 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepyBART: Evidence-based Syntactic Transformations for IE
Jun 04, 2020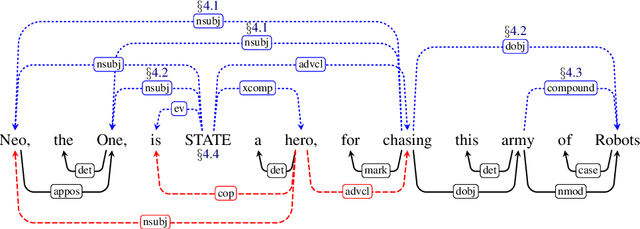
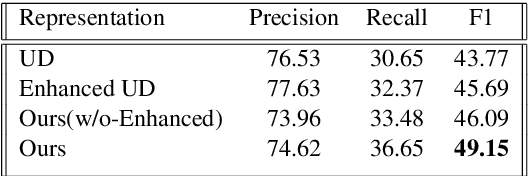

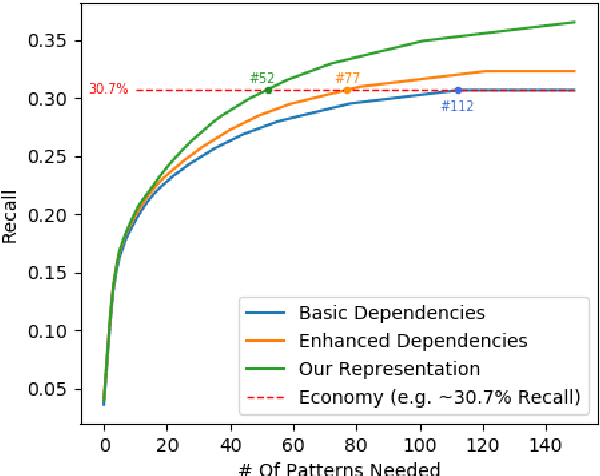
Syntactic dependencies can be predicted with high accuracy, and are useful for both machine-learned and pattern-based information extraction tasks. However, their utility can be improved. These syntactic dependencies are designed to accurately reflect syntactic relations, and they do not make semantic relations explicit. Therefore, these representations lack many explicit connections between content words, that would be useful for downstream applications. Proposals like English Enhanced UD improve the situation by extending universal dependency trees with additional explicit arcs. However, they are not available to Python users, and are also limited in coverage. We introduce a broad-coverage, data-driven and linguistically sound set of transformations, that makes event-structure and many lexical relations explicit. We present pyBART, an easy-to-use open-source Python library for converting English UD trees either to Enhanced UD graphs or to our representation. The library can work as a standalone package or be integrated within a spaCy NLP pipeline. When evaluated in a pattern-based relation extraction scenario, our representation results in higher extraction scores than Enhanced UD, while requiring fewer patterns.
Aligning Faithful Interpretations with their Social Attribution
Jun 01, 2020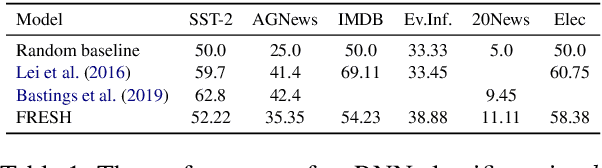
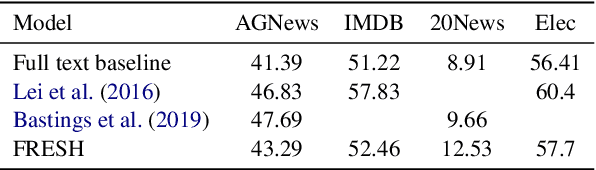


We find that the requirement of model interpretations to be faithful is vague and incomplete. Indeed, recent work refers to interpretations as unfaithful despite adhering to the available definition. Similarly, we identify several critical failures with the notion of textual highlights as faithful interpretations, although they adhere to the faithfulness definition. With textual highlights as a case-study, and borrowing concepts from social science, we identify that the problem is a misalignment between the causal chain of decisions (causal attribution) and social attribution of human behavior to the interpretation. We re-formulate faithfulness as an accurate attribution of causality to the model, and introduce the concept of "aligned faithfulness": faithful causal chains that are aligned with their expected social behavior. The two steps of causal attribution and social attribution *together* complete the process of explaining behavior, making the alignment of faithful interpretations a requirement. With this formalization, we characterize the observed failures of misaligned faithful highlight interpretations, and propose an alternative causal chain to remedy the issues. Finally, we the implement highlight explanations of proposed causal format using contrastive explanations.
When Bert Forgets How To POS: Amnesic Probing of Linguistic Properties and MLM Predictions
Jun 01, 2020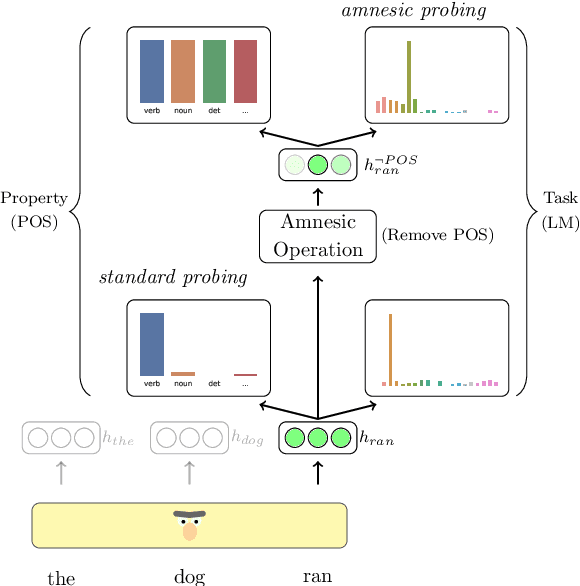
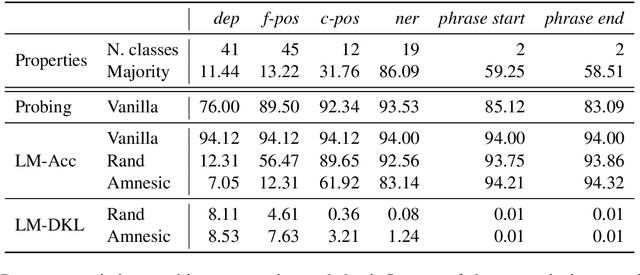
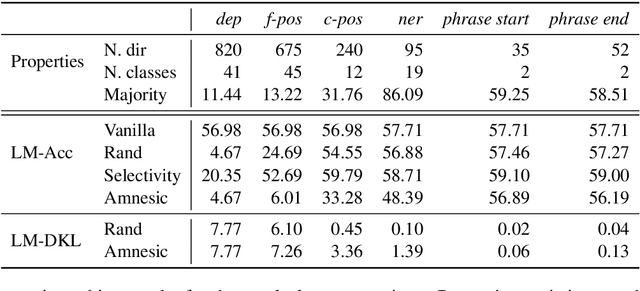
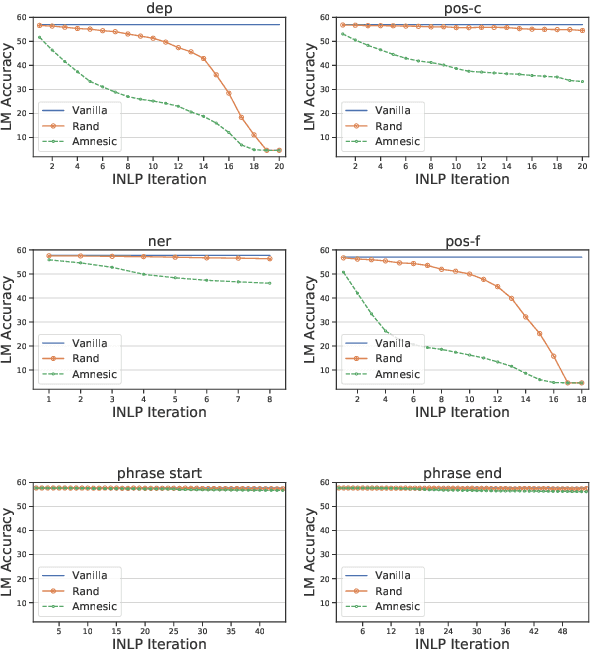
A growing body of work makes use of probing in order to investigate the working of neural models, often considered black boxes. Recently, an ongoing debate emerged surrounding the limitations of the probing paradigm. In this work, we point out the inability to infer behavioral conclusions from probing results, and offer an alternative method which is focused on how the information is being used, rather than on what information is encoded. Our method, Amnesic Probing, follows the intuition that the utility of a property for a given task can be assessed by measuring the influence of a causal intervention which removes it from the representation. Equipped with this new analysis tool, we can now ask questions that were not possible before, e.g. is part-of-speech information important for word prediction? We perform a series of analyses on BERT to answer these types of questions. Our findings demonstrate that conventional probing performance is not correlated to task importance, and we call for increased scrutiny of claims that draw behavioral or causal conclusions from probing results.
Nakdan: Professional Hebrew Diacritizer
May 07, 2020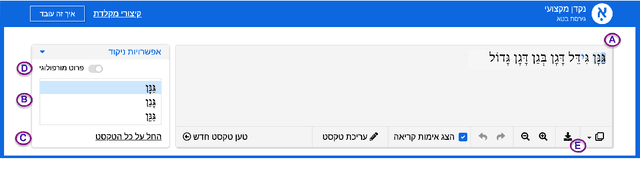
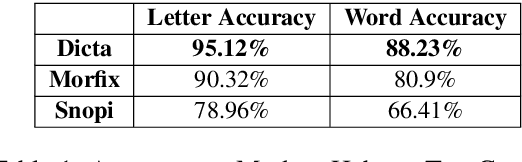
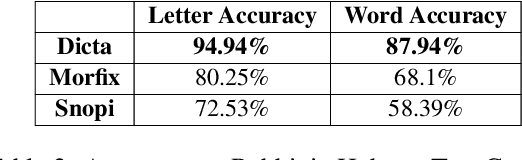

We present a system for automatic diacritization of Hebrew text. The system combines modern neural models with carefully curated declarative linguistic knowledge and comprehensive manually constructed tables and dictionaries. Besides providing state of the art diacritization accuracy, the system also supports an interface for manual editing and correction of the automatic output, and has several features which make it particularly useful for preparation of scientific editions of Hebrew texts. The system supports Modern Hebrew, Rabbinic Hebrew and Poetic Hebrew. The system is freely accessible for all use at http://nakdanpro.dicta.org.il.
A Two-Stage Masked LM Method for Term Set Expansion
May 03, 2020
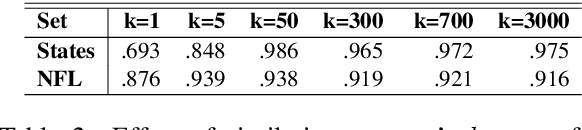
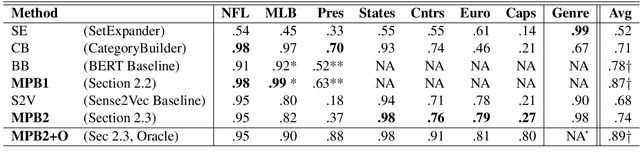

We tackle the task of Term Set Expansion (TSE): given a small seed set of example terms from a semantic class, finding more members of that class. The task is of great practical utility, and also of theoretical utility as it requires generalization from few examples. Previous approaches to the TSE task can be characterized as either distributional or pattern-based. We harness the power of neural masked language models (MLM) and propose a novel TSE algorithm, which combines the pattern-based and distributional approaches. Due to the small size of the seed set, fine-tuning methods are not effective, calling for more creative use of the MLM. The gist of the idea is to use the MLM to first mine for informative patterns with respect to the seed set, and then to obtain more members of the seed class by generalizing these patterns. Our method outperforms state-of-the-art TSE algorithms. Implementation is available at: https://github.com/ guykush/TermSetExpansion-MPB/
Unsupervised Domain Clusters in Pretrained Language Models
May 01, 2020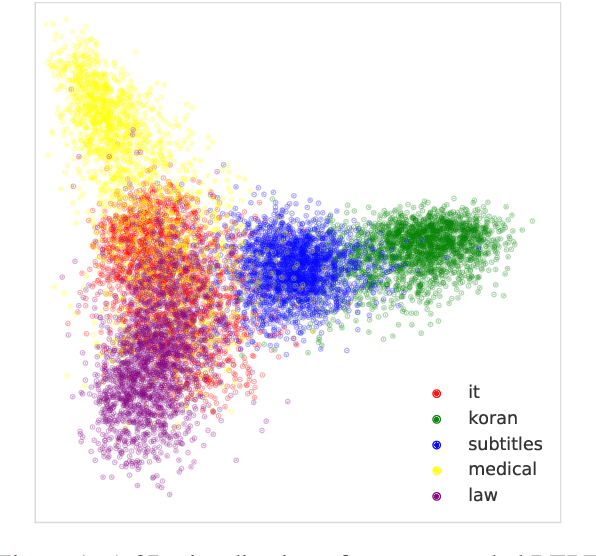
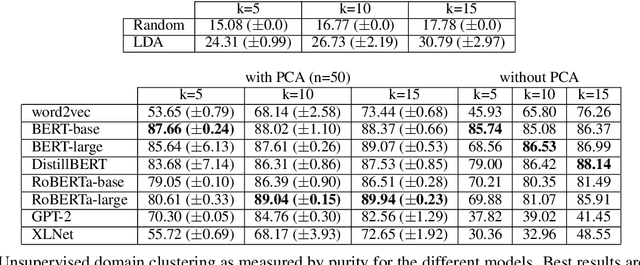
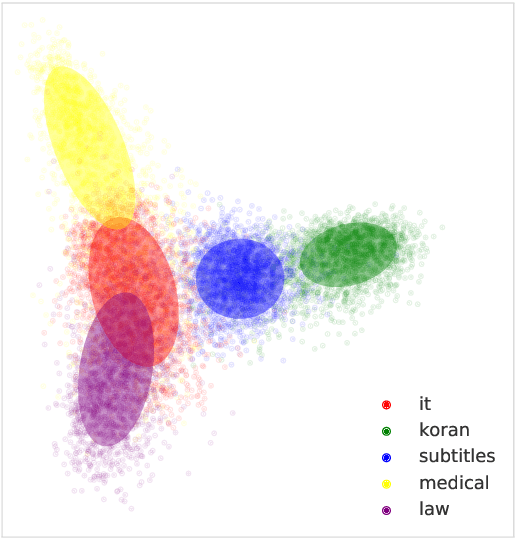
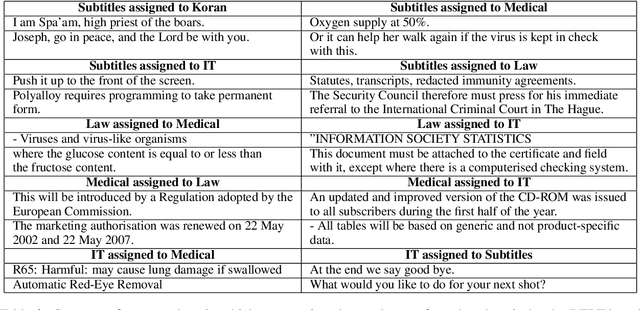
The notion of "in-domain data" in NLP is often over-simplistic and vague, as textual data varies in many nuanced linguistic aspects such as topic, style or level of formality. In addition, domain labels are many times unavailable, making it challenging to build domain-specific systems. We show that massive pre-trained language models implicitly learn sentence representations that cluster by domains without supervision -- suggesting a simple data-driven definition of domains in textual data. We harness this property and propose domain data selection methods based on such models, which require only a small set of in-domain monolingual data. We evaluate our data selection methods for neural machine translation across five diverse domains, where they outperform an established approach as measured by both BLEU and by precision and recall of sentence selection with respect to an oracle.
Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection
Apr 28, 2020
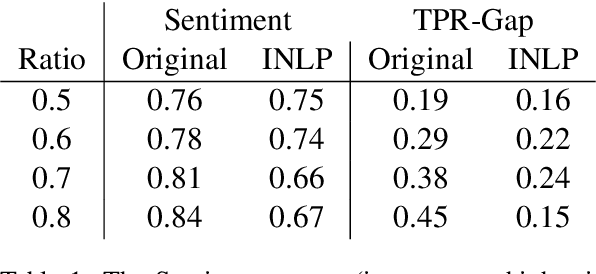
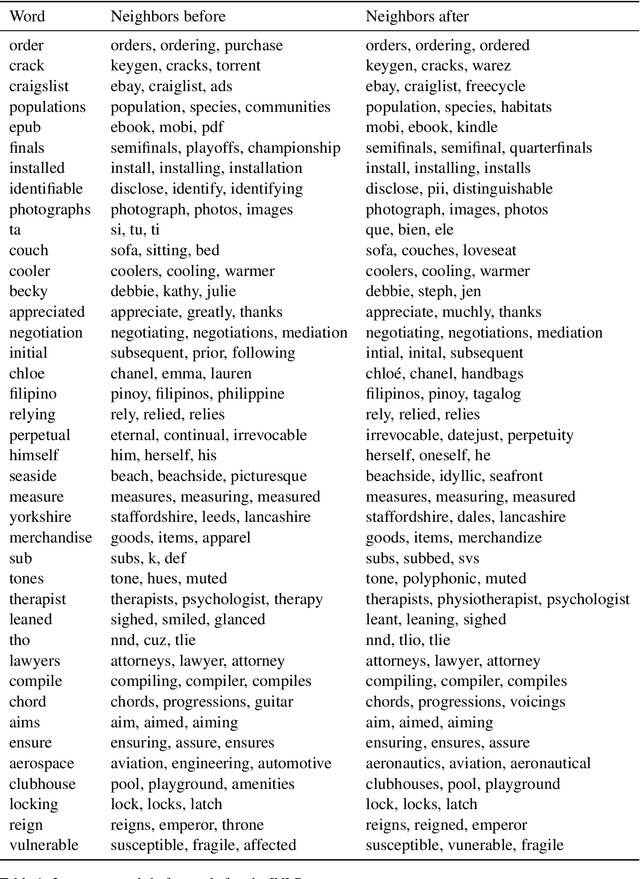
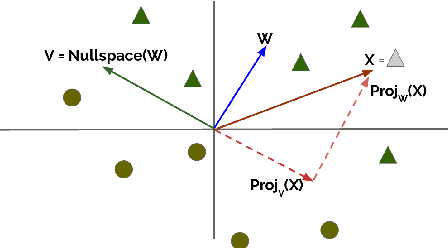
The ability to control for the kinds of information encoded in neural representation has a variety of use cases, especially in light of the challenge of interpreting these models. We present Iterative Null-space Projection (INLP), a novel method for removing information from neural representations. Our method is based on repeated training of linear classifiers that predict a certain property we aim to remove, followed by projection of the representations on their null-space. By doing so, the classifiers become oblivious to that target property, making it hard to linearly separate the data according to it. While applicable for multiple uses, we evaluate our method on bias and fairness use-cases, and show that our method is able to mitigate bias in word embeddings, as well as to increase fairness in a setting of multi-class classification.
Towards Faithfully Interpretable NLP Systems: How should we define and evaluate faithfulness?
Apr 27, 2020With the growing popularity of deep-learning based NLP models, comes a need for interpretable systems. But what is interpretability, and what constitutes a high-quality interpretation? In this opinion piece we reflect on the current state of interpretability evaluation research. We call for more clearly differentiating between different desired criteria an interpretation should satisfy, and focus on the faithfulness criteria. We survey the literature with respect to faithfulness evaluation, and arrange the current approaches around three assumptions, providing an explicit form to how faithfulness is "defined" by the community. We provide concrete guidelines on how evaluation of interpretation methods should and should not be conducted. Finally, we claim that the current binary definition for faithfulness sets a potentially unrealistic bar for being considered faithful. We call for discarding the binary notion of faithfulness in favor of a more graded one, which we believe will be of greater practical utility.
A Formal Hierarchy of RNN Architectures
Apr 24, 2020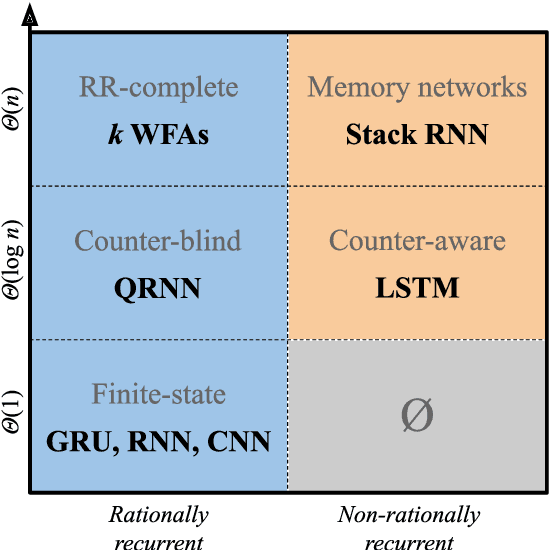
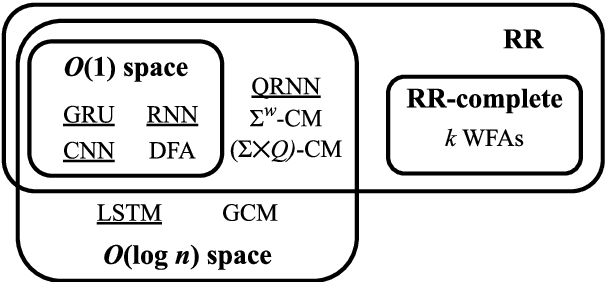
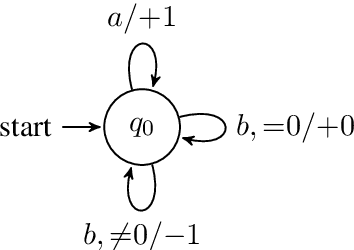
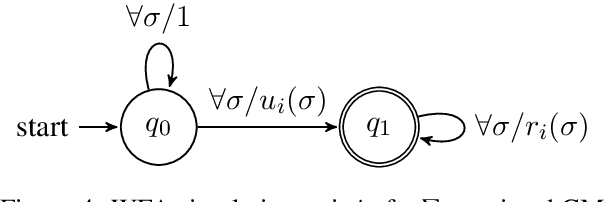
We develop a formal hierarchy of the expressive capacity of RNN architectures. The hierarchy is based on two formal properties: space complexity, which measures the RNN's memory, and rational recurrence, defined as whether the recurrent update can be described by a weighted finite-state machine. We place several RNN variants within this hierarchy. For example, we prove the LSTM is not rational, which formally separates it from the related QRNN (Bradbury et al., 2016). We also show how these models' expressive capacity is expanded by stacking multiple layers or composing them with different pooling functions. Our results build on the theory of "saturated" RNNs (Merrill, 2019). While formally extending these findings to unsaturated RNNs is left to future work, we hypothesize that the practical learnable capacity of unsaturated RNNs obeys a similar hierarchy. Experimental findings from training unsaturated networks on formal languages support this conjecture.
Break It Down: A Question Understanding Benchmark
Jan 31, 2020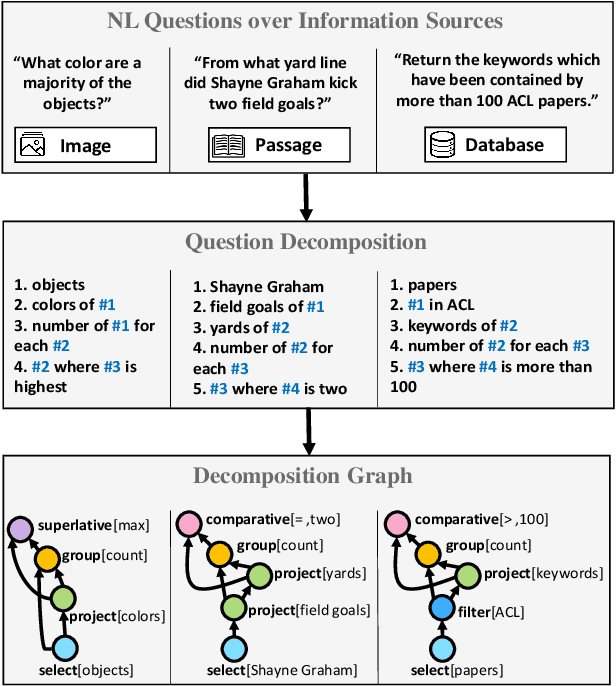
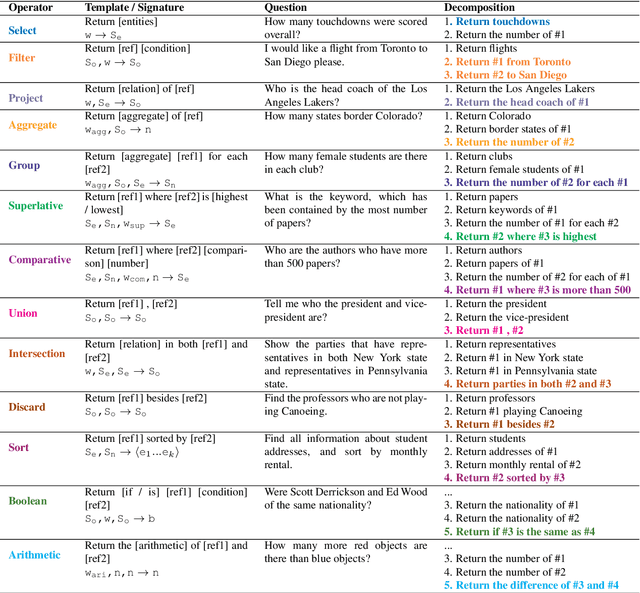
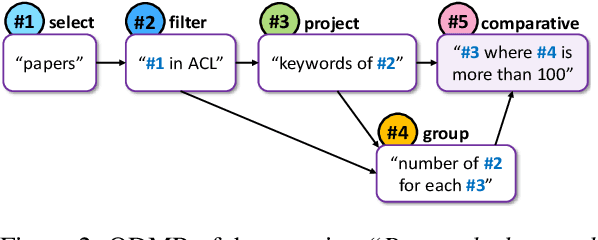

Understanding natural language questions entails the ability to break down a question into the requisite steps for computing its answer. In this work, we introduce a Question Decomposition Meaning Representation (QDMR) for questions. QDMR constitutes the ordered list of steps, expressed through natural language, that are necessary for answering a question. We develop a crowdsourcing pipeline, showing that quality QDMRs can be annotated at scale, and release the Break dataset, containing over 83K pairs of questions and their QDMRs. We demonstrate the utility of QDMR by showing that (a) it can be used to improve open-domain question answering on the HotpotQA dataset, (b) it can be deterministically converted to a pseudo-SQL formal language, which can alleviate annotation in semantic parsing applications. Last, we use Break to train a sequence-to-sequence model with copying that parses questions into QDMR structures, and show that it substantially outperforms several natural baselines.