 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
Jun 20, 2018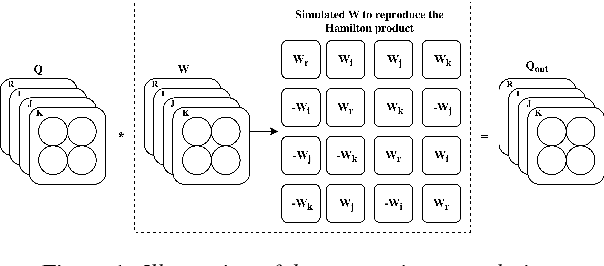
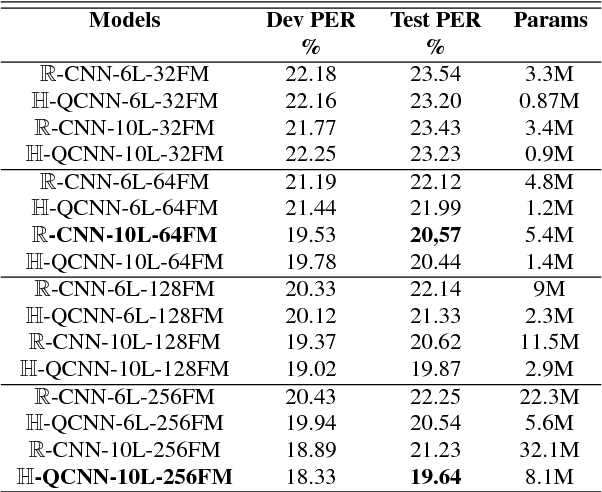
Recently, the connectionist temporal classification (CTC) model coupled with recurrent (RNN) or convolutional neural networks (CNN), made it easier to train speech recognition systems in an end-to-end fashion. However in real-valued models, time frame components such as mel-filter-bank energies and the cepstral coefficients obtained from them, together with their first and second order derivatives, are processed as individual elements, while a natural alternative is to process such components as composed entities. We propose to group such elements in the form of quaternions and to process these quaternions using the established quaternion algebra. Quaternion numbers and quaternion neural networks have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with less learning parameters than real-valued models. This paper proposes to integrate multiple feature views in quaternion-valued convolutional neural network (QCNN), to be used for sequence-to-sequence mapping with the CTC model. Promising results are reported using simple QCNNs in phoneme recognition experiments with the TIMIT corpus. More precisely, QCNNs obtain a lower phoneme error rate (PER) with less learning parameters than a competing model based on real-valued CNNs.
Towards Gene Expression Convolutions using Gene Interaction Graphs
Jun 18, 2018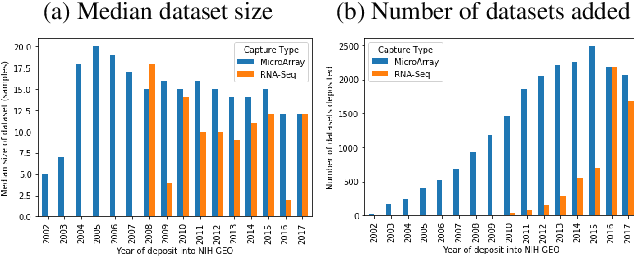
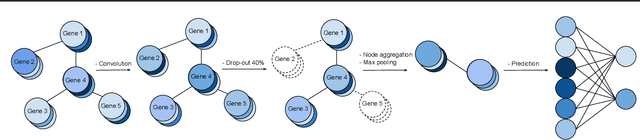
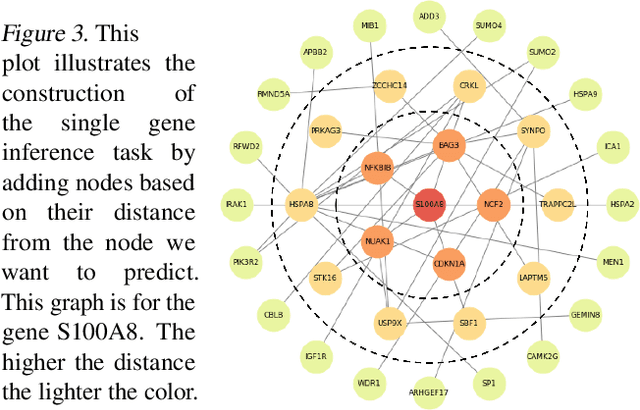
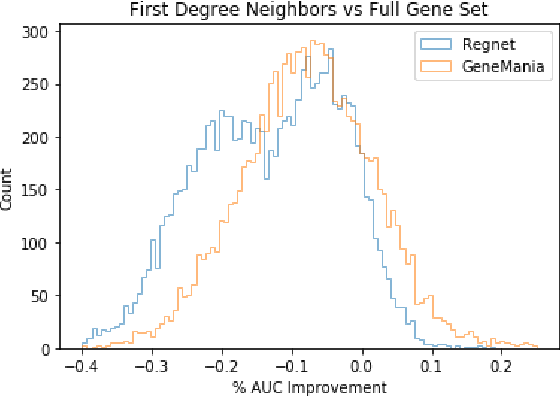
We study the challenges of applying deep learning to gene expression data. We find experimentally that there exists non-linear signal in the data, however is it not discovered automatically given the noise and low numbers of samples used in most research. We discuss how gene interaction graphs (same pathway, protein-protein, co-expression, or research paper text association) can be used to impose a bias on a deep model similar to the spatial bias imposed by convolutions on an image. We explore the usage of Graph Convolutional Neural Networks coupled with dropout and gene embeddings to utilize the graph information. We find this approach provides an advantage for particular tasks in a low data regime but is very dependent on the quality of the graph used. We conclude that more work should be done in this direction. We design experiments that show why existing methods fail to capture signal that is present in the data when features are added which clearly isolates the problem that needs to be addressed.
Modularity Matters: Learning Invariant Relational Reasoning Tasks
Jun 18, 2018
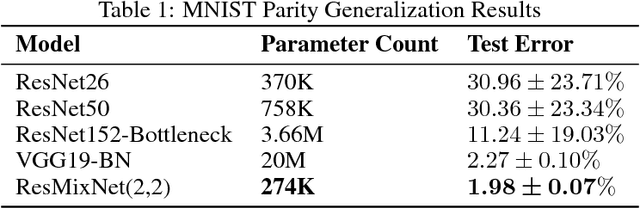

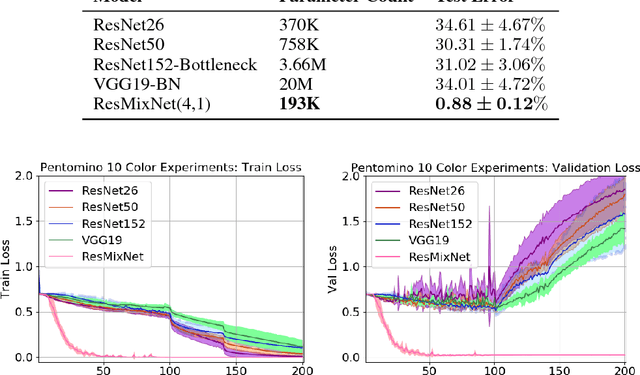
We focus on two supervised visual reasoning tasks whose labels encode a semantic relational rule between two or more objects in an image: the MNIST Parity task and the colorized Pentomino task. The objects in the images undergo random translation, scaling, rotation and coloring transformations. Thus these tasks involve invariant relational reasoning. We report uneven performance of various deep CNN models on these two tasks. For the MNIST Parity task, we report that the VGG19 model soundly outperforms a family of ResNet models. Moreover, the family of ResNet models exhibits a general sensitivity to random initialization for the MNIST Parity task. For the colorized Pentomino task, now both the VGG19 and ResNet models exhibit sluggish optimization and very poor test generalization, hovering around 30% test error. The CNN we tested all learn hierarchies of fully distributed features and thus encode the distributed representation prior. We are motivated by a hypothesis from cognitive neuroscience which posits that the human visual cortex is modularized, and this allows the visual cortex to learn higher order invariances. To this end, we consider a modularized variant of the ResNet model, referred to as a Residual Mixture Network (ResMixNet) which employs a mixture-of-experts architecture to interleave distributed representations with more specialized, modular representations. We show that very shallow ResMixNets are capable of learning each of the two tasks well, attaining less than 2% and 1% test error on the MNIST Parity and the colorized Pentomino tasks respectively. Most importantly, the ResMixNet models are extremely parameter efficient: generalizing better than various non-modular CNNs that have over 10x the number of parameters. These experimental results support the hypothesis that modularity is a robust prior for learning invariant relational reasoning.
Focused Hierarchical RNNs for Conditional Sequence Processing
Jun 12, 2018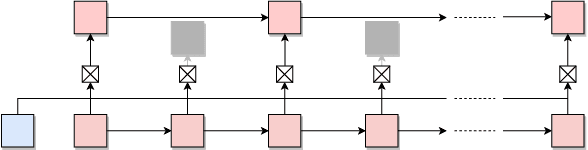
Recurrent Neural Networks (RNNs) with attention mechanisms have obtained state-of-the-art results for many sequence processing tasks. Most of these models use a simple form of encoder with attention that looks over the entire sequence and assigns a weight to each token independently. We present a mechanism for focusing RNN encoders for sequence modelling tasks which allows them to attend to key parts of the input as needed. We formulate this using a multi-layer conditional sequence encoder that reads in one token at a time and makes a discrete decision on whether the token is relevant to the context or question being asked. The discrete gating mechanism takes in the context embedding and the current hidden state as inputs and controls information flow into the layer above. We train it using policy gradient methods. We evaluate this method on several types of tasks with different attributes. First, we evaluate the method on synthetic tasks which allow us to evaluate the model for its generalization ability and probe the behavior of the gates in more controlled settings. We then evaluate this approach on large scale Question Answering tasks including the challenging MS MARCO and SearchQA tasks. Our models shows consistent improvements for both tasks over prior work and our baselines. It has also shown to generalize significantly better on synthetic tasks as compared to the baselines.
Twin Regularization for online speech recognition
Jun 12, 2018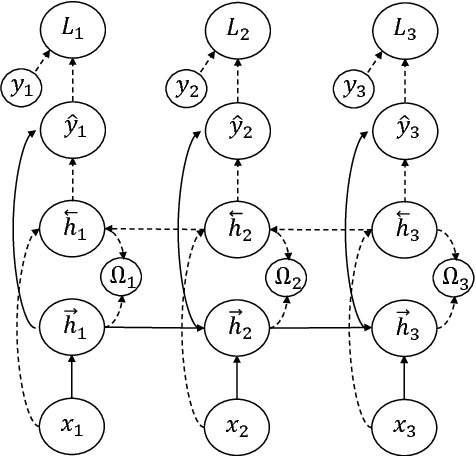
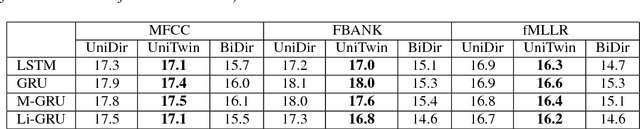
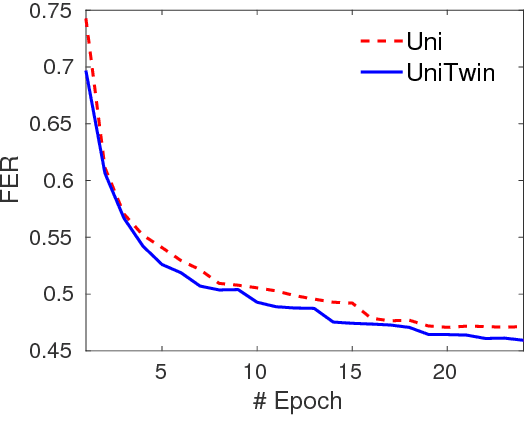
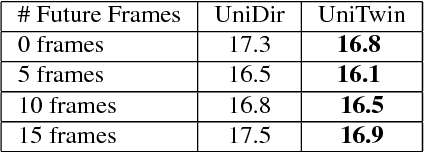
Online speech recognition is crucial for developing natural human-machine interfaces. This modality, however, is significantly more challenging than off-line ASR, since real-time/low-latency constraints inevitably hinder the use of future information, that is known to be very helpful to perform robust predictions. A popular solution to mitigate this issue consists of feeding neural acoustic models with context windows that gather some future frames. This introduces a latency which depends on the number of employed look-ahead features. This paper explores a different approach, based on estimating the future rather than waiting for it. Our technique encourages the hidden representations of a unidirectional recurrent network to embed some useful information about the future. Inspired by a recently proposed technique called Twin Networks, we add a regularization term that forces forward hidden states to be as close as possible to cotemporal backward ones, computed by a "twin" neural network running backwards in time. The experiments, conducted on a number of datasets, recurrent architectures, input features, and acoustic conditions, have shown the effectiveness of this approach. One important advantage is that our method does not introduce any additional computation at test time if compared to standard unidirectional recurrent networks.
Straight to the Tree: Constituency Parsing with Neural Syntactic Distance
Jun 11, 2018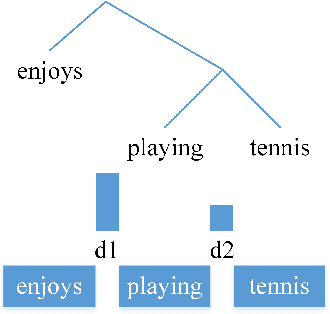
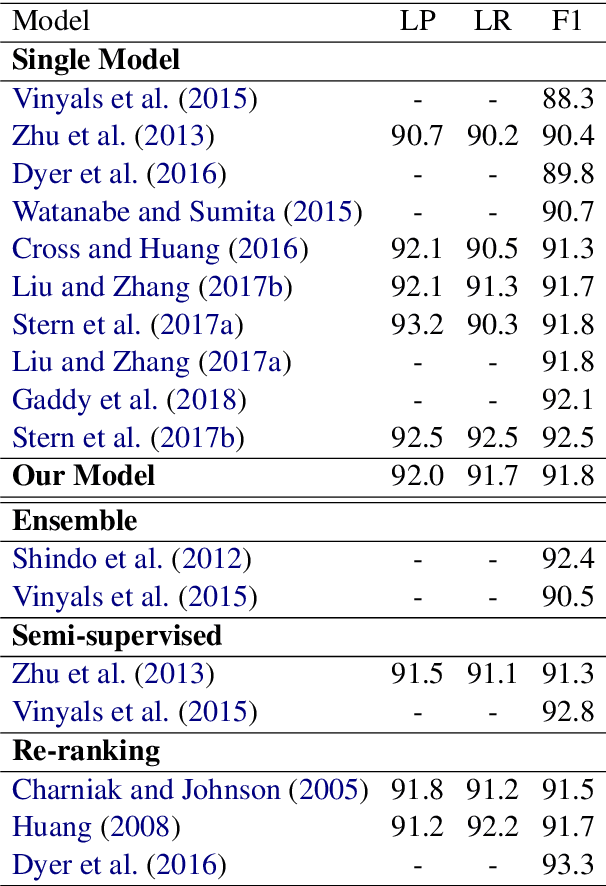

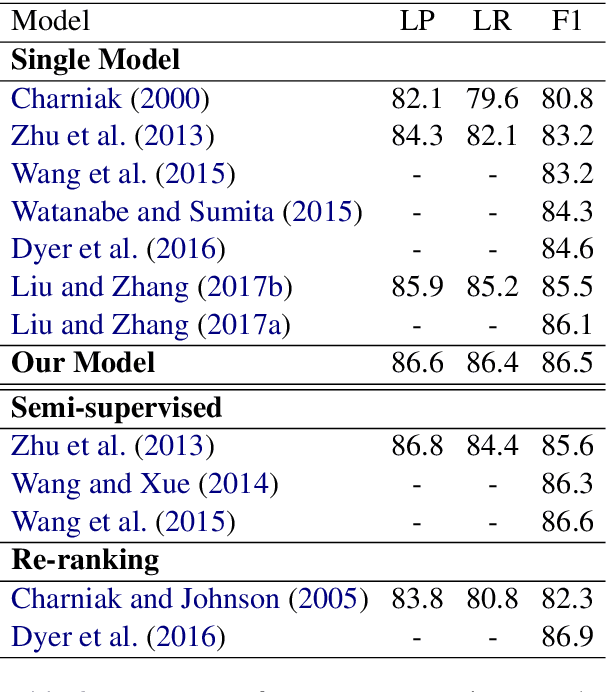
In this work, we propose a novel constituency parsing scheme. The model predicts a vector of real-valued scalars, named syntactic distances, for each split position in the input sentence. The syntactic distances specify the order in which the split points will be selected, recursively partitioning the input, in a top-down fashion. Compared to traditional shift-reduce parsing schemes, our approach is free from the potential problem of compounding errors, while being faster and easier to parallelize. Our model achieves competitive performance amongst single model, discriminative parsers in the PTB dataset and outperforms previous models in the CTB dataset.
Learning to rank for censored survival data
Jun 08, 2018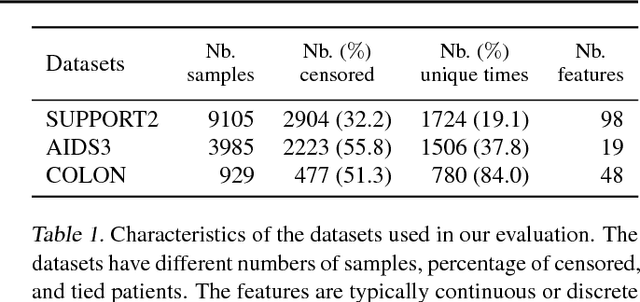
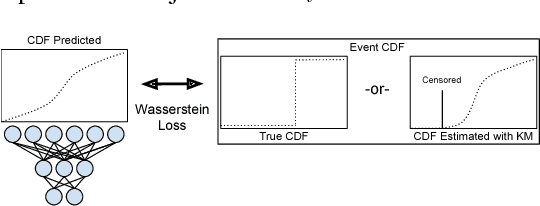
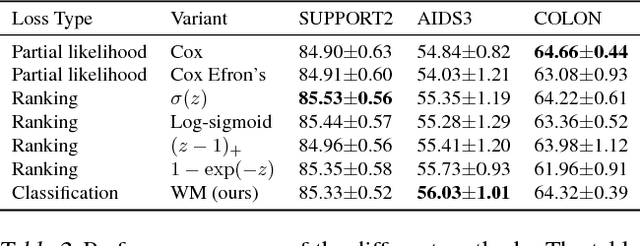
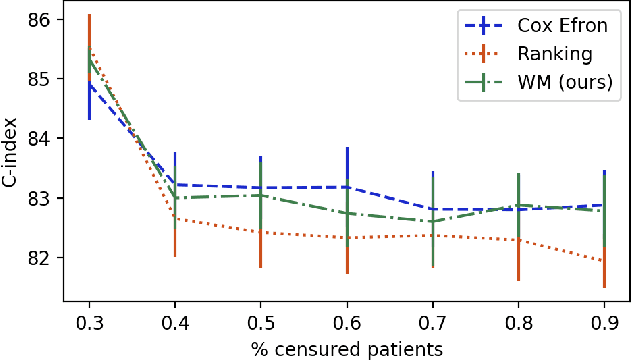
Survival analysis is a type of semi-supervised ranking task where the target output (the survival time) is often right-censored. Utilizing this information is a challenge because it is not obvious how to correctly incorporate these censored examples into a model. We study how three categories of loss functions, namely partial likelihood methods, rank methods, and our classification method based on a Wasserstein metric (WM) and the non-parametric Kaplan Meier estimate of the probability density to impute the labels of censored examples, can take advantage of this information. The proposed method allows us to have a model that predict the probability distribution of an event. If a clinician had access to the detailed probability of an event over time this would help in treatment planning. For example, determining if the risk of kidney graft rejection is constant or peaked after some time. Also, we demonstrate that this approach directly optimizes the expected C-index which is the most common evaluation metric for ranking survival models.
MINE: Mutual Information Neural Estimation
Jun 07, 2018


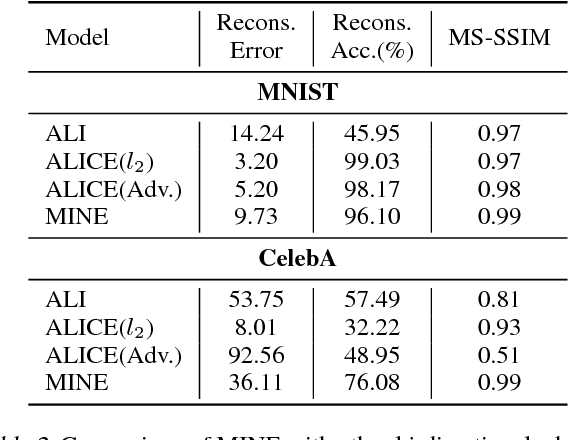
We argue that the estimation of mutual information between high dimensional continuous random variables can be achieved by gradient descent over neural networks. We present a Mutual Information Neural Estimator (MINE) that is linearly scalable in dimensionality as well as in sample size, trainable through back-prop, and strongly consistent. We present a handful of applications on which MINE can be used to minimize or maximize mutual information. We apply MINE to improve adversarially trained generative models. We also use MINE to implement Information Bottleneck, applying it to supervised classification; our results demonstrate substantial improvement in flexibility and performance in these settings.
* 19 pages, 6 figures
Neural Models for Key Phrase Detection and Question Generation
May 30, 2018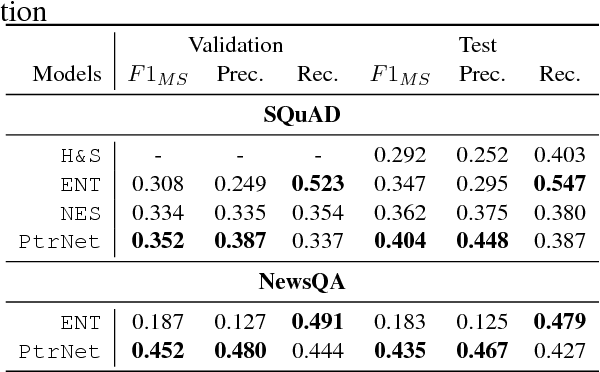


We propose a two-stage neural model to tackle question generation from documents. First, our model estimates the probability that word sequences in a document are ones that a human would pick when selecting candidate answers by training a neural key-phrase extractor on the answers in a question-answering corpus. Predicted key phrases then act as target answers and condition a sequence-to-sequence question-generation model with a copy mechanism. Empirically, our key-phrase extraction model significantly outperforms an entity-tagging baseline and existing rule-based approaches. We further demonstrate that our question generation system formulates fluent, answerable questions from key phrases. This two-stage system could be used to augment or generate reading comprehension datasets, which may be leveraged to improve machine reading systems or in educational settings.
A Walk with SGD
May 30, 2018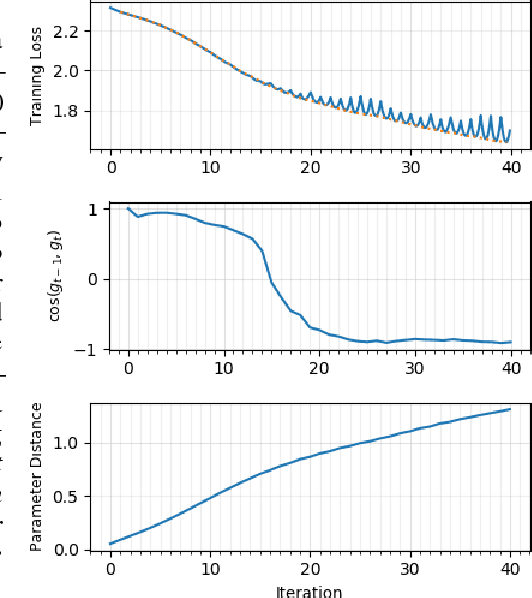
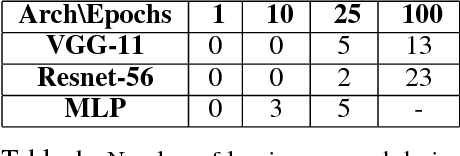
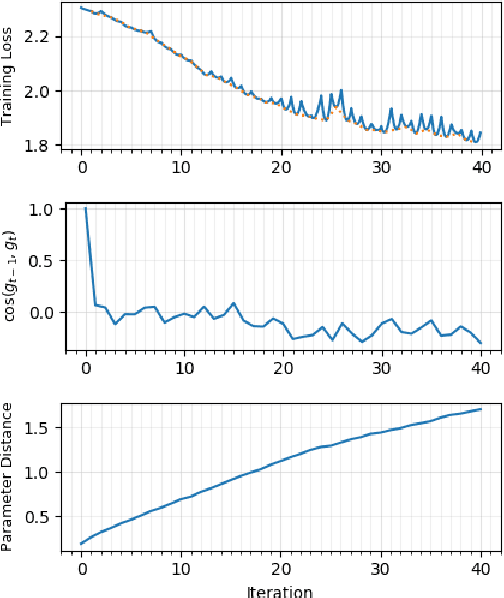
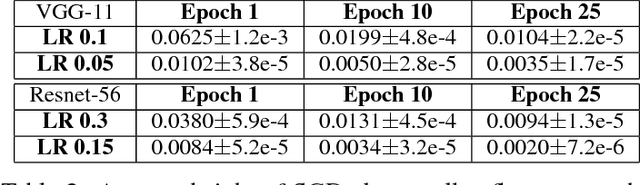
We present novel empirical observations regarding how stochastic gradient descent (SGD) navigates the loss landscape of over-parametrized deep neural networks (DNNs). These observations expose the qualitatively different roles of learning rate and batch-size in DNN optimization and generalization. Specifically we study the DNN loss surface along the trajectory of SGD by interpolating the loss surface between parameters from consecutive \textit{iterations} and tracking various metrics during training. We find that the loss interpolation between parameters before and after each training iteration's update is roughly convex with a minimum (\textit{valley floor}) in between for most of the training. Based on this and other metrics, we deduce that for most of the training update steps, SGD moves in valley like regions of the loss surface by jumping from one valley wall to another at a height above the valley floor. This 'bouncing between walls at a height' mechanism helps SGD traverse larger distance for small batch sizes and large learning rates which we find play qualitatively different roles in the dynamics. While a large learning rate maintains a large height from the valley floor, a small batch size injects noise facilitating exploration. We find this mechanism is crucial for generalization because the valley floor has barriers and this exploration above the valley floor allows SGD to quickly travel far away from the initialization point (without being affected by barriers) and find flatter regions, corresponding to better generalization.