 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Chinese Word Segmentation with Dictionary Knowledge
Jul 11, 2018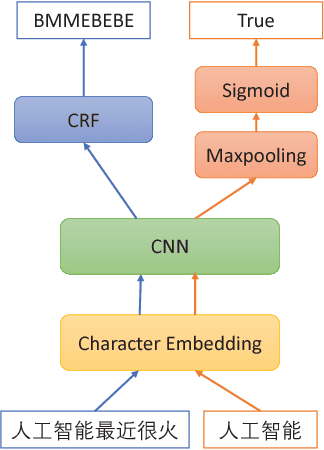
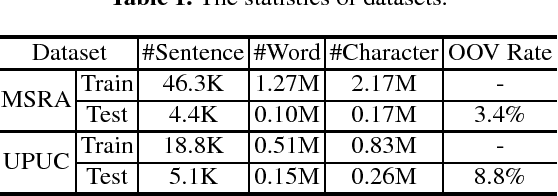
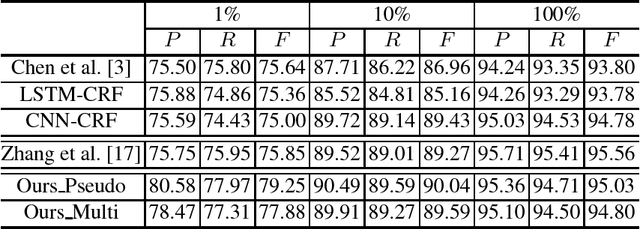
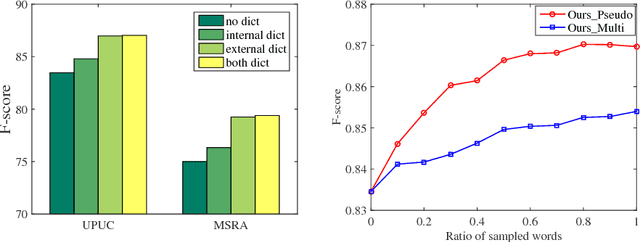
Chinese word segmentation (CWS) is an important task for Chinese NLP. Recently, many neural network based methods have been proposed for CWS. However, these methods require a large number of labeled sentences for model training, and usually cannot utilize the useful information in Chinese dictionary. In this paper, we propose two methods to exploit the dictionary information for CWS. The first one is based on pseudo labeled data generation, and the second one is based on multi-task learning. The experimental results on two benchmark datasets validate that our approach can effectively improve the performance of Chinese word segmentation, especially when training data is insufficient.
Clinical Assistant Diagnosis for Electronic Medical Record Based on Convolutional Neural Network
Apr 23, 2018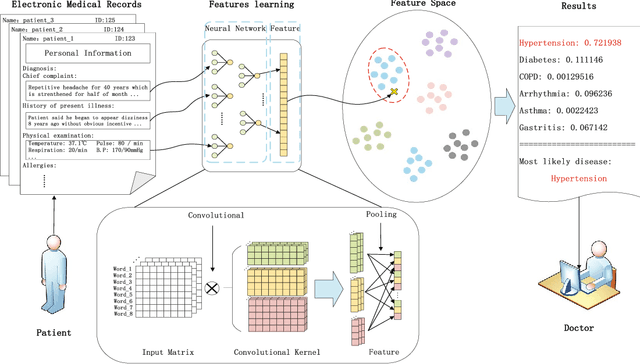

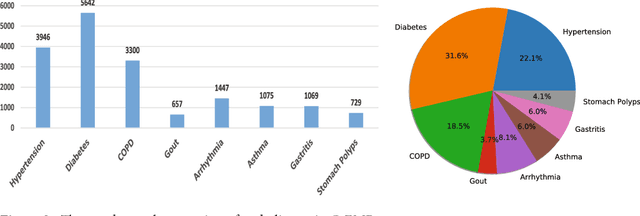
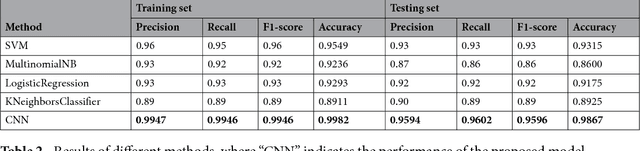
Automatically extracting useful information from electronic medical records along with conducting disease diagnoses is a promising task for both clinical decision support(CDS) and neural language processing(NLP). Most of the existing systems are based on artificially constructed knowledge bases, and then auxiliary diagnosis is done by rule matching. In this study, we present a clinical intelligent decision approach based on Convolutional Neural Networks(CNN), which can automatically extract high-level semantic information of electronic medical records and then perform automatic diagnosis without artificial construction of rules or knowledge bases. We use collected 18,590 copies of the real-world clinical electronic medical records to train and test the proposed model. Experimental results show that the proposed model can achieve 98.67\% accuracy and 96.02\% recall, which strongly supports that using convolutional neural network to automatically learn high-level semantic features of electronic medical records and then conduct assist diagnosis is feasible and effective.
Image Captioning with Object Detection and Localization
Jun 08, 2017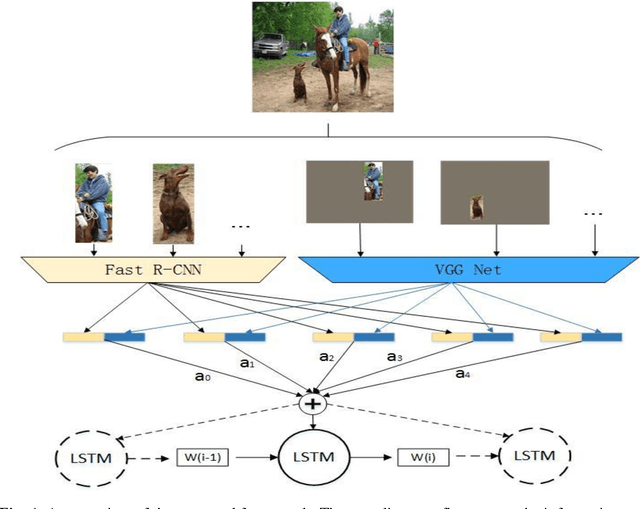
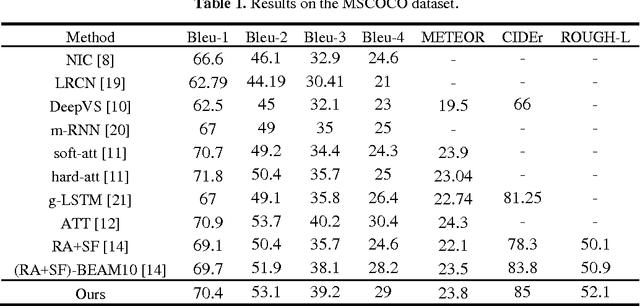


Automatically generating a natural language description of an image is a task close to the heart of image understanding. In this paper, we present a multi-model neural network method closely related to the human visual system that automatically learns to describe the content of images. Our model consists of two sub-models: an object detection and localization model, which extract the information of objects and their spatial relationship in images respectively; Besides, a deep recurrent neural network (RNN) based on long short-term memory (LSTM) units with attention mechanism for sentences generation. Each word of the description will be automatically aligned to different objects of the input image when it is generated. This is similar to the attention mechanism of the human visual system. Experimental results on the COCO dataset showcase the merit of the proposed method, which outperforms previous benchmark models.
Twitter100k: A Real-world Dataset for Weakly Supervised Cross-Media Retrieval
Mar 20, 2017

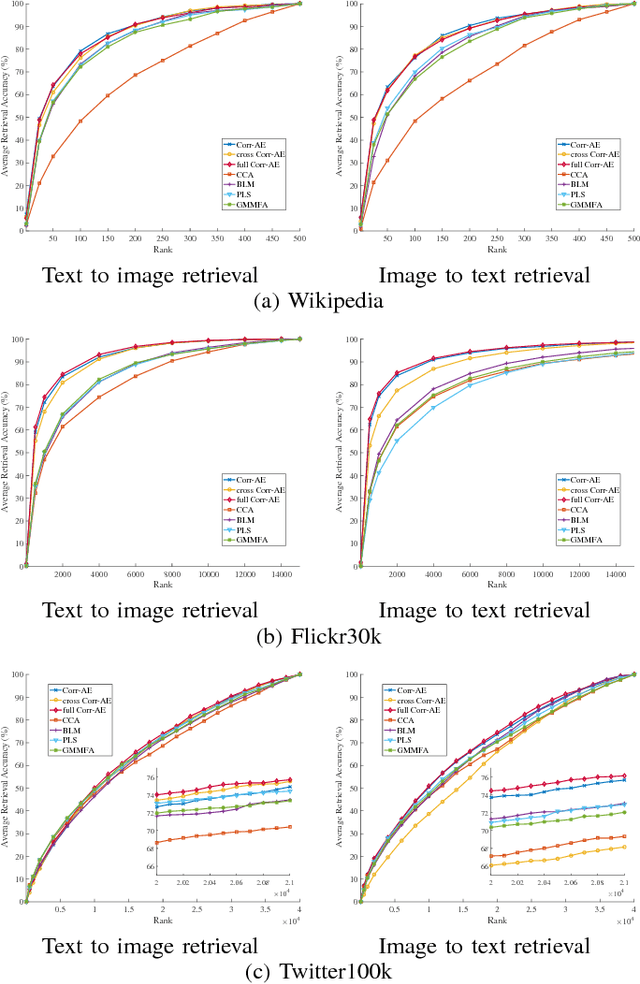
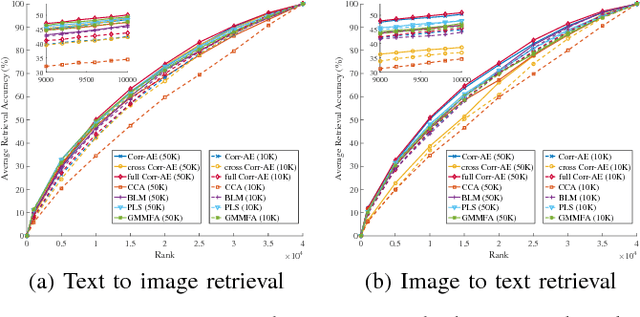
This paper contributes a new large-scale dataset for weakly supervised cross-media retrieval, named Twitter100k. Current datasets, such as Wikipedia, NUS Wide and Flickr30k, have two major limitations. First, these datasets are lacking in content diversity, i.e., only some pre-defined classes are covered. Second, texts in these datasets are written in well-organized language, leading to inconsistency with realistic applications. To overcome these drawbacks, the proposed Twitter100k dataset is characterized by two aspects: 1) it has 100,000 image-text pairs randomly crawled from Twitter and thus has no constraint in the image categories; 2) text in Twitter100k is written in informal language by the users. Since strongly supervised methods leverage the class labels that may be missing in practice, this paper focuses on weakly supervised learning for cross-media retrieval, in which only text-image pairs are exploited during training. We extensively benchmark the performance of four subspace learning methods and three variants of the Correspondence AutoEncoder, along with various text features on Wikipedia, Flickr30k and Twitter100k. Novel insights are provided. As a minor contribution, inspired by the characteristic of Twitter100k, we propose an OCR-based cross-media retrieval method. In experiment, we show that the proposed OCR-based method improves the baseline performance.