 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoLMpics -- On what Language Model Pre-training Captures
Dec 31, 2019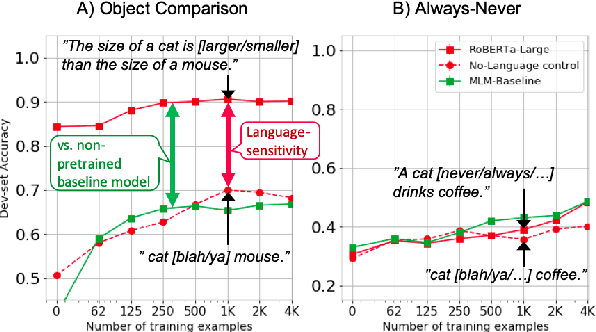

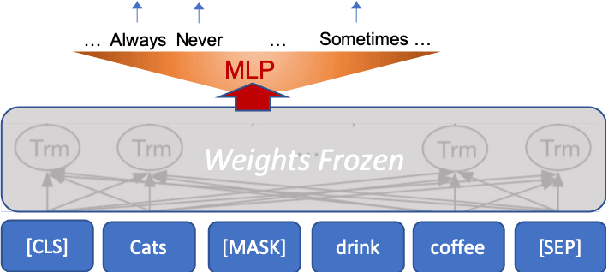
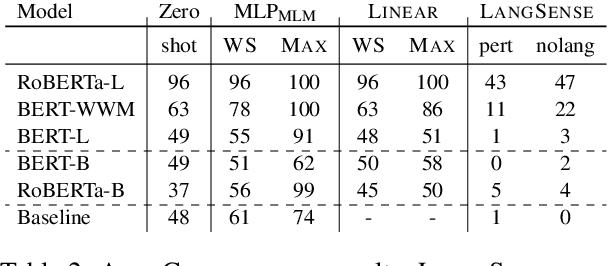
Recent success of pre-trained language models (LMs) has spurred widespread interest in the language capabilities that they possess. However, efforts to understand whether LM representations are useful for symbolic reasoning tasks have been limited and scattered. In this work, we propose eight reasoning tasks, which conceptually require operations such as comparison, conjunction, and composition. A fundamental challenge is to understand whether the performance of a LM on a task should be attributed to the pre-trained representations or to the process of fine-tuning on the task data. To address this, we propose an evaluation protocol that includes both zero-shot evaluation (no fine-tuning), as well as comparing the learning curve of a fine-tuned LM to the learning curve of multiple controls, which paints a rich picture of the LM capabilities. Our main findings are that: (a) different LMs exhibit qualitatively different reasoning abilities, e.g., RoBERTa succeeds in reasoning tasks where BERT fails completely; (b) LMs do not reason in an abstract manner and are context-dependent, e.g., while RoBERTa can compare ages, it can do so only when the ages are in the typical range of human ages; (c) On half of our reasoning tasks all models fail completely. Our findings and infrastructure can help future work on designing new datasets, models and objective functions for pre-training.
How does Grammatical Gender Affect Noun Representations in Gender-Marking Languages?
Oct 30, 2019
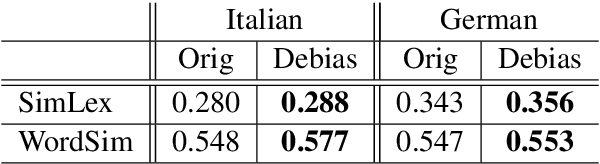
Many natural languages assign grammatical gender also to inanimate nouns in the language. In such languages, words that relate to the gender-marked nouns are inflected to agree with the noun's gender. We show that this affects the word representations of inanimate nouns, resulting in nouns with the same gender being closer to each other than nouns with different gender. While "embedding debiasing" methods fail to remove the effect, we demonstrate that a careful application of methods that neutralize grammatical gender signals from the words' context when training word embeddings is effective in removing it. Fixing the grammatical gender bias yields a positive effect on the quality of the resulting word embeddings, both in monolingual and cross-lingual settings. We note that successfully removing gender signals, while achievable, is not trivial to do and that a language-specific morphological analyzer, together with careful usage of it, are essential for achieving good results.
Learning Deterministic Weighted Automata with Queries and Counterexamples
Oct 30, 2019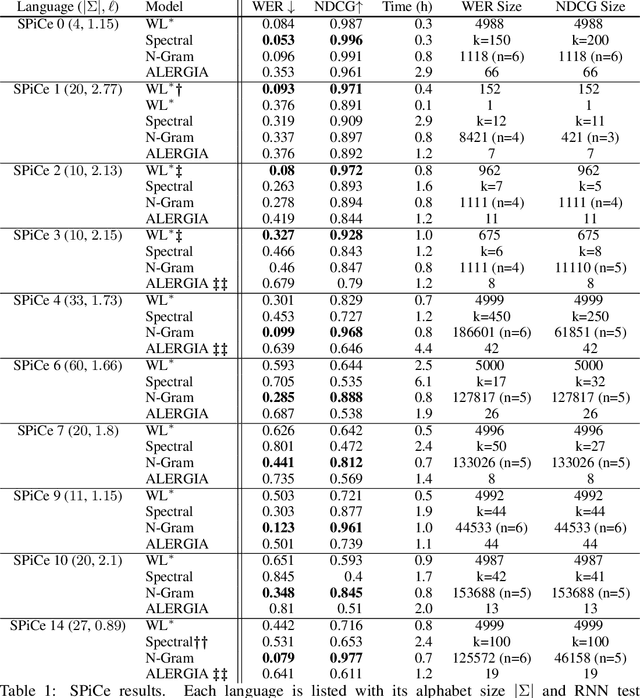
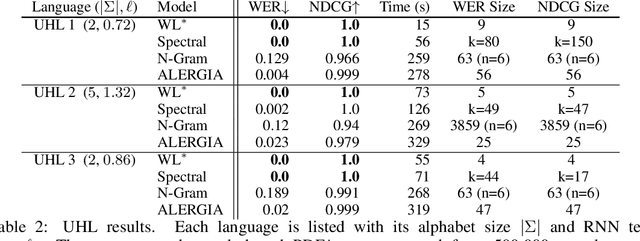
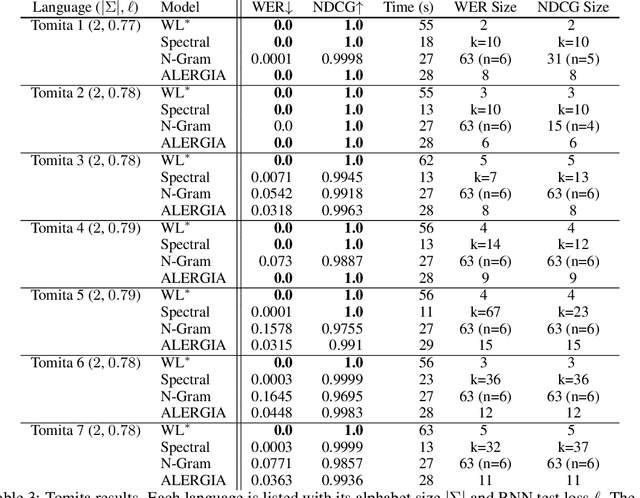
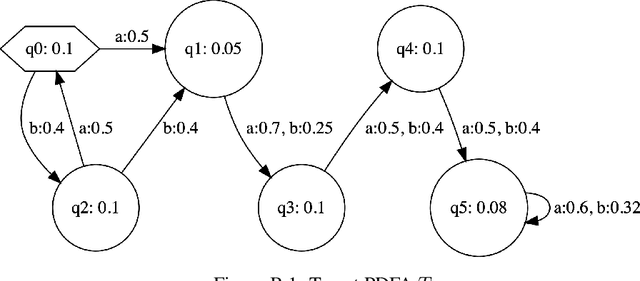
We present an algorithm for extraction of a probabilistic deterministic finite automaton (PDFA) from a given black-box language model, such as a recurrent neural network (RNN). The algorithm is a variant of the exact-learning algorithm L*, adapted to a probabilistic setting with noise. The key insight is the use of conditional probabilities for observations, and the introduction of a local tolerance when comparing them. When applied to RNNs, our algorithm often achieves better word error rate (WER) and normalised distributed cumulative gain (NDCG) than that achieved by spectral extraction of weighted finite automata (WFA) from the same networks. PDFAs are substantially more expressive than n-grams, and are guaranteed to be stochastic and deterministic - unlike spectrally extracted WFAs.
Scalable Evaluation and Improvement of Document Set Expansion via Neural Positive-Unlabeled Learning
Oct 29, 2019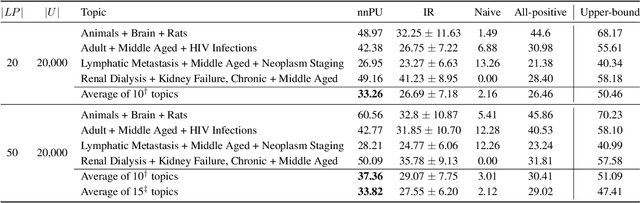
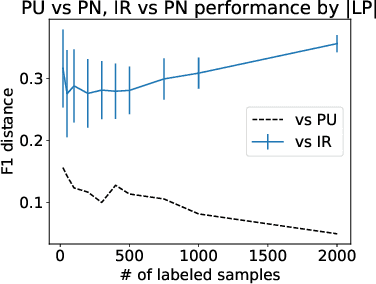
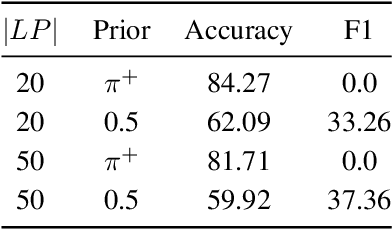
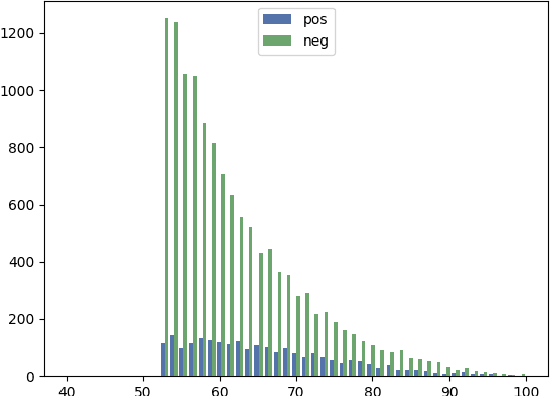
We consider the situation in which a user has collected a small set of documents on a cohesive topic, and they want to retrieve additional documents on this topic from a large collection. Information Retrieval (IR) solutions treat the document set as a query, and look for similar documents in the collection. We propose to extend the IR approach by treating the problem as an instance of positive-unlabeled (PU) learning---i.e., learning binary classifiers from only positive and unlabeled data, where the positive data corresponds to the query documents, and the unlabeled data is the results returned by the IR engine. Utilizing PU learning for text with big neural networks is a largely unexplored field. We discuss various challenges in applying PU learning to the setting, including an unknown class prior, extremely imbalanced data and large-scale accurate evaluation of models, and we propose solutions and empirically validate them. We demonstrate the effectiveness of the method using a series of experiments of retrieving PubMed abstracts adhering to fine-grained topics. We demonstrate improvements over the base IR solution and other baselines. Implementation is available at https://github.com/sayaendo/document-set-expansion-pu.
Improving Quality and Efficiency in Plan-based Neural Data-to-Text Generation
Sep 22, 2019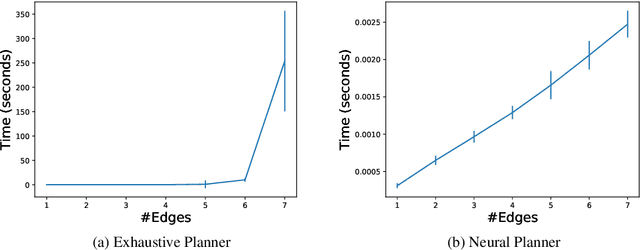
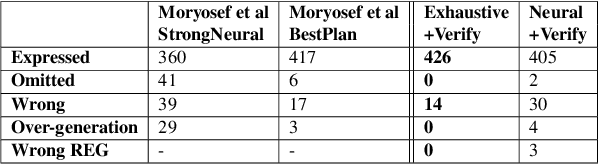

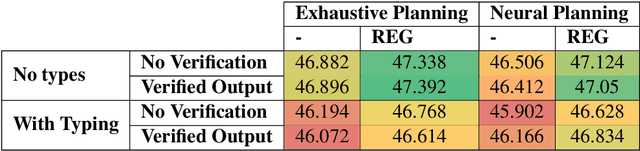
We follow the step-by-step approach to neural data-to-text generation we proposed in Moryossef et al (2019), in which the generation process is divided into a text-planning stage followed by a plan-realization stage. We suggest four extensions to that framework: (1) we introduce a trainable neural planning component that can generate effective plans several orders of magnitude faster than the original planner; (2) we incorporate typing hints that improve the model's ability to deal with unseen relations and entities; (3) we introduce a verification-by-reranking stage that substantially improves the faithfulness of the resulting texts; (4) we incorporate a simple but effective referring expression generation module. These extensions result in a generation process that is faster, more fluent, and more accurate.
Transfer Learning Between Related Tasks Using Expected Label Proportions
Sep 01, 2019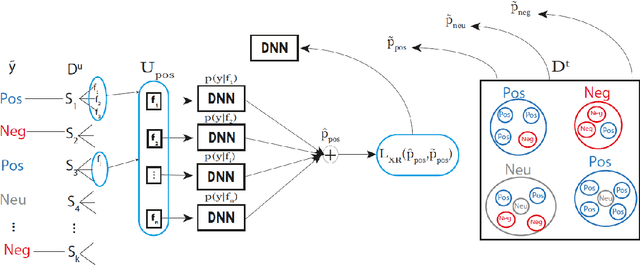
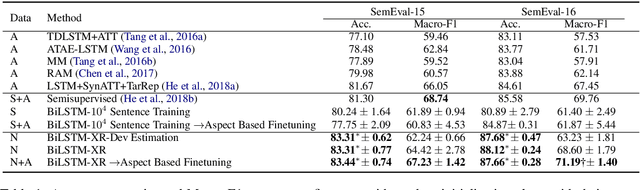
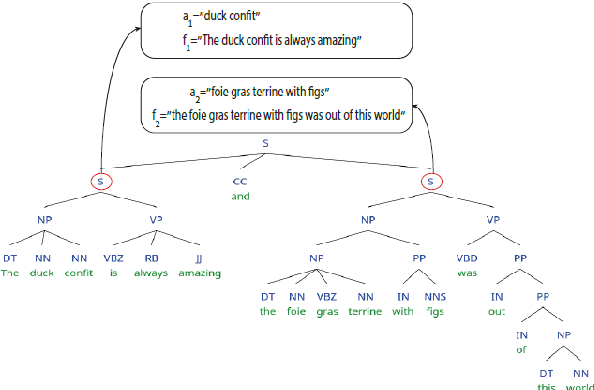
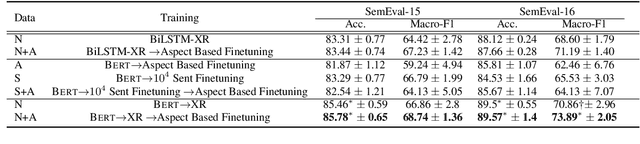
Deep learning systems thrive on abundance of labeled training data but such data is not always available, calling for alternative methods of supervision. One such method is expectation regularization (XR) (Mann and McCallum, 2007), where models are trained based on expected label proportions. We propose a novel application of the XR framework for transfer learning between related tasks, where knowing the labels of task A provides an estimation of the label proportion of task B. We then use a model trained for A to label a large corpus, and use this corpus with an XR loss to train a model for task B. To make the XR framework applicable to large-scale deep-learning setups, we propose a stochastic batched approximation procedure. We demonstrate the approach on the task of Aspect-based Sentiment classification, where we effectively use a sentence-level sentiment predictor to train accurate aspect-based predictor. The method improves upon fully supervised neural system trained on aspect-level data, and is also cumulative with LM-based pretraining, as we demonstrate by improving a BERT-based Aspect-based Sentiment model.
* EMNLP 2019
Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets
Aug 28, 2019
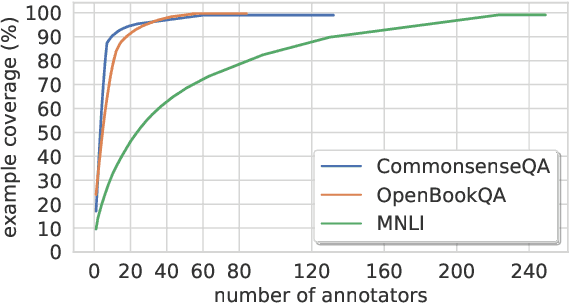
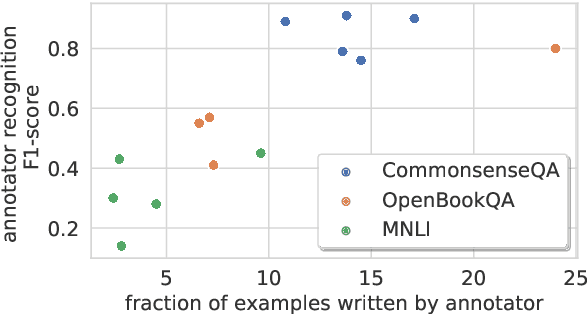

Crowdsourcing has been the prevalent paradigm for creating natural language understanding datasets in recent years. A common crowdsourcing practice is to recruit a small number of high-quality workers, and have them massively generate examples. Having only a few workers generate the majority of examples raises concerns about data diversity, especially when workers freely generate sentences. In this paper, we perform a series of experiments showing these concerns are evident in three recent NLP datasets. We show that model performance improves when training with annotator identifiers as features, and that models are able to recognize the most productive annotators. Moreover, we show that often models do not generalize well to examples from annotators that did not contribute to the training set. Our findings suggest that annotator bias should be monitored during dataset creation, and that test set annotators should be disjoint from training set annotators.
Ab Antiquo: Proto-language Reconstruction with RNNs
Aug 07, 2019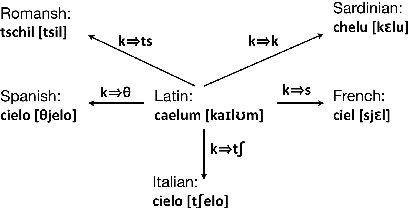

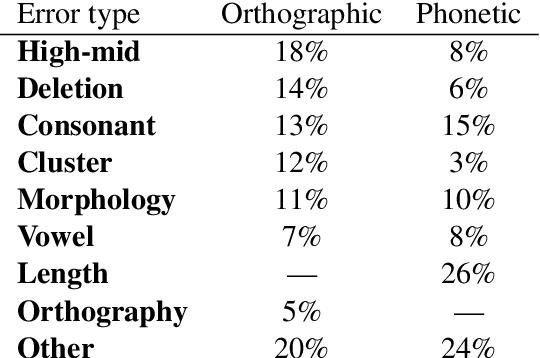
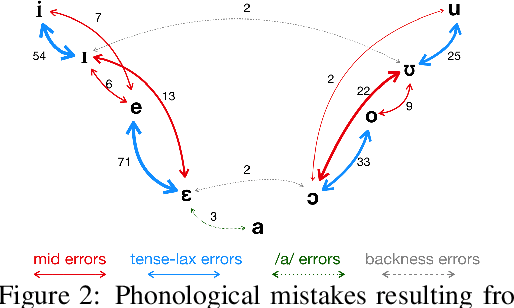
Historical linguists have identified regularities in the process of historic sound change. The comparative method utilizes those regularities to reconstruct proto-words based on observed forms in daughter languages. Can this process be efficiently automated? We address the task of proto-word reconstruction, in which the model is exposed to cognates in contemporary daughter languages, and has to predict the proto word in the ancestor language. We provide a novel dataset for this task, encompassing over 8,000 comparative entries, and show that neural sequence models outperform conventional methods applied to this task so far. Error analysis reveals a variability in the ability of neural model to capture different phonological changes, correlating with the complexity of the changes. Analysis of learned embeddings reveals the models learn phonologically meaningful generalizations, corresponding to well-attested phonological shifts documented by historical linguistics.
Towards better substitution-based word sense induction
May 31, 2019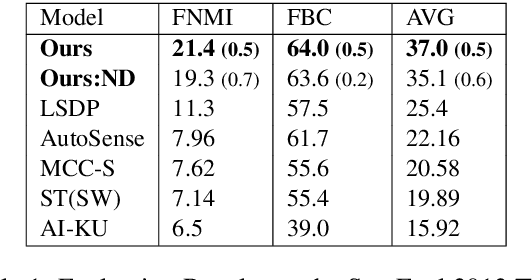
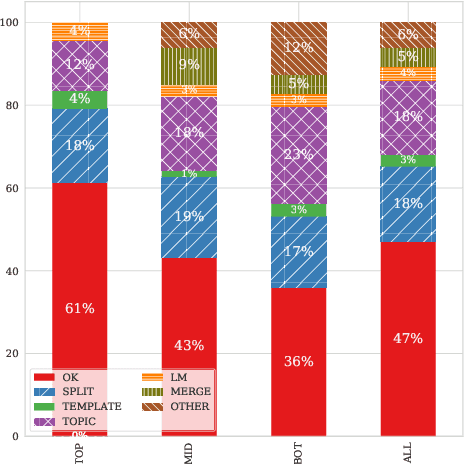
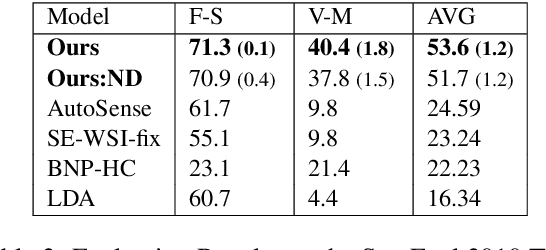

Word sense induction (WSI) is the task of unsupervised clustering of word usages within a sentence to distinguish senses. Recent work obtain strong results by clustering lexical substitutes derived from pre-trained RNN language models (ELMo). Adapting the method to BERT improves the scores even further. We extend the previous method to support a dynamic rather than a fixed number of clusters as supported by other prominent methods, and propose a method for interpreting the resulting clusters by associating them with their most informative substitutes. We then perform extensive error analysis revealing the remaining sources of errors in the WSI task. Our code is available at https://github.com/asafamr/bertwsi.
Where's My Head? Definition, Dataset and Models for Numeric Fused-Heads Identification and Resolution
May 26, 2019We provide the first computational treatment of fused-heads constructions (FH), focusing on the numeric fused-heads (NFH). FHs constructions are noun phrases (NPs) in which the head noun is missing and is said to be `fused' with its dependent modifier. This missing information is implicit and is important for sentence understanding. The missing references are easily filled in by humans but pose a challenge for computational models. We formulate the handling of FH as a two stages process: identification of the FH construction and resolution of the missing head. We explore the NFH phenomena in large corpora of English text and create (1) a dataset and a highly accurate method for NFH identification; (2) a 10k examples (1M tokens) crowd-sourced dataset of NFH resolution; and (3) a neural baseline for the NFH resolution task. We release our code and dataset, in hope to foster further research into this challenging problem.