 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Feb 11, 2020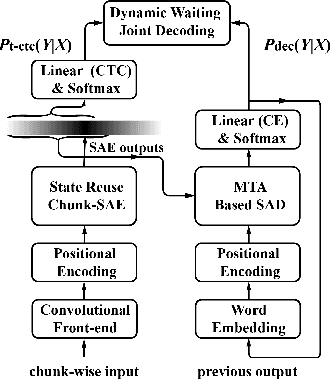

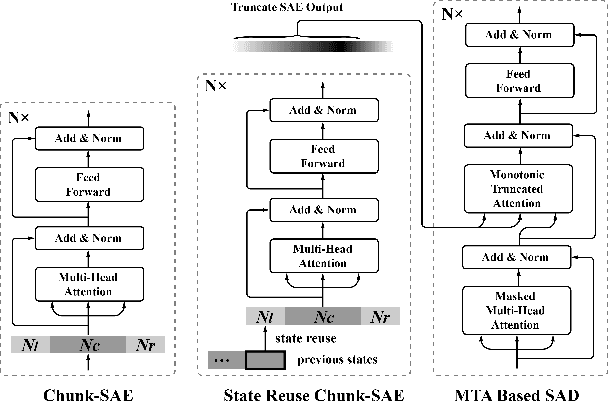
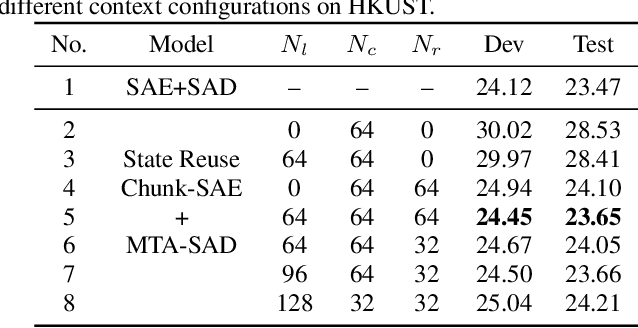
Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as 0.19% absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.
Integrating the Data Augmentation Scheme with Various Classifiers for Acoustic Scene Modeling
Jul 15, 2019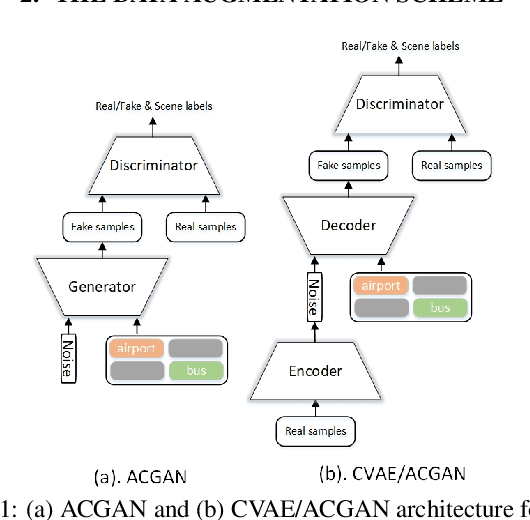
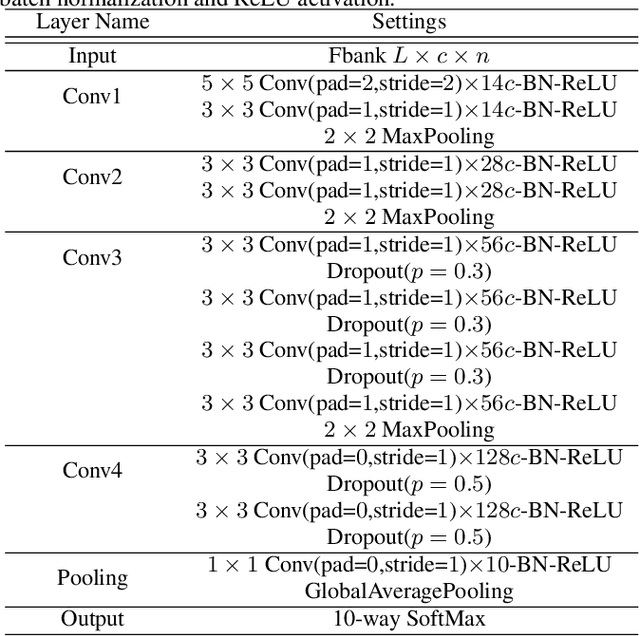
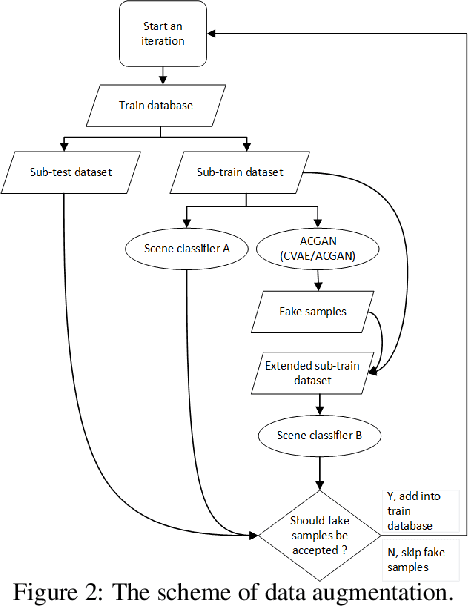
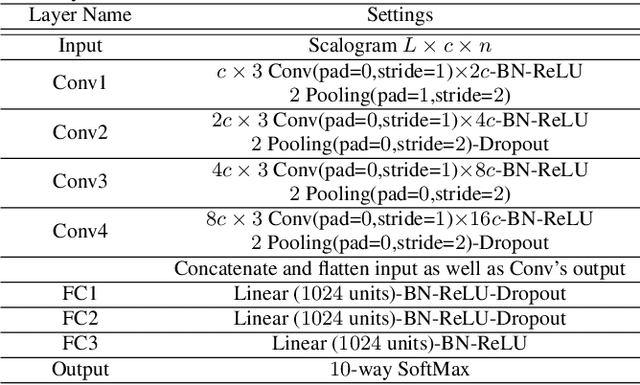
This technical report describes the IOA team's submission for TASK1A of DCASE2019 challenge. Our acoustic scene classification (ASC) system adopts a data augmentation scheme employing generative adversary networks. Two major classifiers, 1D deep convolutional neural network integrated with scalogram features and 2D fully convolutional neural network integrated with Mel filter bank features, are deployed in the scheme. Other approaches, such as adversary city adaptation, temporal module based on discrete cosine transform and hybrid architectures, have been developed for further fusion. The results of our experiments indicates that the final fusion systems A-D could achieve an accuracy higher than 85% on the officially provided fold 1 evaluation dataset.
Rank-1 Constrained Multichannel Wiener Filter for Speech Recognition in Noisy Environments
Nov 15, 2017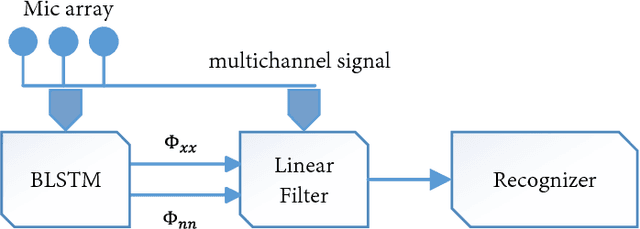

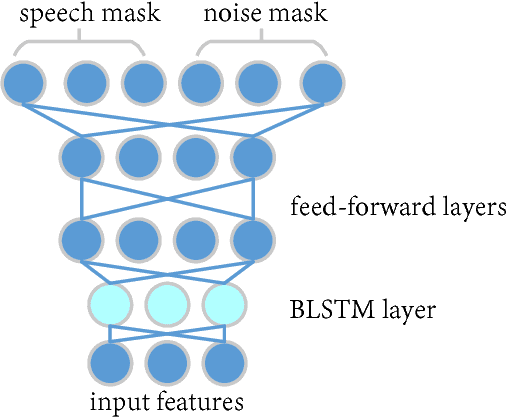
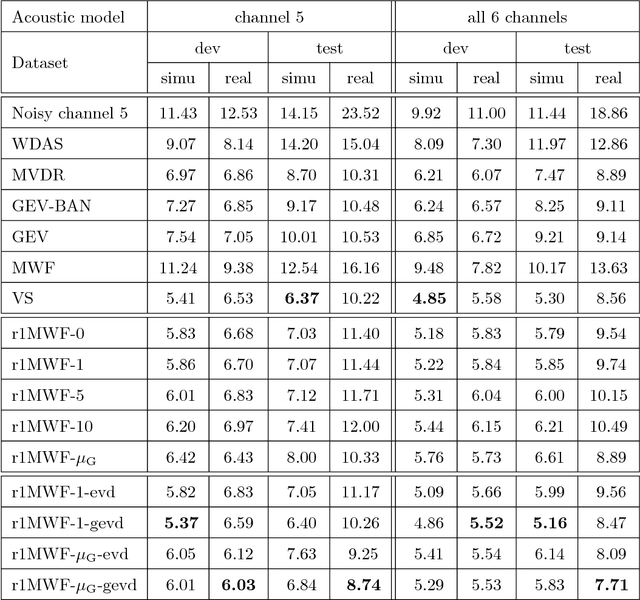
Multichannel linear filters, such as the Multichannel Wiener Filter (MWF) and the Generalized Eigenvalue (GEV) beamformer are popular signal processing techniques which can improve speech recognition performance. In this paper, we present an experimental study on these linear filters in a specific speech recognition task, namely the CHiME-4 challenge, which features real recordings in multiple noisy environments. Specifically, the rank-1 MWF is employed for noise reduction and a new constant residual noise power constraint is derived which enhances the recognition performance. To fulfill the underlying rank-1 assumption, the speech covariance matrix is reconstructed based on eigenvectors or generalized eigenvectors. Then the rank-1 constrained MWF is evaluated with alternative multichannel linear filters under the same framework, which involves a Bidirectional Long Short-Term Memory (BLSTM) network for mask estimation. The proposed filter outperforms alternative ones, leading to a 40% relative Word Error Rate (WER) reduction compared with the baseline Weighted Delay and Sum (WDAS) beamformer on the real test set, and a 15% relative WER reduction compared with the GEV-BAN method. The results also suggest that the speech recognition accuracy correlates more with the Mel-frequency cepstral coefficients (MFCC) feature variance than with the noise reduction or the speech distortion level.
Optimizing human-interpretable dialog management policy using Genetic Algorithm
May 13, 2016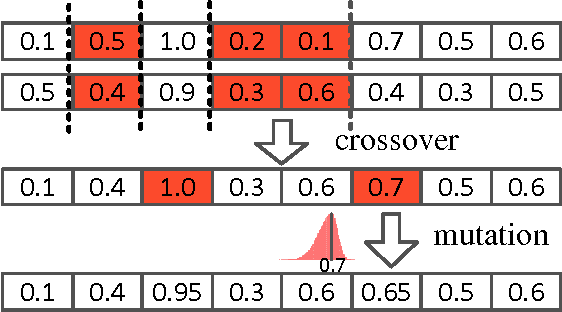
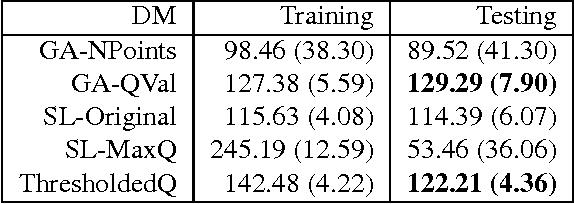
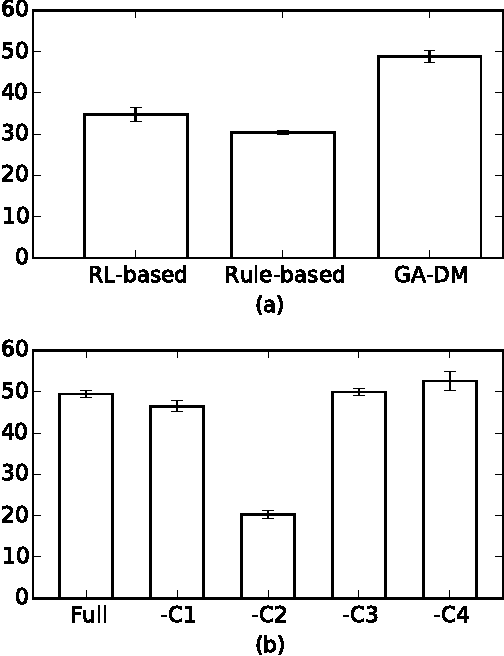
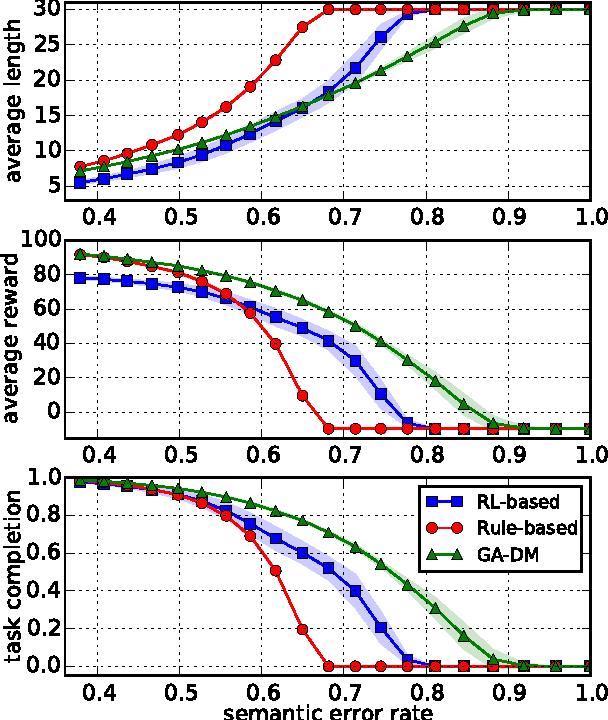
Automatic optimization of spoken dialog management policies that are robust to environmental noise has long been the goal for both academia and industry. Approaches based on reinforcement learning have been proved to be effective. However, the numerical representation of dialog policy is human-incomprehensible and difficult for dialog system designers to verify or modify, which limits its practical application. In this paper we propose a novel framework for optimizing dialog policies specified in domain language using genetic algorithm. The human-interpretable representation of policy makes the method suitable for practical employment. We present learning algorithms using user simulation and real human-machine dialogs respectively.Empirical experimental results are given to show the effectiveness of the proposed approach.
Noise Robust IOA/CAS Speech Separation and Recognition System For The Third 'CHIME' Challenge
Sep 21, 2015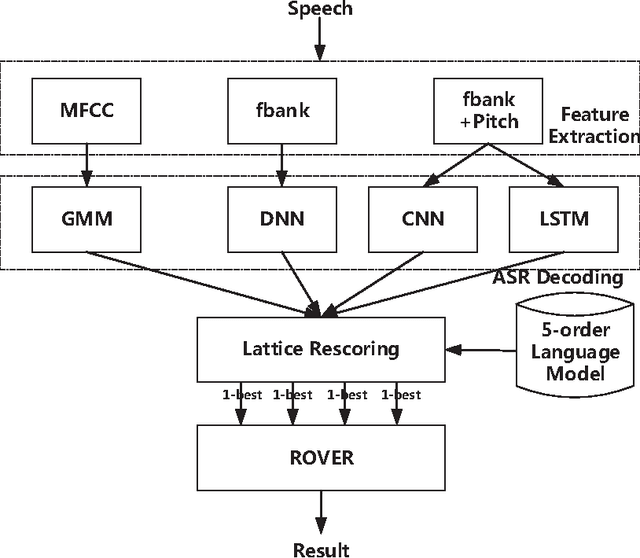
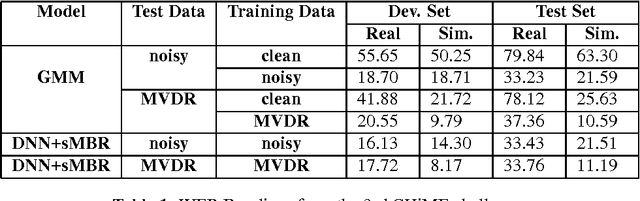

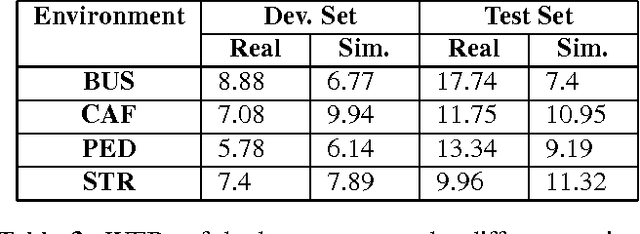
This paper presents the contribution to the third 'CHiME' speech separation and recognition challenge including both front-end signal processing and back-end speech recognition. In the front-end, Multi-channel Wiener filter (MWF) is designed to achieve background noise reduction. Different from traditional MWF, optimized parameter for the tradeoff between noise reduction and target signal distortion is built according to the desired noise reduction level. In the back-end, several techniques are taken advantage to improve the noisy Automatic Speech Recognition (ASR) performance including Deep Neural Network (DNN), Convolutional Neural Network (CNN) and Long short-term memory (LSTM) using medium vocabulary, Lattice rescoring with a big vocabulary language model finite state transducer, and ROVER scheme. Experimental results show the proposed system combining front-end and back-end is effective to improve the ASR performance.