 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical probes expose and alleviate chemical-environment collapse in molecular representations
May 11, 2026Nuclear magnetic resonance (NMR) spectroscopy provides an experimental readout of local chemical environments, but its use in molecular representation learning has been constrained by heterogeneous data and incomplete atom-level assignments. Here we construct complementary high-fidelity experimental and computational 13C NMR resources, which reveal a recurrent form of representational collapse: atoms that are equivalent in molecular topology can remain experimentally distinct in their real chemical environments, whereas explicit 3D descriptions are further limited by static conformations in dynamic regimes. To alleviate this bottleneck, we develop CLAIM (Contrastive Learning for Atom-to-molecule Inference of Molecular NMR), a framework that aligns efficient topological molecular inputs with atom-resolved NMR observables. Through hierarchical chemical priors and cross-level contrastive learning, CLAIM restores lost chemical resolution and markedly improves atom-level molecule-spectrum retrieval. CLAIM remains robust in flexible and tautomeric systems for 13C NMR prediction, improves stereoisomer discrimination without explicit 3D modelling, and transfers to broader molecular property tasks including ADMET prediction and fluorescence estimation. These results establish physically grounded spectral alignment as an effective strategy for alleviating chemical-environment collapse and for guiding experimentally grounded molecular representation learning.
Two-stage Audio-Visual Target Speaker Extraction System for Real-Time Processing On Edge Device
May 28, 2025Audio-Visual Target Speaker Extraction (AVTSE) aims to isolate a target speaker's voice in a multi-speaker environment with visual cues as auxiliary. Most of the existing AVTSE methods encode visual and audio features simultaneously, resulting in extremely high computational complexity and making it impractical for real-time processing on edge devices. To tackle this issue, we proposed a two-stage ultra-compact AVTSE system. Specifically, in the first stage, a compact network is employed for voice activity detection (VAD) using visual information. In the second stage, the VAD results are combined with audio inputs to isolate the target speaker's voice. Experiments show that the proposed system effectively suppresses background noise and interfering voices while spending little computational resources.
Learning from Noisy Labels via Dynamic Loss Thresholding
Apr 01, 2021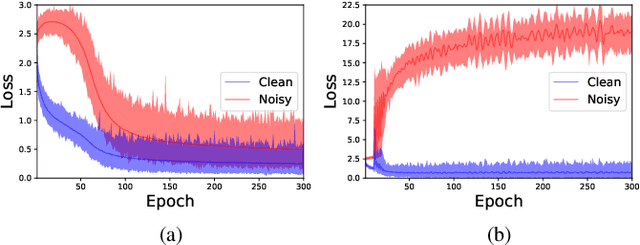
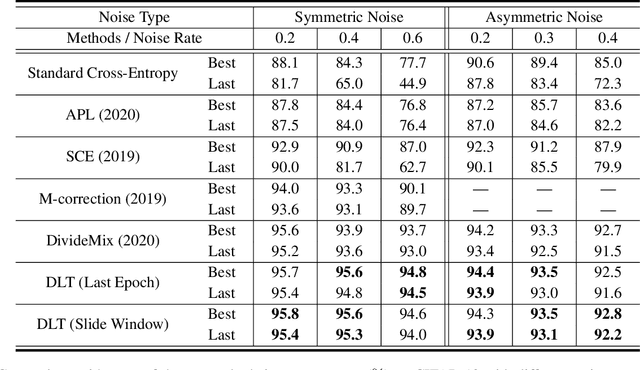
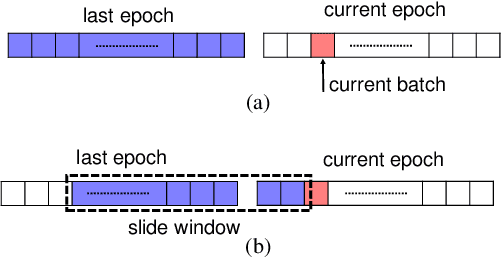
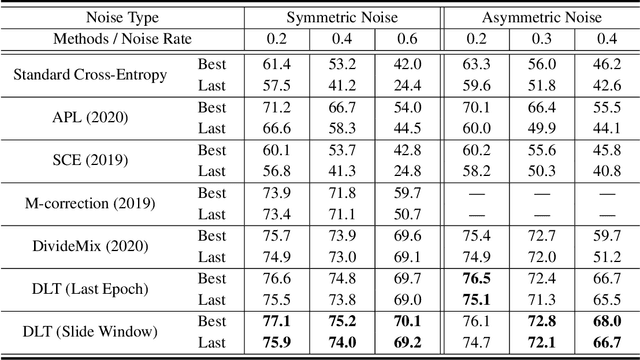
Numerous researches have proved that deep neural networks (DNNs) can fit everything in the end even given data with noisy labels, and result in poor generalization performance. However, recent studies suggest that DNNs tend to gradually memorize the data, moving from correct data to mislabeled data. Inspired by this finding, we propose a novel method named Dynamic Loss Thresholding (DLT). During the training process, DLT records the loss value of each sample and calculates dynamic loss thresholds. Specifically, DLT compares the loss value of each sample with the current loss threshold. Samples with smaller losses can be considered as clean samples with higher probability and vice versa. Then, DLT discards the potentially corrupted labels and further leverages supervised learning techniques. Experiments on CIFAR-10/100 and Clothing1M demonstrate substantial improvements over recent state-of-the-art methods. In addition, we investigate two real-world problems for the first time. Firstly, we propose a novel approach to estimate the noise rates of datasets based on the loss difference between the early and late training stages of DNNs. Secondly, we explore the effect of hard samples (which are difficult to be distinguished) on the process of learning from noisy labels.