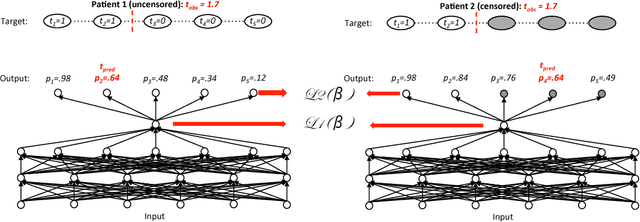
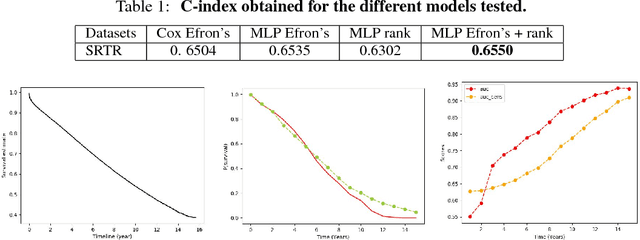
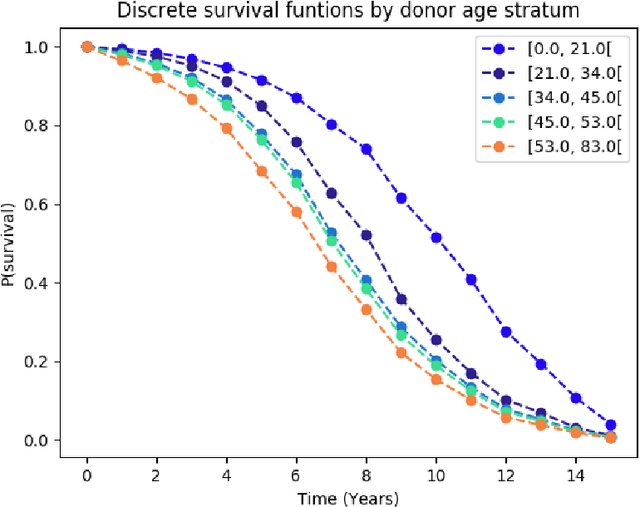
An accurate model of patient-specific kidney graft survival distributions can help to improve shared-decision making in the treatment and care of patients. In this paper, we propose a deep learning method that directly models the survival function instead of estimating the hazard function to predict survival times for graft patients based on the principle of multi-task learning. By learning to jointly predict the time of the event, and its rank in the cox partial log likelihood framework, our deep learning approach outperforms, in terms of survival time prediction quality and concordance index, other common methods for survival analysis, including the Cox Proportional Hazards model and a network trained on the cox partial log-likelihood.
Sharp Minima Can Generalize For Deep Nets
May 15, 2017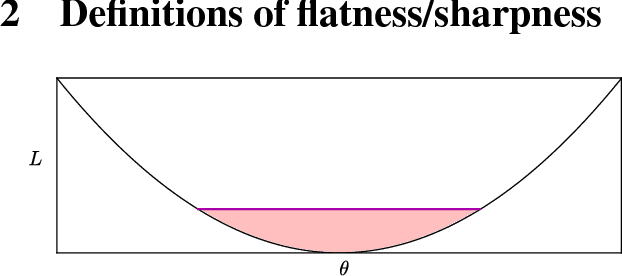
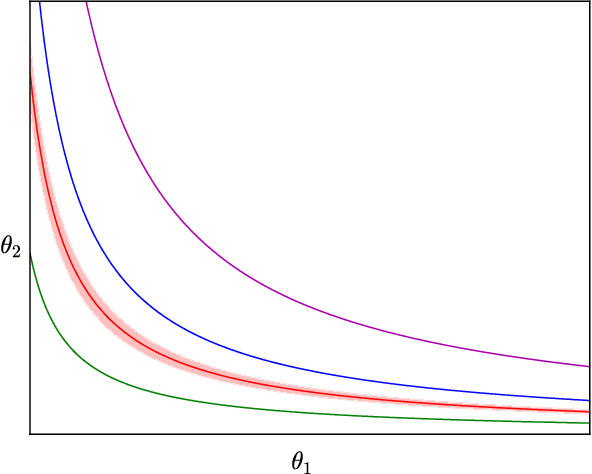
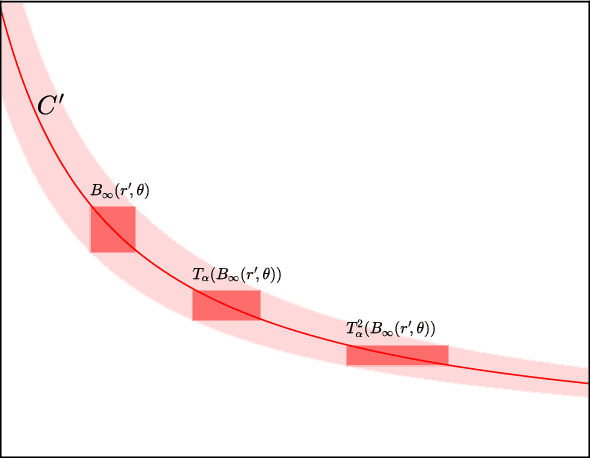
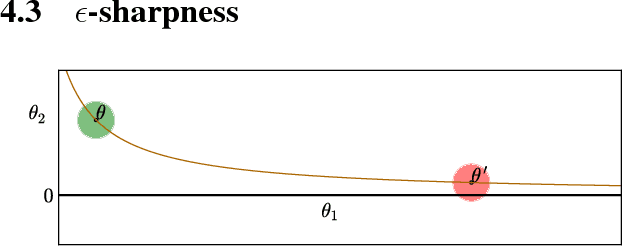
Despite their overwhelming capacity to overfit, deep learning architectures tend to generalize relatively well to unseen data, allowing them to be deployed in practice. However, explaining why this is the case is still an open area of research. One standing hypothesis that is gaining popularity, e.g. Hochreiter & Schmidhuber (1997); Keskar et al. (2017), is that the flatness of minima of the loss function found by stochastic gradient based methods results in good generalization. This paper argues that most notions of flatness are problematic for deep models and can not be directly applied to explain generalization. Specifically, when focusing on deep networks with rectifier units, we can exploit the particular geometry of parameter space induced by the inherent symmetries that these architectures exhibit to build equivalent models corresponding to arbitrarily sharper minima. Furthermore, if we allow to reparametrize a function, the geometry of its parameters can change drastically without affecting its generalization properties.
Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
Apr 12, 2017

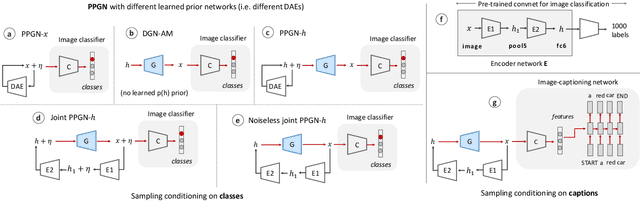

Generating high-resolution, photo-realistic images has been a long-standing goal in machine learning. Recently, Nguyen et al. (2016) showed one interesting way to synthesize novel images by performing gradient ascent in the latent space of a generator network to maximize the activations of one or multiple neurons in a separate classifier network. In this paper we extend this method by introducing an additional prior on the latent code, improving both sample quality and sample diversity, leading to a state-of-the-art generative model that produces high quality images at higher resolutions (227x227) than previous generative models, and does so for all 1000 ImageNet categories. In addition, we provide a unified probabilistic interpretation of related activation maximization methods and call the general class of models "Plug and Play Generative Networks". PPGNs are composed of 1) a generator network G that is capable of drawing a wide range of image types and 2) a replaceable "condition" network C that tells the generator what to draw. We demonstrate the generation of images conditioned on a class (when C is an ImageNet or MIT Places classification network) and also conditioned on a caption (when C is an image captioning network). Our method also improves the state of the art of Multifaceted Feature Visualization, which generates the set of synthetic inputs that activate a neuron in order to better understand how deep neural networks operate. Finally, we show that our model performs reasonably well at the task of image inpainting. While image models are used in this paper, the approach is modality-agnostic and can be applied to many types of data.
Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation
Mar 28, 2017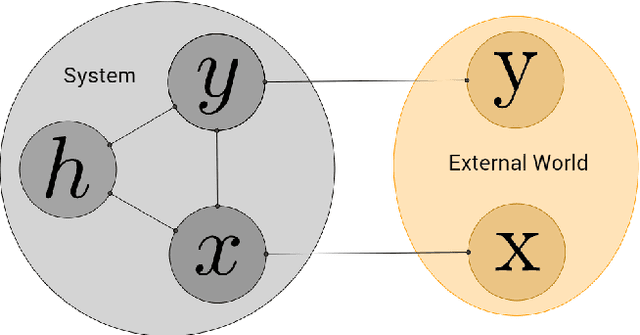
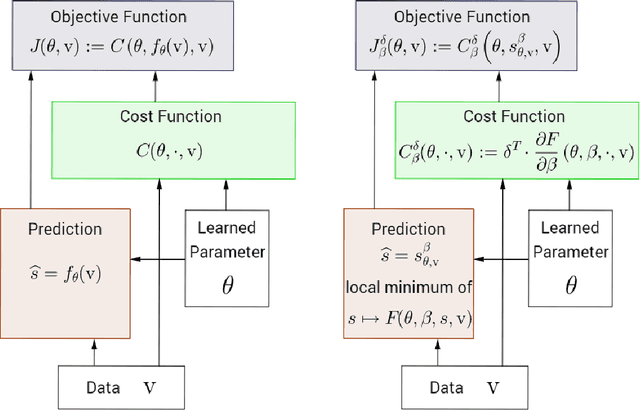
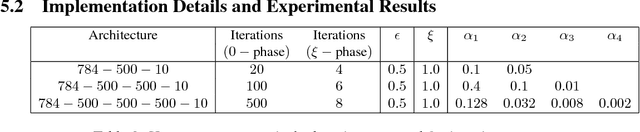
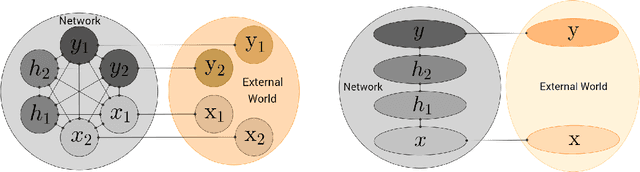
We introduce Equilibrium Propagation, a learning framework for energy-based models. It involves only one kind of neural computation, performed in both the first phase (when the prediction is made) and the second phase of training (after the target or prediction error is revealed). Although this algorithm computes the gradient of an objective function just like Backpropagation, it does not need a special computation or circuit for the second phase, where errors are implicitly propagated. Equilibrium Propagation shares similarities with Contrastive Hebbian Learning and Contrastive Divergence while solving the theoretical issues of both algorithms: our algorithm computes the gradient of a well defined objective function. Because the objective function is defined in terms of local perturbations, the second phase of Equilibrium Propagation corresponds to only nudging the prediction (fixed point, or stationary distribution) towards a configuration that reduces prediction error. In the case of a recurrent multi-layer supervised network, the output units are slightly nudged towards their target in the second phase, and the perturbation introduced at the output layer propagates backward in the hidden layers. We show that the signal 'back-propagated' during this second phase corresponds to the propagation of error derivatives and encodes the gradient of the objective function, when the synaptic update corresponds to a standard form of spike-timing dependent plasticity. This work makes it more plausible that a mechanism similar to Backpropagation could be implemented by brains, since leaky integrator neural computation performs both inference and error back-propagation in our model. The only local difference between the two phases is whether synaptic changes are allowed or not.
Batch-normalized joint training for DNN-based distant speech recognition
Mar 24, 2017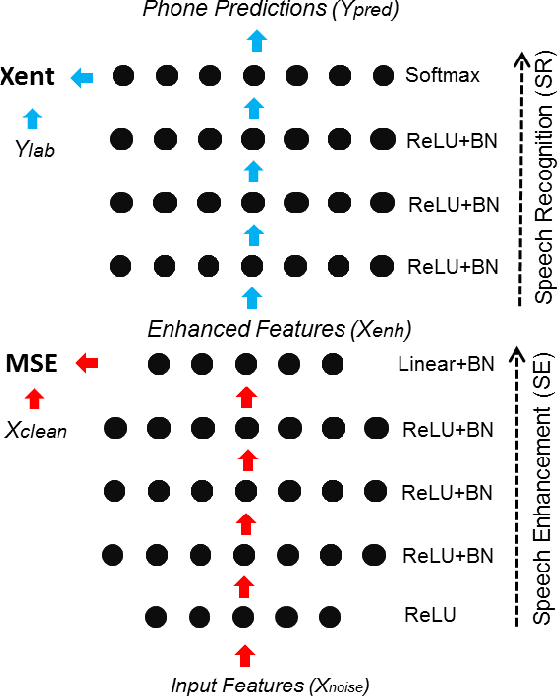
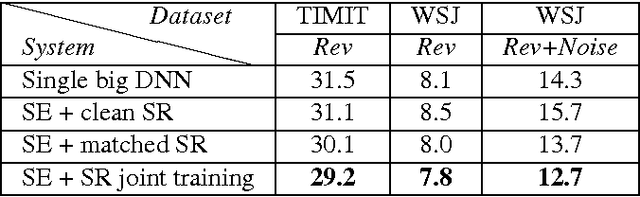
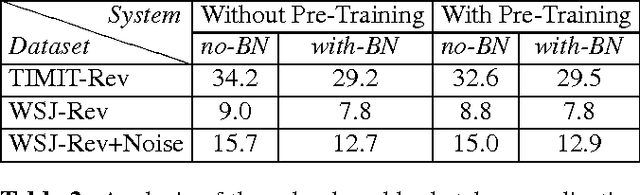
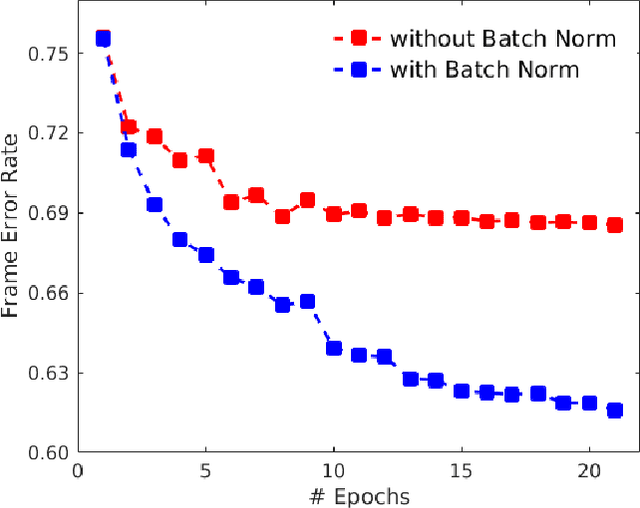
Improving distant speech recognition is a crucial step towards flexible human-machine interfaces. Current technology, however, still exhibits a lack of robustness, especially when adverse acoustic conditions are met. Despite the significant progress made in the last years on both speech enhancement and speech recognition, one potential limitation of state-of-the-art technology lies in composing modules that are not well matched because they are not trained jointly. To address this concern, a promising approach consists in concatenating a speech enhancement and a speech recognition deep neural network and to jointly update their parameters as if they were within a single bigger network. Unfortunately, joint training can be difficult because the output distribution of the speech enhancement system may change substantially during the optimization procedure. The speech recognition module would have to deal with an input distribution that is non-stationary and unnormalized. To mitigate this issue, we propose a joint training approach based on a fully batch-normalized architecture. Experiments, conducted using different datasets, tasks and acoustic conditions, revealed that the proposed framework significantly overtakes other competitive solutions, especially in challenging environments.
A network of deep neural networks for distant speech recognition
Mar 23, 2017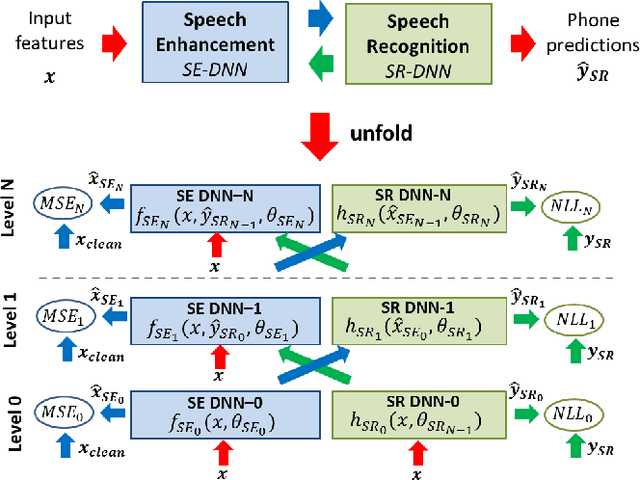
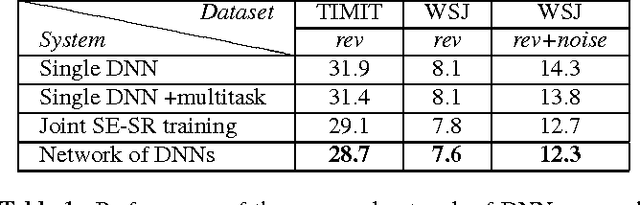
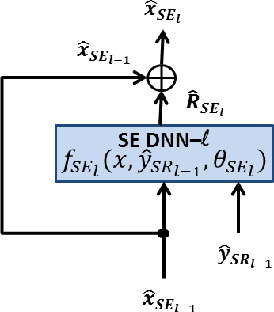

Despite the remarkable progress recently made in distant speech recognition, state-of-the-art technology still suffers from a lack of robustness, especially when adverse acoustic conditions characterized by non-stationary noises and reverberation are met. A prominent limitation of current systems lies in the lack of matching and communication between the various technologies involved in the distant speech recognition process. The speech enhancement and speech recognition modules are, for instance, often trained independently. Moreover, the speech enhancement normally helps the speech recognizer, but the output of the latter is not commonly used, in turn, to improve the speech enhancement. To address both concerns, we propose a novel architecture based on a network of deep neural networks, where all the components are jointly trained and better cooperate with each other thanks to a full communication scheme between them. Experiments, conducted using different datasets, tasks and acoustic conditions, revealed that the proposed framework can overtake other competitive solutions, including recent joint training approaches.
Independently Controllable Features
Mar 22, 2017
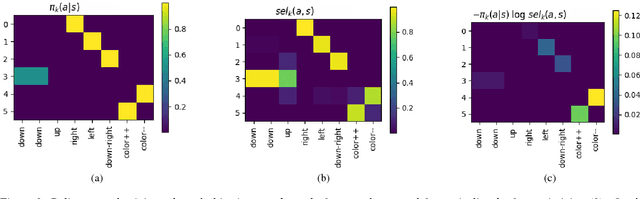
Finding features that disentangle the different causes of variation in real data is a difficult task, that has nonetheless received considerable attention in static domains like natural images. Interactive environments, in which an agent can deliberately take actions, offer an opportunity to tackle this task better, because the agent can experiment with different actions and observe their effects. We introduce the idea that in interactive environments, latent factors that control the variation in observed data can be identified by figuring out what the agent can control. We propose a naive method to find factors that explain or measure the effect of the actions of a learner, and test it in illustrative experiments.
Dynamic Neural Turing Machine with Soft and Hard Addressing Schemes
Mar 17, 2017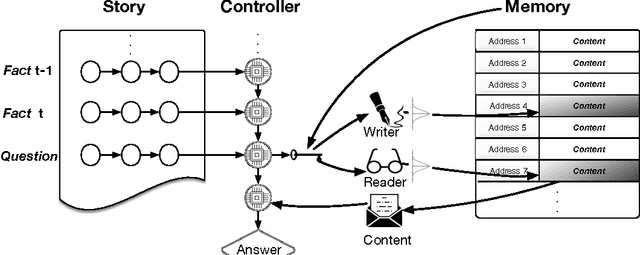
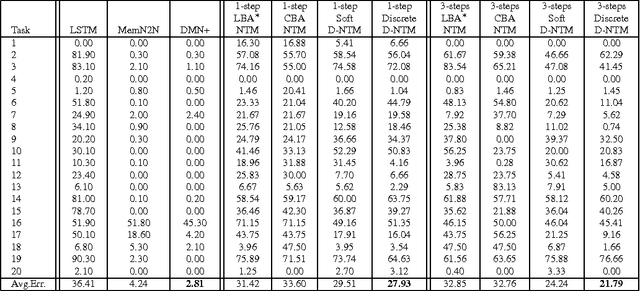
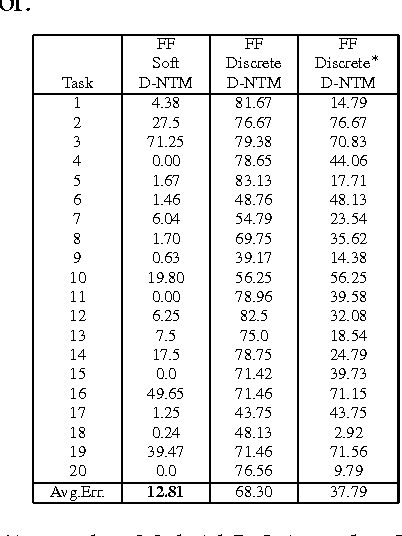
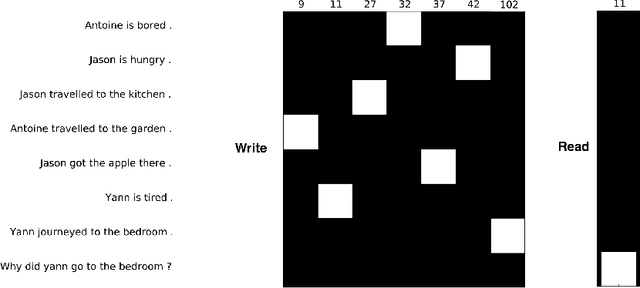
We extend neural Turing machine (NTM) model into a dynamic neural Turing machine (D-NTM) by introducing a trainable memory addressing scheme. This addressing scheme maintains for each memory cell two separate vectors, content and address vectors. This allows the D-NTM to learn a wide variety of location-based addressing strategies including both linear and nonlinear ones. We implement the D-NTM with both continuous, differentiable and discrete, non-differentiable read/write mechanisms. We investigate the mechanisms and effects of learning to read and write into a memory through experiments on Facebook bAbI tasks using both a feedforward and GRUcontroller. The D-NTM is evaluated on a set of Facebook bAbI tasks and shown to outperform NTM and LSTM baselines. We have done extensive analysis of our model and different variations of NTM on bAbI task. We also provide further experimental results on sequential pMNIST, Stanford Natural Language Inference, associative recall and copy tasks.
Diet Networks: Thin Parameters for Fat Genomics
Mar 16, 2017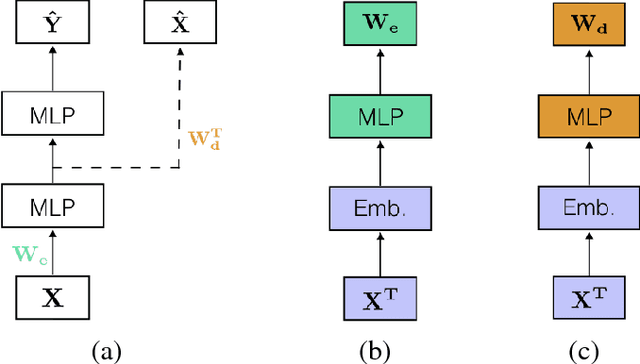
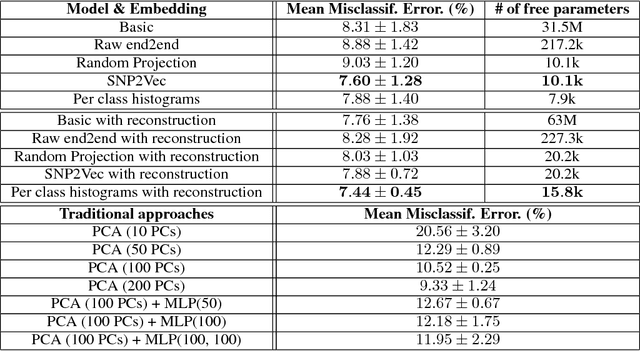
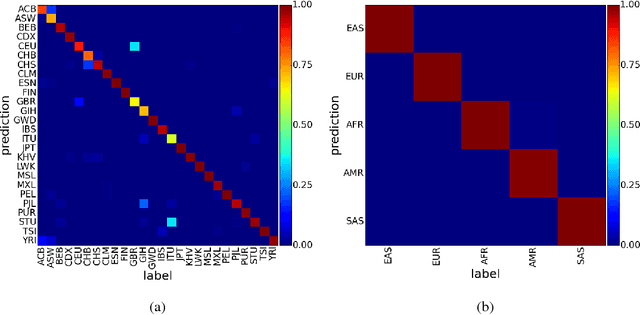
Learning tasks such as those involving genomic data often poses a serious challenge: the number of input features can be orders of magnitude larger than the number of training examples, making it difficult to avoid overfitting, even when using the known regularization techniques. We focus here on tasks in which the input is a description of the genetic variation specific to a patient, the single nucleotide polymorphisms (SNPs), yielding millions of ternary inputs. Improving the ability of deep learning to handle such datasets could have an important impact in precision medicine, where high-dimensional data regarding a particular patient is used to make predictions of interest. Even though the amount of data for such tasks is increasing, this mismatch between the number of examples and the number of inputs remains a concern. Naive implementations of classifier neural networks involve a huge number of free parameters in their first layer: each input feature is associated with as many parameters as there are hidden units. We propose a novel neural network parametrization which considerably reduces the number of free parameters. It is based on the idea that we can first learn or provide a distributed representation for each input feature (e.g. for each position in the genome where variations are observed), and then learn (with another neural network called the parameter prediction network) how to map a feature's distributed representation to the vector of parameters specific to that feature in the classifier neural network (the weights which link the value of the feature to each of the hidden units). We show experimentally on a population stratification task of interest to medical studies that the proposed approach can significantly reduce both the number of parameters and the error rate of the classifier.