 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
May 14, 2026Data assimilation (DA) estimates the state of an evolving dynamical system from noisy, partial observations, and is widely used in scientific simulation as well as weather and climate science. In practice, filtering methods rely on frame-to-frame transition models. However, these models are fragile when observations are non-Markovian (when they form only a partial slice of a higher-dimensional latent state as in real-world weather data): they tend to accumulate errors over long horizons. At the same time, learned DA methods typically commit to a single regime, either filtering (nowcasting, real-time forecasting) or smoothing (retrospective reanalysis), which splits what should be a shared prior across application-specific pipelines. To address both issues, we introduce ForcingDAS, a unified and robust DA framework. Built on Diffusion Forcing with an independent noise level assigned to each frame, ForcingDAS learns a joint-trajectory prior instead of frame-to-frame transitions. This allows it to capture long-horizon temporal dependencies and reduce error accumulation. In addition, the same trained model spans the full filtering to smoothing spectrum at inference time. Specifically, nowcasting, fixed-lag smoothing, and batch reanalysis are selected through the inference schedule alone, without retraining. We evaluate ForcingDAS on 2D Navier-Stokes vorticity, precipitation nowcasting, and global atmospheric state estimation. Across all settings, a single model is competitive with or outperforms both learned and classical baselines that are specialized for individual regimes, with the largest gains observed on real-world weather benchmarks.
MCLR: Improving Conditional Modeling in Visual Generative Models via Inter-Class Likelihood-Ratio Maximization and Establishing the Equivalence between Classifier-Free Guidance and Alignment Objectives
Mar 23, 2026Diffusion models have achieved state-of-the-art performance in generative modeling, but their success often relies heavily on classifier-free guidance (CFG), an inference-time heuristic that modifies the sampling trajectory. From a theoretical perspective, diffusion models trained with standard denoising score matching (DSM) are expected to recover the target data distribution, raising the question of why inference-time guidance is necessary in practice. In this work, we ask whether the DSM training objective can be modified in a principled manner such that standard reverse-time sampling, without inference-time guidance, yields effects comparable to CFG. We identify insufficient inter-class separation as a key limitation of standard diffusion models. To address this, we propose MCLR, a principled alignment objective that explicitly maximizes inter-class likelihood-ratios during training. Models fine-tuned with MCLR exhibit CFG-like improvements under standard sampling, achieving comparable qualitative and quantitative gains without requiring inference-time guidance. Beyond empirical benefits, we provide a theoretical result showing that the CFG-guided score is exactly the optimal solution to a weighted MCLR objective. This establishes a formal equivalence between classifier-free guidance and alignment-based objectives, offering a mechanistic interpretation of CFG.
Robust Dynamic Object Detection in Cluttered Indoor Scenes via Learned Spatiotemporal Cues
Mar 16, 2026Reliable dynamic object detection in cluttered environments remains a critical challenge for autonomous navigation. Purely geometric LiDAR pipelines that rely on clustering and heuristic filtering can miss dynamic obstacles when they move in close proximity to static structure or are only partially observed. Vision-augmented approaches can provide additional semantic cues, but are often limited by closed-set detectors and camera field-of-view constraints, reducing robustness to novel obstacles and out-of-frustum events. In this work, we present a LiDAR-only framework that fuses temporal occupancy-grid-based motion segmentation with a learned bird's-eye-view (BEV) dynamic prior. A fusion module prioritizes 3D detections when available, while using the learned dynamic grid to recover detections that would otherwise be lost due to proximity-induced false negatives. Experiments with motion-capture ground truth show our method achieves 28.67% higher recall and 18.50% higher F1 score than the state-of-the-art in substantially cluttered environments while maintaining comparable precision and position error.
Distribution Estimation for Global Data Association via Approximate Bayesian Inference
Sep 19, 2025



Global data association is an essential prerequisite for robot operation in environments seen at different times or by different robots. Repetitive or symmetric data creates significant challenges for existing methods, which typically rely on maximum likelihood estimation or maximum consensus to produce a single set of associations. However, in ambiguous scenarios, the distribution of solutions to global data association problems is often highly multimodal, and such single-solution approaches frequently fail. In this work, we introduce a data association framework that leverages approximate Bayesian inference to capture multiple solution modes to the data association problem, thereby avoiding premature commitment to a single solution under ambiguity. Our approach represents hypothetical solutions as particles that evolve according to a deterministic or randomized update rule to cover the modes of the underlying solution distribution. Furthermore, we show that our method can incorporate optimization constraints imposed by the data association formulation and directly benefit from GPU-parallelized optimization. Extensive simulated and real-world experiments with highly ambiguous data show that our method correctly estimates the distribution over transformations when registering point clouds or object maps.
Terrain-aware Low Altitude Path Planning
May 11, 2025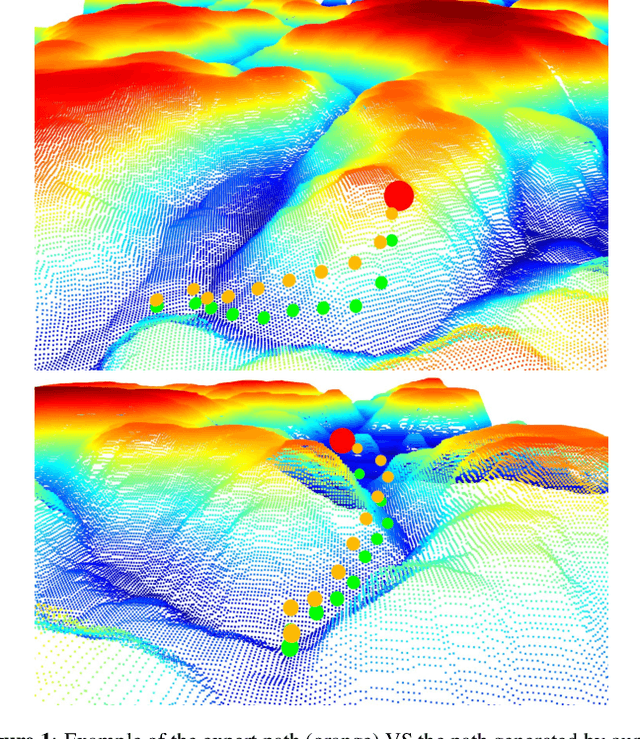
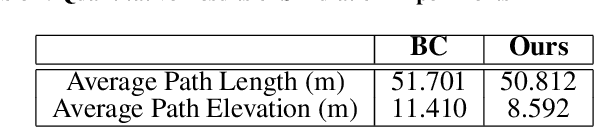
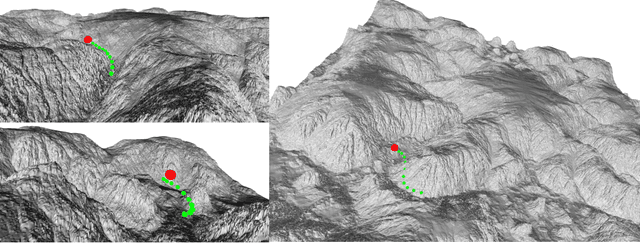
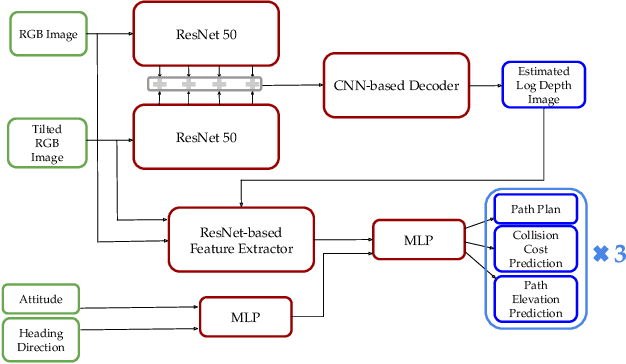
In this paper, we study the problem of generating low altitude path plans for nap-of-the-earth (NOE) flight in real time with only RGB images from onboard cameras and the vehicle pose. We propose a novel training method that combines behavior cloning and self-supervised learning that enables the learned policy to outperform the policy trained with standard behavior cloning approach on this task. Simulation studies are performed on a custom canyon terrain.
Shorter SPECT Scans Using Self-supervised Coordinate Learning to Synthesize Skipped Projection Views
Jun 27, 2024



Purpose: This study addresses the challenge of extended SPECT imaging duration under low-count conditions, as encountered in Lu-177 SPECT imaging, by developing a self-supervised learning approach to synthesize skipped SPECT projection views, thus shortening scan times in clinical settings. Methods: We employed a self-supervised coordinate-based learning technique, adapting the neural radiance field (NeRF) concept in computer vision to synthesize under-sampled SPECT projection views. For each single scan, we used self-supervised coordinate learning to estimate skipped SPECT projection views. The method was tested with various down-sampling factors (DFs=2, 4, 8) on both Lu-177 phantom SPECT/CT measurements and clinical SPECT/CT datasets, from 11 patients undergoing Lu-177 DOTATATE and 6 patients undergoing Lu-177 PSMA-617 radiopharmaceutical therapy. Results: For SPECT reconstructions, our method outperformed the use of linearly interpolated projections and partial projection views in relative contrast-to-noise-ratios (RCNR) averaged across different downsampling factors: 1) DOTATATE: 83% vs. 65% vs. 67% for lesions and 86% vs. 70% vs. 67% for kidney, 2) PSMA: 76% vs. 69% vs. 68% for lesions and 75% vs. 55% vs. 66% for organs, including kidneys, lacrimal glands, parotid glands, and submandibular glands. Conclusion: The proposed method enables reduction in acquisition time (by factors of 2, 4, or 8) while maintaining quantitative accuracy in clinical SPECT protocols by allowing for the collection of fewer projections. Importantly, the self-supervised nature of this NeRF-based approach eliminates the need for extensive training data, instead learning from each patient's projection data alone. The reduction in acquisition time is particularly relevant for imaging under low-count conditions and for protocols that require multiple-bed positions such as whole-body imaging.
Refining Perception Contracts: Case Studies in Vision-based Safe Auto-landing
Nov 15, 2023



Perception contracts provide a method for evaluating safety of control systems that use machine learning for perception. A perception contract is a specification for testing the ML components, and it gives a method for proving end-to-end system-level safety requirements. The feasibility of contract-based testing and assurance was established earlier in the context of straight lane keeping: a 3-dimensional system with relatively simple dynamics. This paper presents the analysis of two 6 and 12-dimensional flight control systems that use multi-stage, heterogeneous, ML-enabled perception. The paper advances methodology by introducing an algorithm for constructing data and requirement guided refinement of perception contracts (DaRePC). The resulting analysis provides testable contracts which establish the state and environment conditions under which an aircraft can safety touchdown on the runway and a drone can safely pass through a sequence of gates. It can also discover conditions (e.g., low-horizon sun) that can possibly violate the safety of the vision-based control system.