 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyFL: A Low-code Federated Learning Platform For Dummies
May 17, 2021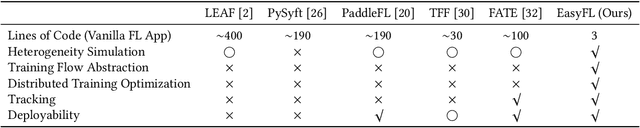

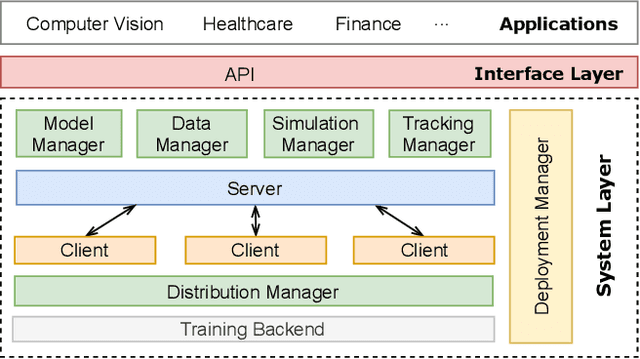
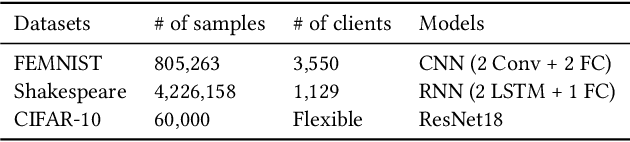
Academia and industry have developed several platforms to support the popular privacy-preserving distributed learning method -- Federated Learning (FL). However, these platforms are complex to use and require a deep understanding of FL, which imposes high barriers to entry for beginners, limits the productivity of data scientists, and compromises deployment efficiency. In this paper, we propose the first low-code FL platform, EasyFL, to enable users with various levels of expertise to experiment and prototype FL applications with little coding. We achieve this goal while ensuring great flexibility for customization by unifying simple API design, modular design, and granular training flow abstraction. With only a few lines of code, EasyFL empowers them with many out-of-the-box functionalities to accelerate experimentation and deployment. These practical functionalities are heterogeneity simulation, distributed training optimization, comprehensive tracking, and seamless deployment. They are proposed based on challenges identified in the proposed FL life cycle. Our implementations show that EasyFL requires only three lines of code to build a vanilla FL application, at least 10x lesser than other platforms. Besides, our evaluations demonstrate that EasyFL expedites training by 1.5x. It also improves the efficiency of experiments and deployment. We believe that EasyFL will increase the productivity of data scientists and democratize FL to wider audiences.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021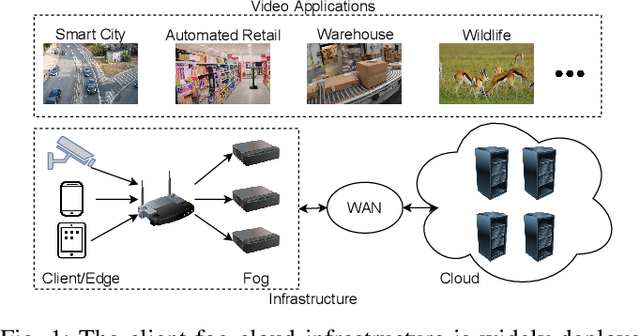
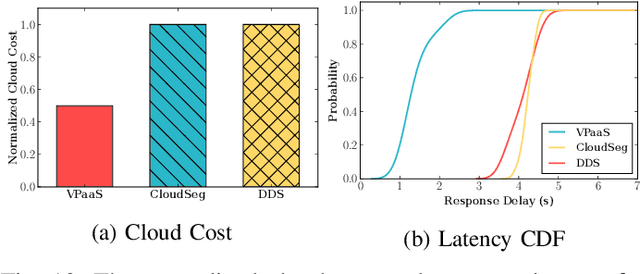
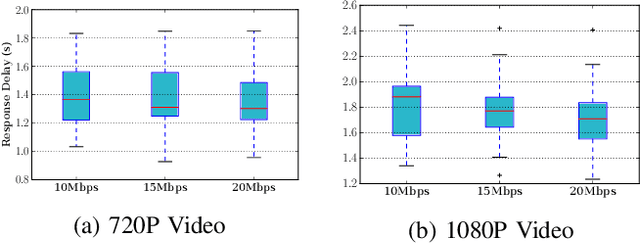
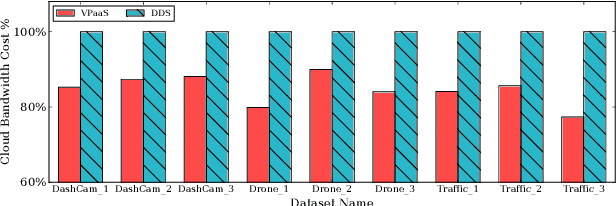
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
On the Practicality of Differential Privacy in Federated Learning by Tuning Iteration Times
Jan 11, 2021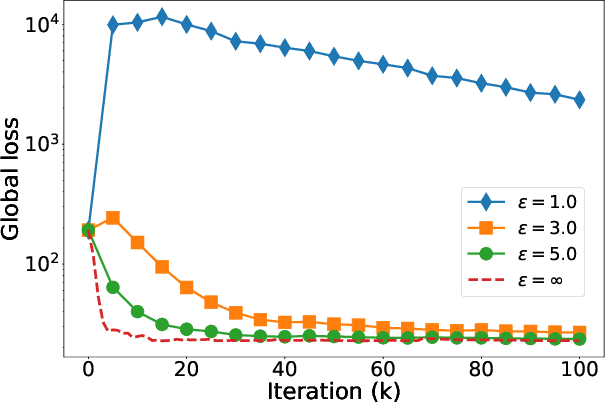
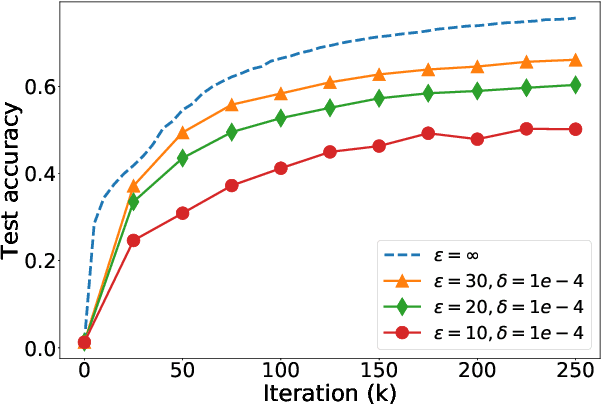
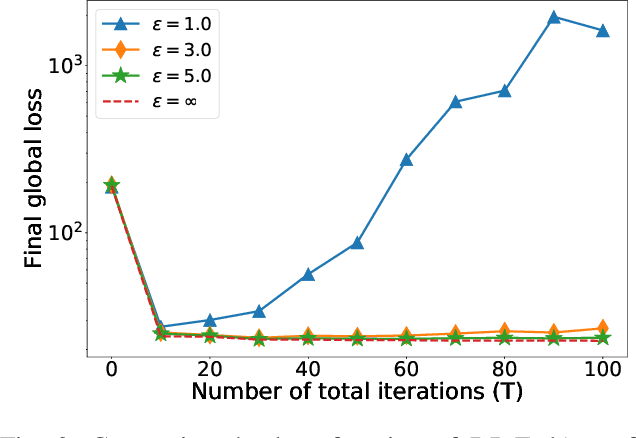
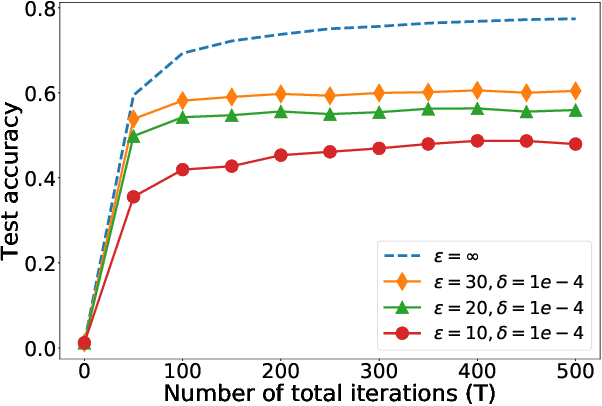
In spite that Federated Learning (FL) is well known for its privacy protection when training machine learning models among distributed clients collaboratively, recent studies have pointed out that the naive FL is susceptible to gradient leakage attacks. In the meanwhile, Differential Privacy (DP) emerges as a promising countermeasure to defend against gradient leakage attacks. However, the adoption of DP by clients in FL may significantly jeopardize the model accuracy. It is still an open problem to understand the practicality of DP from a theoretic perspective. In this paper, we make the first attempt to understand the practicality of DP in FL through tuning the number of conducted iterations. Based on the FedAvg algorithm, we formally derive the convergence rate with DP noises in FL. Then, we theoretically derive: 1) the conditions for the DP based FedAvg to converge as the number of global iterations (GI) approaches infinity; 2) the method to set the number of local iterations (LI) to minimize the negative influence of DP noises. By further substituting the Laplace and Gaussian mechanisms into the derived convergence rate respectively, we show that: 3) The DP based FedAvg with the Laplace mechanism cannot converge, but the divergence rate can be effectively prohibited by setting the number of LIs with our method; 4) The learning error of the DP based FedAvg with the Gaussian mechanism can converge to a constant number finally if we use a fixed number of LIs per GI. To verify our theoretical findings, we conduct extensive experiments using two real-world datasets. The results not only validate our analysis results, but also provide useful guidelines on how to optimize model accuracy when incorporating DP into FL
Learning Relation Prototype from Unlabeled Texts for Long-tail Relation Extraction
Nov 27, 2020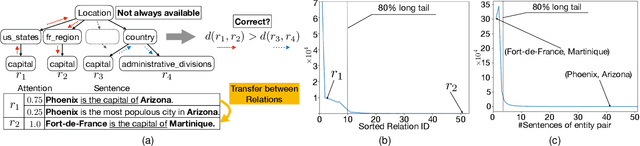
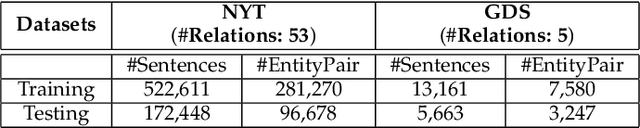
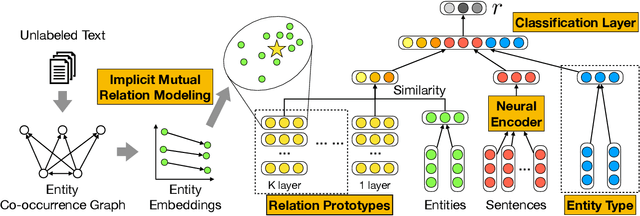
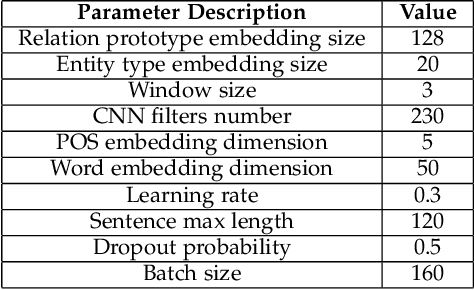
Relation Extraction (RE) is a vital step to complete Knowledge Graph (KG) by extracting entity relations from texts.However, it usually suffers from the long-tail issue. The training data mainly concentrates on a few types of relations, leading to the lackof sufficient annotations for the remaining types of relations. In this paper, we propose a general approach to learn relation prototypesfrom unlabeled texts, to facilitate the long-tail relation extraction by transferring knowledge from the relation types with sufficient trainingdata. We learn relation prototypes as an implicit factor between entities, which reflects the meanings of relations as well as theirproximities for transfer learning. Specifically, we construct a co-occurrence graph from texts, and capture both first-order andsecond-order entity proximities for embedding learning. Based on this, we further optimize the distance from entity pairs tocorresponding prototypes, which can be easily adapted to almost arbitrary RE frameworks. Thus, the learning of infrequent or evenunseen relation types will benefit from semantically proximate relations through pairs of entities and large-scale textual information.We have conducted extensive experiments on two publicly available datasets: New York Times and Google Distant Supervision.Compared with eight state-of-the-art baselines, our proposed model achieves significant improvements (4.1% F1 on average). Furtherresults on long-tail relations demonstrate the effectiveness of the learned relation prototypes. We further conduct an ablation study toinvestigate the impacts of varying components, and apply it to four basic relation extraction models to verify the generalization ability.Finally, we analyze several example cases to give intuitive impressions as qualitative analysis. Our codes will be released later.
Privacy-preserving Collaborative Learning with Automatic Transformation Search
Nov 25, 2020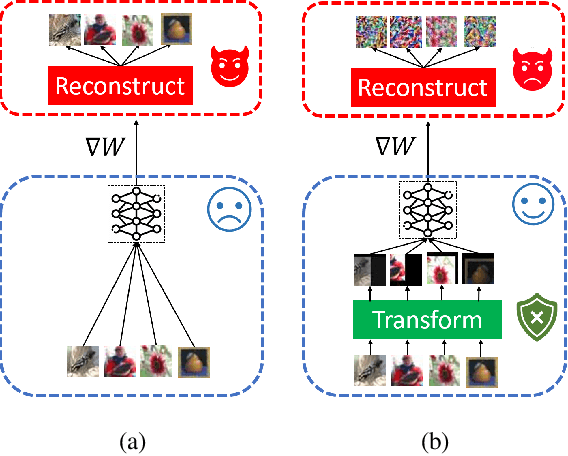

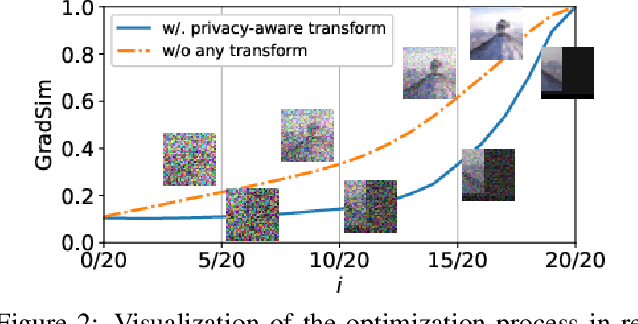
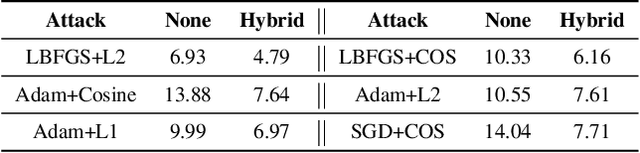
Collaborative learning has gained great popularity due to its benefit of data privacy protection: participants can jointly train a Deep Learning model without sharing their training sets. However, recent works discovered that an adversary can fully recover the sensitive training samples from the shared gradients. Such reconstruction attacks pose severe threats to collaborative learning. Hence, effective mitigation solutions are urgently desired. In this paper, we propose to leverage data augmentation to defeat reconstruction attacks: by preprocessing sensitive images with carefully-selected transformation policies, it becomes infeasible for the adversary to extract any useful information from the corresponding gradients. We design a novel search method to automatically discover qualified policies. We adopt two new metrics to quantify the impacts of transformations on data privacy and model usability, which can significantly accelerate the search speed. Comprehensive evaluations demonstrate that the policies discovered by our method can defeat existing reconstruction attacks in collaborative learning, with high efficiency and negligible impact on the model performance.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking System
Nov 12, 2020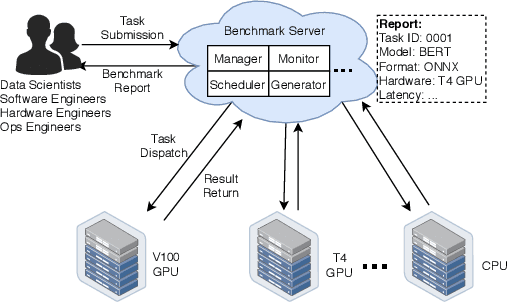

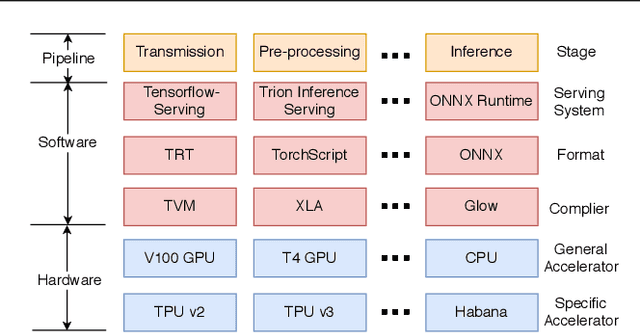
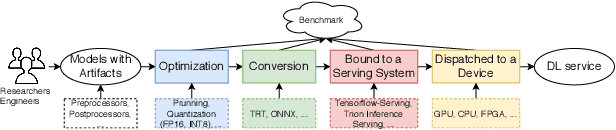
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.
Performance Optimization for Federated Person Re-identification via Benchmark Analysis
Aug 26, 2020
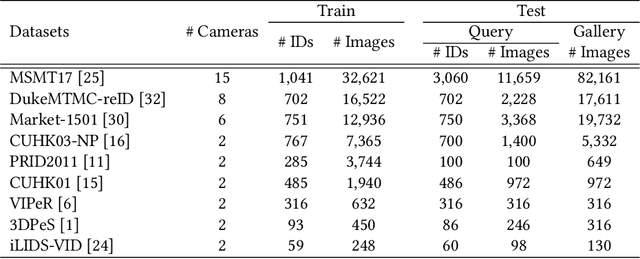
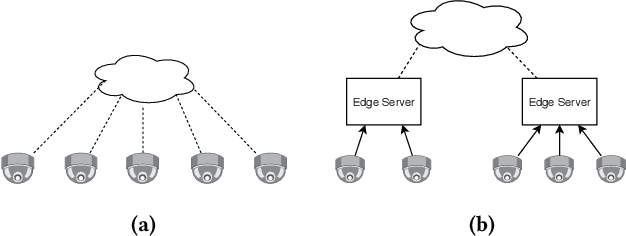
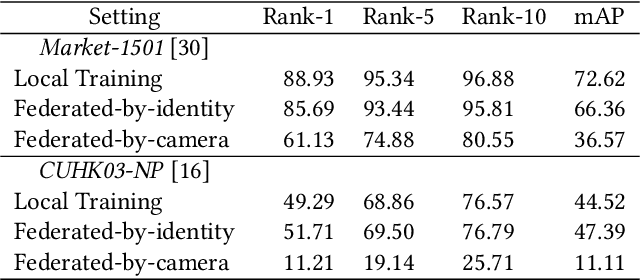
Federated learning is a privacy-preserving machine learning technique that learns a shared model across decentralized clients. It can alleviate privacy concerns of personal re-identification, an important computer vision task. In this work, we implement federated learning to person re-identification (FedReID) and optimize its performance affected by statistical heterogeneity in the real-world scenario. We first construct a new benchmark to investigate the performance of FedReID. This benchmark consists of (1) nine datasets with different volumes sourced from different domains to simulate the heterogeneous situation in reality, (2) two federated scenarios, and (3) an enhanced federated algorithm for FedReID. The benchmark analysis shows that the client-edge-cloud architecture, represented by the federated-by-dataset scenario, has better performance than client-server architecture in FedReID. It also reveals the bottlenecks of FedReID under the real-world scenario, including poor performance of large datasets caused by unbalanced weights in model aggregation and challenges in convergence. Then we propose two optimization methods: (1) To address the unbalanced weight problem, we propose a new method to dynamically change the weights according to the scale of model changes in clients in each training round; (2) To facilitate convergence, we adopt knowledge distillation to refine the server model with knowledge generated from client models on a public dataset. Experiment results demonstrate that our strategies can achieve much better convergence with superior performance on all datasets. We believe that our work will inspire the community to further explore the implementation of federated learning on more computer vision tasks in real-world scenarios.
Hysia: Serving DNN-Based Video-to-Retail Applications in Cloud
Jun 09, 2020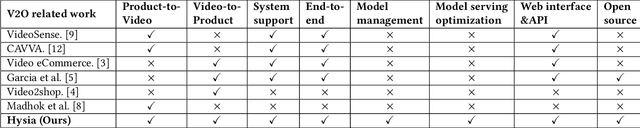
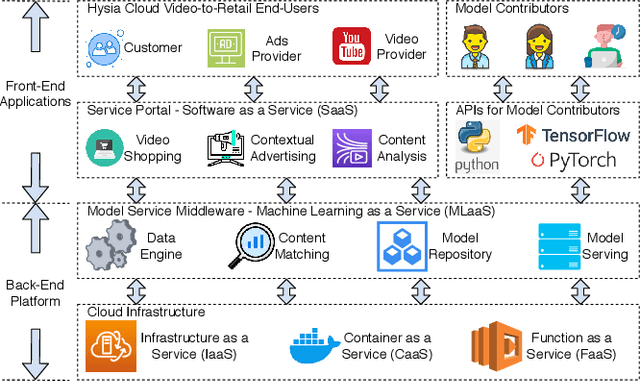
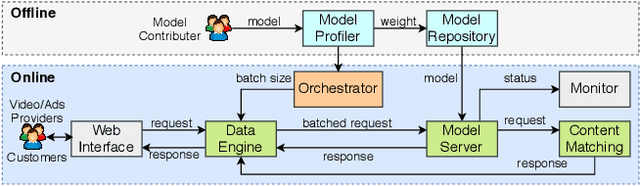
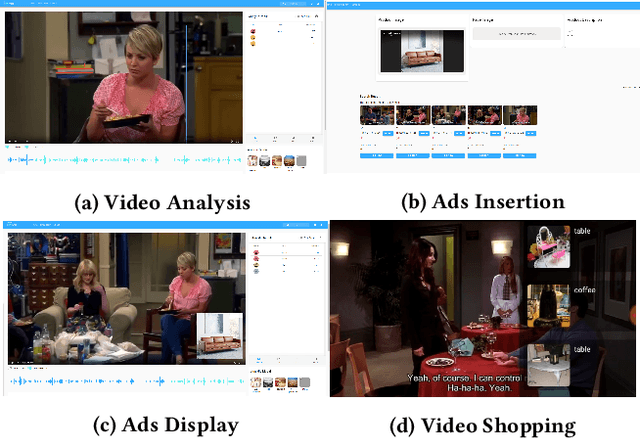
Combining \underline{v}ideo streaming and online \underline{r}etailing (V2R) has been a growing trend recently. In this paper, we provide practitioners and researchers in multimedia with a cloud-based platform named Hysia for easy development and deployment of V2R applications. The system consists of: 1) a back-end infrastructure providing optimized V2R related services including data engine, model repository, model serving and content matching; and 2) an application layer which enables rapid V2R application prototyping. Hysia addresses industry and academic needs in large-scale multimedia by: 1) seamlessly integrating state-of-the-art libraries including NVIDIA video SDK, Facebook faiss, and gRPC; 2) efficiently utilizing GPU computation; and 3) allowing developers to bind new models easily to meet the rapidly changing deep learning (DL) techniques. On top of that, we implement an orchestrator for further optimizing DL model serving performance. Hysia has been released as an open source project on GitHub, and attracted considerable attention. We have published Hysia to DockerHub as an official image for seamless integration and deployment in current cloud environments.
MLModelCI: An Automatic Cloud Platform for Efficient MLaaS
Jun 09, 2020
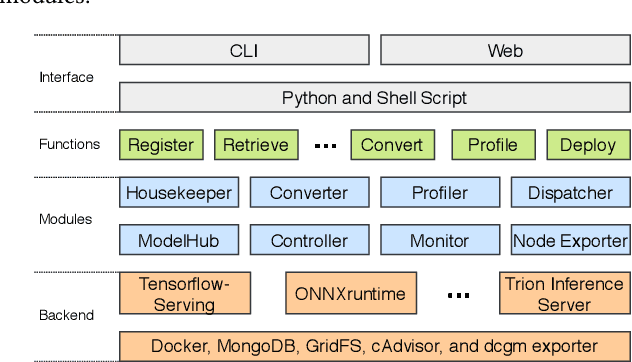
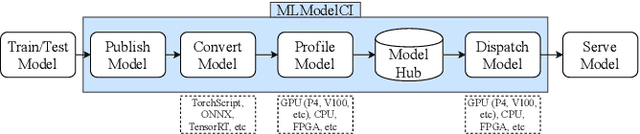
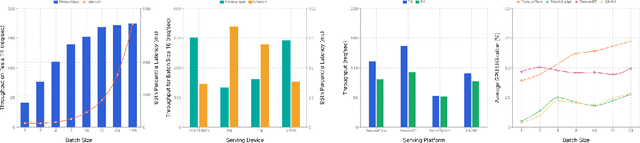
MLModelCI provides multimedia researchers and developers with a one-stop platform for efficient machine learning (ML) services. The system leverages DevOps techniques to optimize, test, and manage models. It also containerizes and deploys these optimized and validated models as cloud services (MLaaS). In its essence, MLModelCI serves as a housekeeper to help users publish models. The models are first automatically converted to optimized formats for production purpose and then profiled under different settings (e.g., batch size and hardware). The profiling information can be used as guidelines for balancing the trade-off between performance and cost of MLaaS. Finally, the system dockerizes the models for ease of deployment to cloud environments. A key feature of MLModelCI is the implementation of a controller, which allows elastic evaluation which only utilizes idle workers while maintaining online service quality. Our system bridges the gap between current ML training and serving systems and thus free developers from manual and tedious work often associated with service deployment. We release the platform as an open-source project on GitHub under Apache 2.0 license, with the aim that it will facilitate and streamline more large-scale ML applications and research projects.
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
Jan 20, 2020
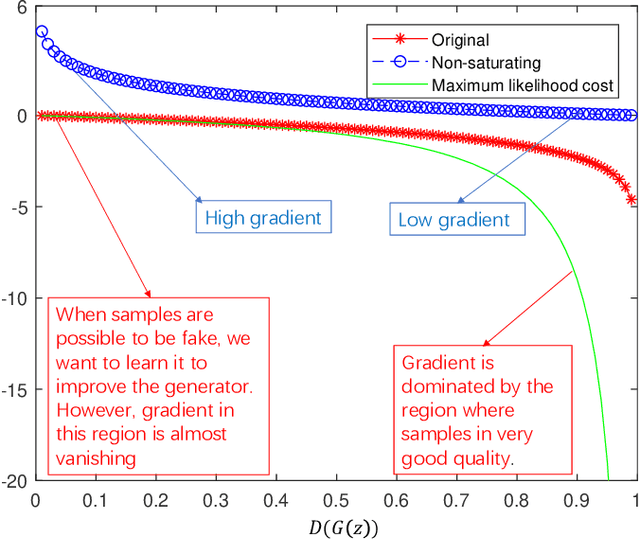

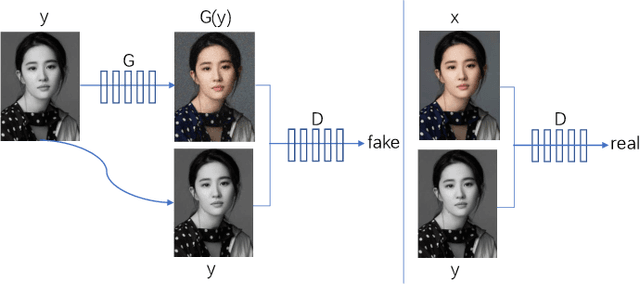
Generative adversarial networks (GANs) are a hot research topic recently. GANs have been widely studied since 2014, and a large number of algorithms have been proposed. However, there is few comprehensive study explaining the connections among different GANs variants, and how they have evolved. In this paper, we attempt to provide a review on various GANs methods from the perspectives of algorithms, theory, and applications. Firstly, the motivations, mathematical representations, and structure of most GANs algorithms are introduced in details. Furthermore, GANs have been combined with other machine learning algorithms for specific applications, such as semi-supervised learning, transfer learning, and reinforcement learning. This paper compares the commonalities and differences of these GANs methods. Secondly, theoretical issues related to GANs are investigated. Thirdly, typical applications of GANs in image processing and computer vision, natural language processing, music, speech and audio, medical field, and data science are illustrated. Finally, the future open research problems for GANs are pointed out.