 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Mar 05, 2020
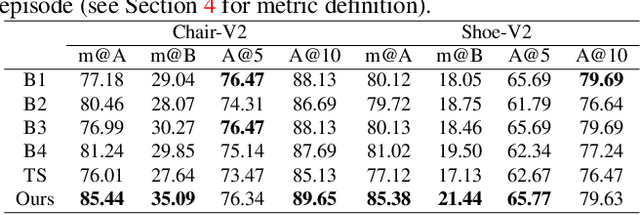
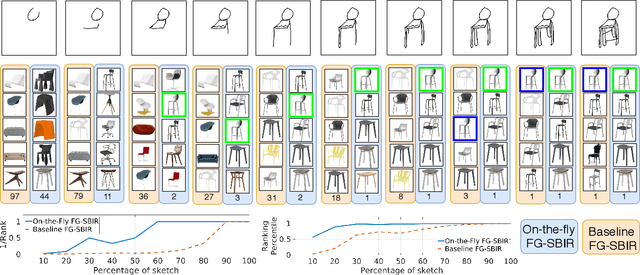
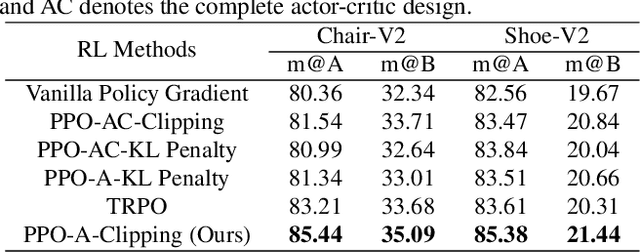
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
Learning Generalisable Omni-Scale Representations for Person Re-Identification
Oct 22, 2019
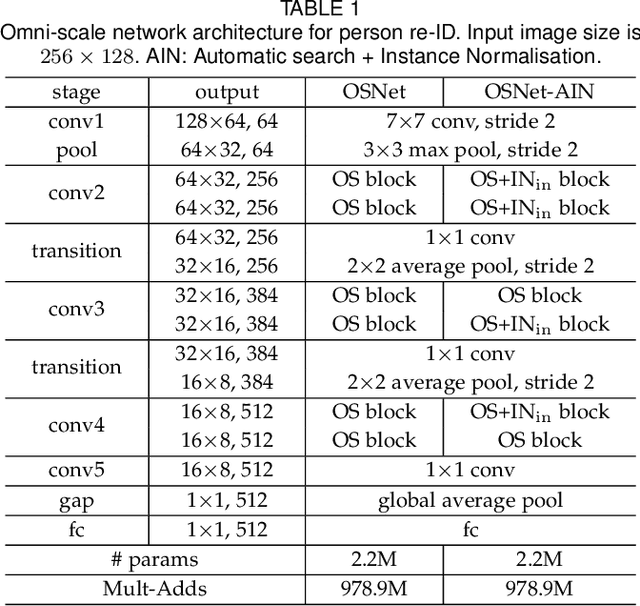
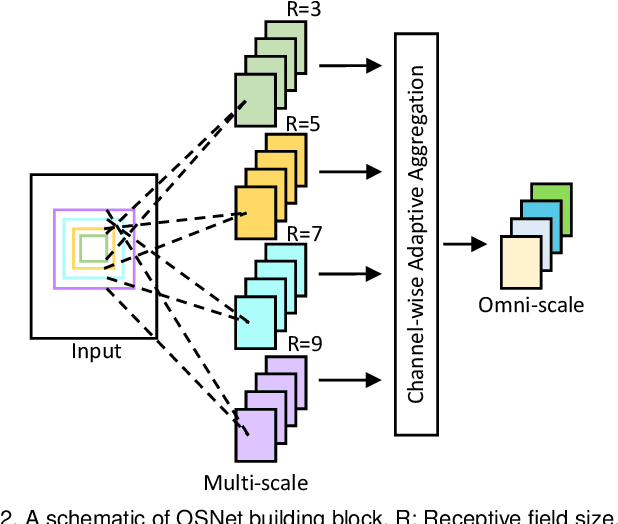
An effective person re-identification (re-ID) model should learn feature representations that are both discriminative, for distinguishing similar-looking people, and generalisable, for deployment across datasets without any adaptation. In this paper, we develop novel CNN architectures to address both challenges. First, we present a re-ID CNN termed omni-scale network (OSNet) to learn features that not only capture different spatial scales but also encapsulate a synergistic combination of multiple scales, namely omni-scale features. The basic building block consists of multiple convolutional streams, each detecting features at a certain scale. For omni-scale feature learning, a unified aggregation gate is introduced to dynamically fuse multi-scale features with channel-wise weights. OSNet is lightweight as its building blocks comprise factorised convolutions. Second, to improve generalisable feature learning, we introduce instance normalisation (IN) layers into OSNet to cope with cross-dataset discrepancies. Further, to determine the optimal placements of these IN layers in the architecture, we formulate an efficient differentiable architecture search algorithm. Extensive experiments show that, in the conventional same-dataset setting, OSNet achieves state-of-the-art performance, despite being much smaller than existing re-ID models. In the more challenging yet practical cross-dataset setting, OSNet beats most recent unsupervised domain adaptation methods without requiring any target data for model adaptation. Our code and models are released at \texttt{https://github.com/KaiyangZhou/deep-person-reid}.
Deep clustering with concrete k-means
Oct 17, 2019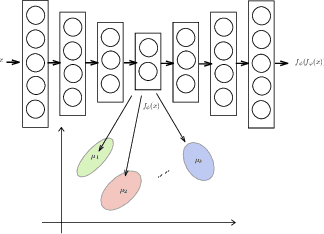
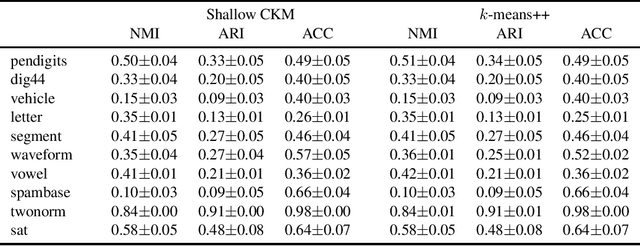
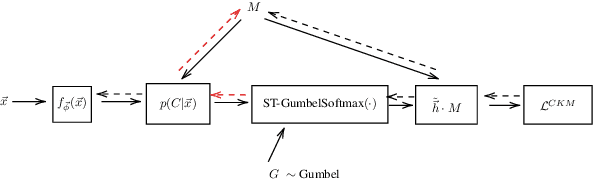

We address the problem of simultaneously learning a k-means clustering and deep feature representation from unlabelled data, which is of interest due to the potential of deep k-means to outperform traditional two-step feature extraction and shallow-clustering strategies. We achieve this by developing a gradient-estimator for the non-differentiable k-means objective via the Gumbel-Softmax reparameterisation trick. In contrast to previous attempts at deep clustering, our concrete k-means model can be optimised with respect to the canonical k-means objective and is easily trained end-to-end without resorting to alternating optimisation. We demonstrate the efficacy of our method on standard clustering benchmarks.
Goal-Driven Sequential Data Abstraction
Aug 08, 2019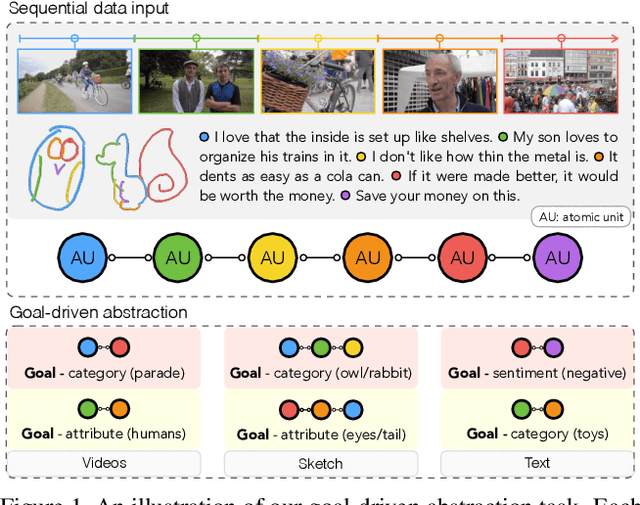
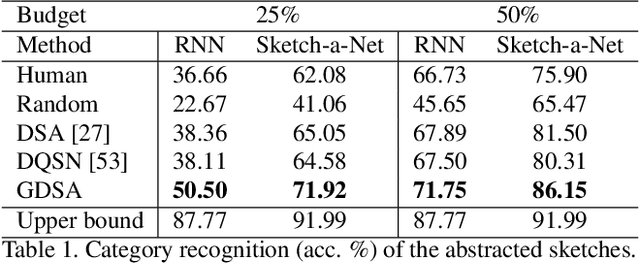
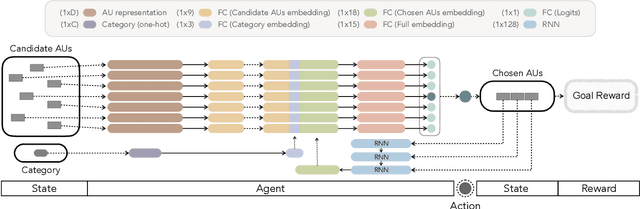
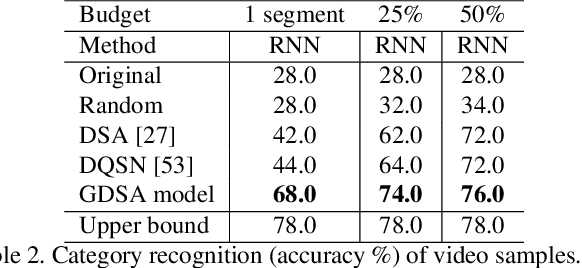
Automatic data abstraction is an important capability for both benchmarking machine intelligence and supporting summarization applications. In the former one asks whether a machine can `understand' enough about the meaning of input data to produce a meaningful but more compact abstraction. In the latter this capability is exploited for saving space or human time by summarizing the essence of input data. In this paper we study a general reinforcement learning based framework for learning to abstract sequential data in a goal-driven way. The ability to define different abstraction goals uniquely allows different aspects of the input data to be preserved according to the ultimate purpose of the abstraction. Our reinforcement learning objective does not require human-defined examples of ideal abstraction. Importantly our model processes the input sequence holistically without being constrained by the original input order. Our framework is also domain agnostic -- we demonstrate applications to sketch, video and text data and achieve promising results in all domains.
Gated deep neural networks for implied volatility surfaces
May 26, 2019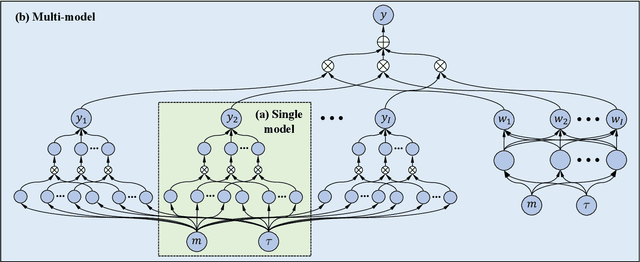
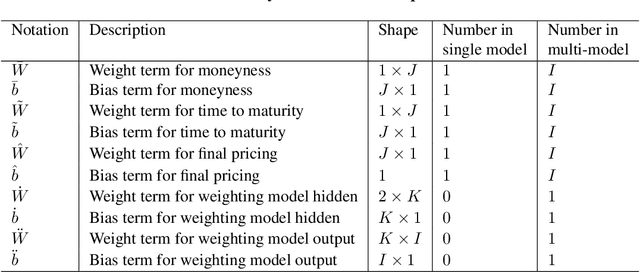
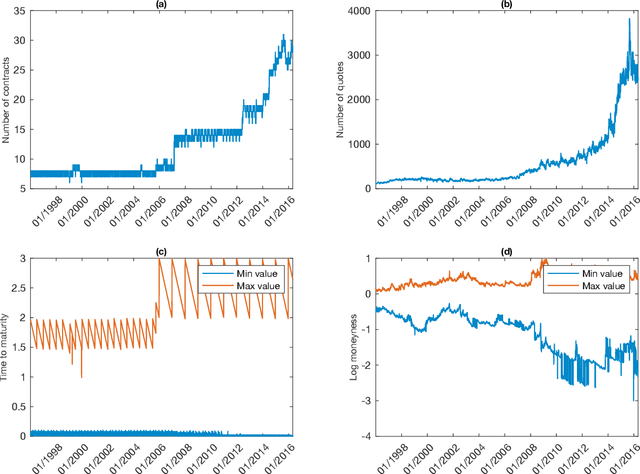
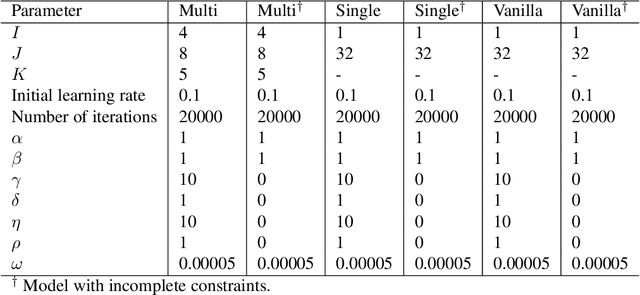
This paper presents a framework of developing neural networks for predicting implied volatility surfaces. Conventional financial conditions and empirical evidence related to the implied volatility are incorporated into the neural network architecture design and model training including no static arbitrage, boundaries, asymptotic slope and volatility smile. They are also satisfied empirically by the option data on the S&P 500 index over twenty years. The developed neural network model and its simplified variations outperform the widely used surface stochastic volatility inspired (SSVI) model on the mean average percentage error in both in-sample and out-of-sample datasets. This study has two main methodological contributions. First, an accurate deep learning prediction model is developed and tailored to implied volatility surfaces. Second, a framework, which seamlessly combines data-driven models with financial theories, can be extended and applied to solve other related business problems.
Omni-Scale Feature Learning for Person Re-Identification
May 02, 2019
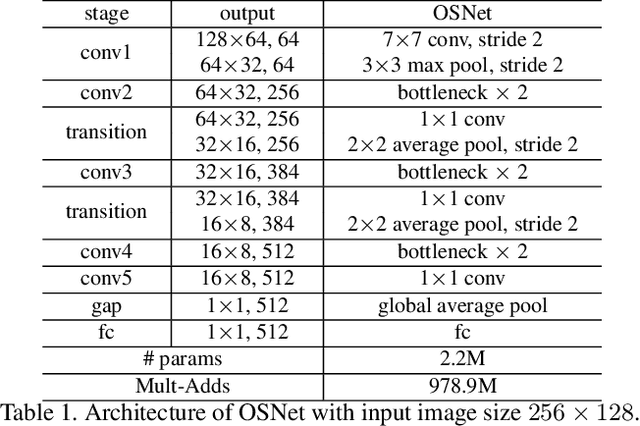
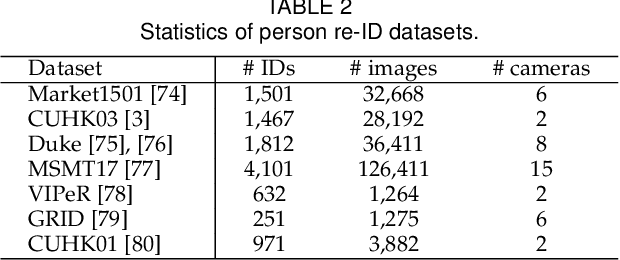
As an instance-level recognition problem, person re-identification (ReID) relies on discriminative features, which not only capture different spatial scales but also encapsulate an arbitrary combination of multiple scales. We call these features of both homogeneous and heterogeneous scales omni-scale features. In this paper, a novel deep CNN is designed, termed Omni-Scale Network (OSNet), for omni-scale feature learning in ReID. This is achieved by designing a residual block composed of multiple convolutional feature streams, each detecting features at a certain scale. Importantly, a novel unified aggregation gate is introduced to dynamically fuse multi-scale features with input-dependent channel-wise weights. To efficiently learn spatial-channel correlations and avoid overfitting, the building block uses both pointwise and depthwise convolutions. By stacking such blocks layer-by-layer, our OSNet is extremely lightweight and can be trained from scratch on existing ReID benchmarks. Despite its small model size, our OSNet achieves state-of-the-art performance on six person-ReID datasets.
Episodic Training for Domain Generalization
Jan 31, 2019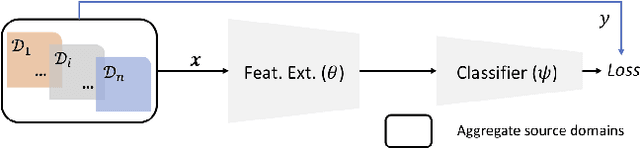
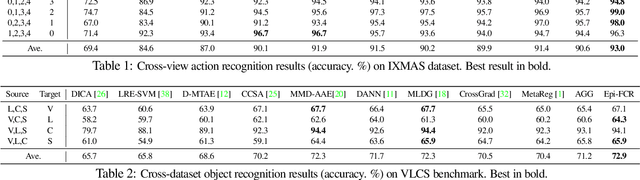
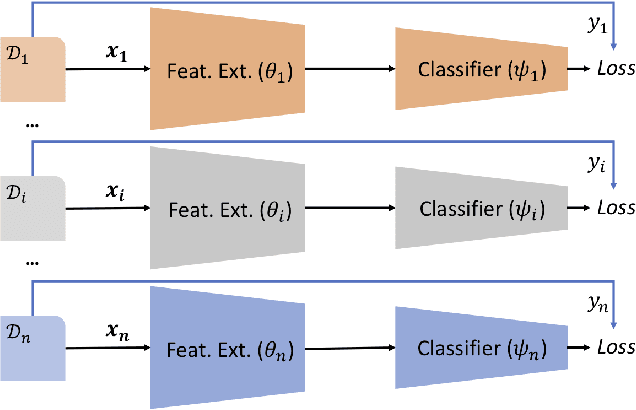
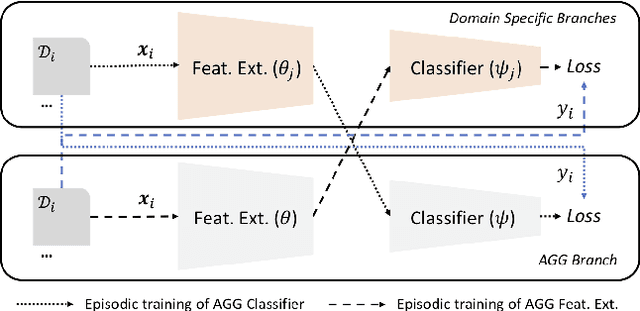
Domain generalization (DG) is the challenging and topical problem of learning models that generalize to novel testing domain with different statistics than a set of known training domains. The simple approach of aggregating data from all source domains and training a single deep neural network end-to-end on all the data provides a surprisingly strong baseline that surpasses many prior published methods. In this paper we build on this strong baseline by designing an episodic training procedure that trains a single deep network in a way that exposes it to the domain shift that characterises a novel domain at runtime. Specifically, we decompose a deep network into feature extractor and classifier components, and then train each component by simulating it interacting with a partner who is badly tuned for the current domain. This makes both components more robust, ultimately leading to our networks producing state-of-the-art performance on three DG benchmarks. As a demonstration, we consider the pervasive workflow of using an ImageNet trained CNN as a fixed feature extractor for downstream recognition tasks. Using the Visual Decathlon benchmark, we demonstrate that our episodic-DG training improves the performance of such a general purpose feature extractor by explicitly training it for robustness to novel problems. This provides the largest-scale demonstration of heterogeneous DG to date.
Feature-Critic Networks for Heterogeneous Domain Generalization
Jan 31, 2019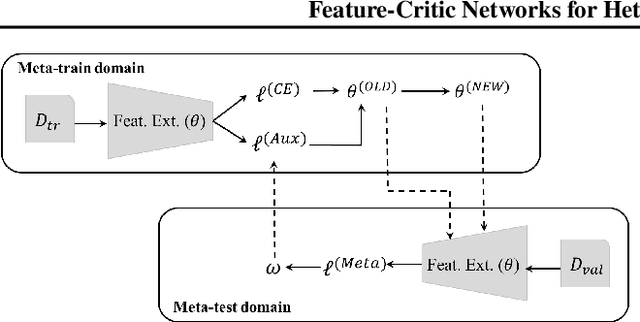


The well known domain shift issue causes model performance to degrade when deployed to a new target domain with different statistics to training. Domain adaptation techniques alleviate this, but need some instances from the target domain to drive adaptation. Domain generalization is the recently topical problem of learning a model that generalizes to unseen domains out of the box, without accessing any target data. Various domain generalization approaches aim to train a domain-invariant feature extractor, typically by adding some manually designed losses. In this work, we propose a learning to learn approach, where the auxiliary loss that helps generalization is itself learned. This approach is conceptually simple and flexible, and leads to considerable improvement in robustness to domain shift. Beyond conventional domain generalization, we consider a more challenging setting of heterogeneous domain generalization, where the unseen domains do not share label space with the seen ones, and the goal is to train a feature which is useful off-the-shelf for novel data and novel categories. Experimental evaluation demonstrates that our method outperforms state-of-the-art solutions in both settings.
Disjoint Label Space Transfer Learning with Common Factorised Space
Dec 06, 2018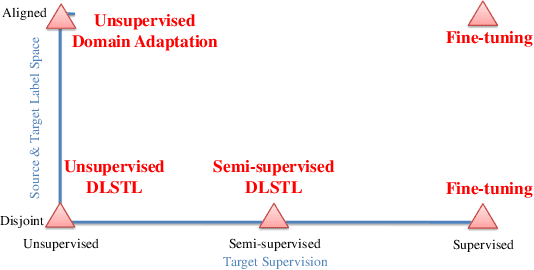
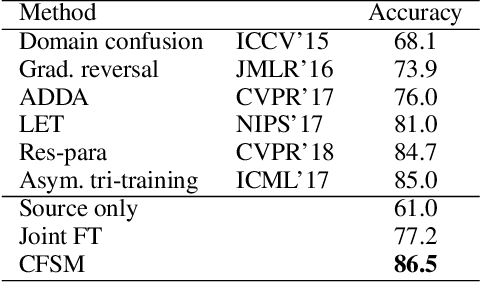
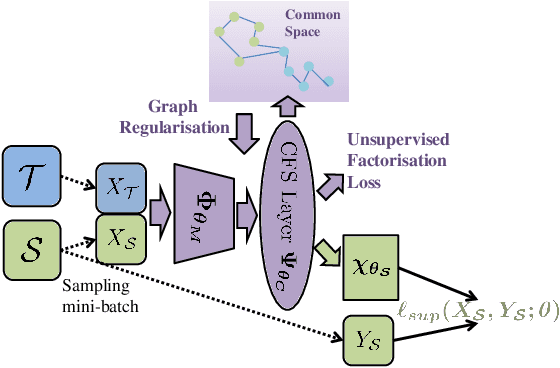
In this paper, a unified approach is presented to transfer learning that addresses several source and target domain label-space and annotation assumptions with a single model. It is particularly effective in handling a challenging case, where source and target label-spaces are disjoint, and outperforms alternatives in both unsupervised and semi-supervised settings. The key ingredient is a common representation termed Common Factorised Space. It is shared between source and target domains, and trained with an unsupervised factorisation loss and a graph-based loss. With a wide range of experiments, we demonstrate the flexibility, relevance and efficacy of our method, both in the challenging cases with disjoint label spaces, and in the more conventional cases such as unsupervised domain adaptation, where the source and target domains share the same label-sets.
Deep Comparison: Relation Columns for Few-Shot Learning
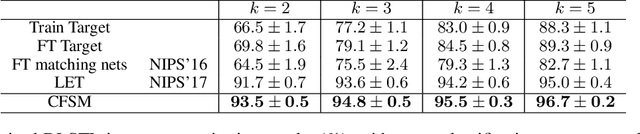
Nov 20, 2018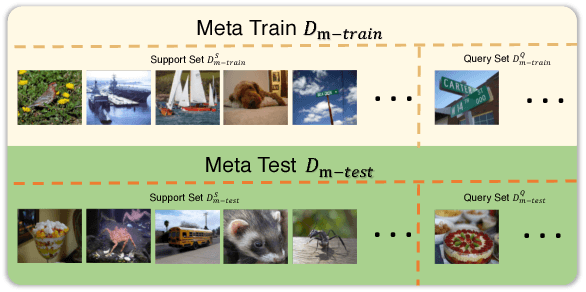
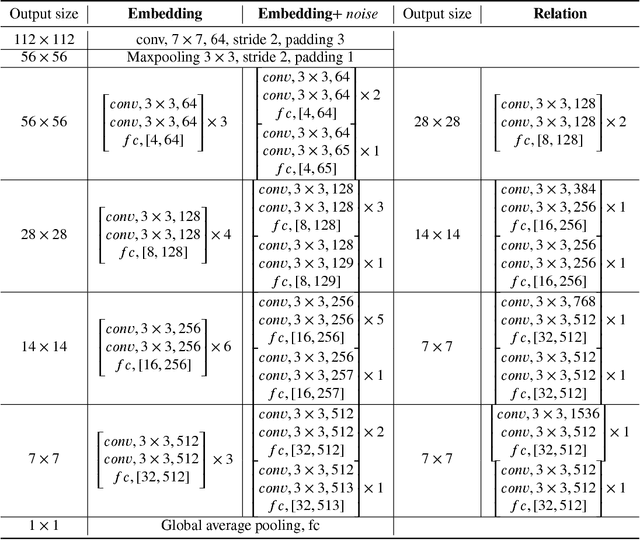
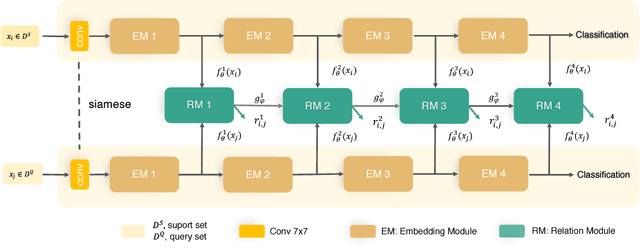
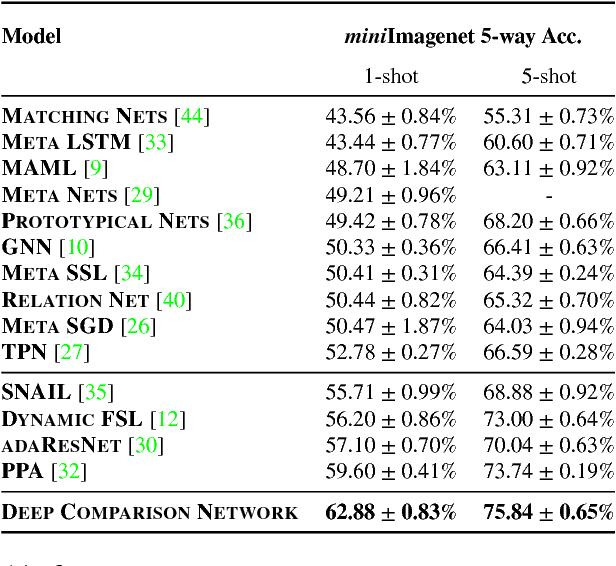
Few-shot deep learning is a topical challenge area for scaling visual recognition to open-ended growth in the space of categories to recognise. A promising line work towards realising this vision is deep networks that learn to match queries with stored training images. However, methods in this paradigm usually train a deep embedding followed by a single linear classifier. Our insight is that effective general-purpose matching requires discrimination with regards to features at multiple abstraction levels. We therefore propose a new framework termed Deep Comparison Network(DCN) that decomposes embedding learning into a sequence of modules, and pairs each with a relation module. The relation modules compute a non-linear metric to score the match using the corresponding embedding module's representation. To ensure that all embedding module's features are used, the relation modules are deeply supervised. Finally generalisation is further improved by a learned noise regulariser. The resulting network achieves state of the art performance on both miniImageNet and tieredImageNet, while retaining the appealing simplicity and efficiency of deep metric learning approaches.