 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Motion Factorization for Compositional Video Generation
Mar 10, 2026Compositional video generation aims to synthesize multiple instances with diverse appearance and motion, which is widely applicable in real-world scenarios. However, current approaches mainly focus on binding semantics, neglecting to understand diverse motion categories specified in prompts. In this paper, we propose a motion factorization framework that decomposes complex motion into three primary categories: motionlessness, rigid motion, and non-rigid motion. Specifically, our framework follows a planning before generation paradigm. (1) During planning, we reason about motion laws on the motion graph to obtain frame-wise changes in the shape and position of each instance. This alleviates semantic ambiguities in the user prompt by organizing it into a structured representation of instances and their interactions. (2) During generation, we modulate the synthesis of distinct motion categories in a disentangled manner. Conditioned on the motion cues, guidance branches stabilize appearance in motionless regions, preserve rigid-body geometry, and regularize local non-rigid deformations. Crucially, our two modules are model-agnostic, which can be seamlessly incorporated into various diffusion model architectures. Extensive experiments demonstrate that our framework achieves impressive performance in motion synthesis on real-world benchmarks. Our code will be released soon.
Chain of Event-Centric Causal Thought for Physically Plausible Video Generation
Mar 10, 2026Physically Plausible Video Generation (PPVG) has emerged as a promising avenue for modeling real-world physical phenomena. PPVG requires an understanding of commonsense knowledge, which remains a challenge for video diffusion models. Current approaches leverage commonsense reasoning capability of large language models to embed physical concepts into prompts. However, generation models often render physical phenomena as a single moment defined by prompts, due to the lack of conditioning mechanisms for modeling causal progression. In this paper, we view PPVG as generating a sequence of causally connected and dynamically evolving events. To realize this paradigm, we design two key modules: (1) Physics-driven Event Chain Reasoning. This module decomposes the physical phenomena described in prompts into multiple elementary event units, leveraging chain-of-thought reasoning. To mitigate causal ambiguity, we embed physical formulas as constraints to impose deterministic causal dependencies during reasoning. (2) Transition-aware Cross-modal Prompting (TCP). To maintain continuity between events, this module transforms causal event units into temporally aligned vision-language prompts. It summarizes discrete event descriptions to obtain causally consistent narratives, while progressively synthesizing visual keyframes of individual events by interactive editing. Comprehensive experiments on PhyGenBench and VideoPhy benchmarks demonstrate that our framework achieves superior performance in generating physically plausible videos across diverse physical domains. Our code will be released soon.
Dragen3D: Multiview Geometry Consistent 3D Gaussian Generation with Drag-Based Control
Feb 23, 2025Single-image 3D generation has emerged as a prominent research topic, playing a vital role in virtual reality, 3D modeling, and digital content creation. However, existing methods face challenges such as a lack of multi-view geometric consistency and limited controllability during the generation process, which significantly restrict their usability. % To tackle these challenges, we introduce Dragen3D, a novel approach that achieves geometrically consistent and controllable 3D generation leveraging 3D Gaussian Splatting (3DGS). We introduce the Anchor-Gaussian Variational Autoencoder (Anchor-GS VAE), which encodes a point cloud and a single image into anchor latents and decode these latents into 3DGS, enabling efficient latent-space generation. To enable multi-view geometry consistent and controllable generation, we propose a Seed-Point-Driven strategy: first generate sparse seed points as a coarse geometry representation, then map them to anchor latents via the Seed-Anchor Mapping Module. Geometric consistency is ensured by the easily learned sparse seed points, and users can intuitively drag the seed points to deform the final 3DGS geometry, with changes propagated through the anchor latents. To the best of our knowledge, we are the first to achieve geometrically controllable 3D Gaussian generation and editing without relying on 2D diffusion priors, delivering comparable 3D generation quality to state-of-the-art methods.
CoverTheFace: face covering monitoring and demonstrating using deep learning and statistical shape analysis
Aug 23, 2021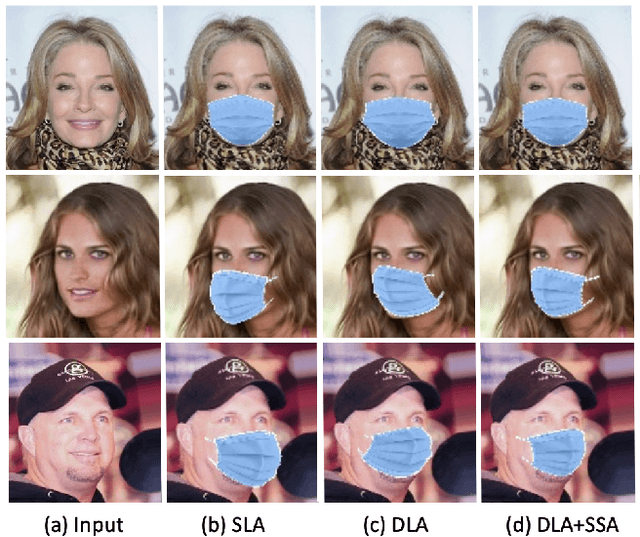

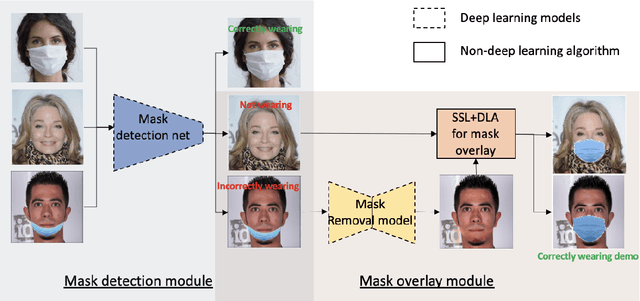
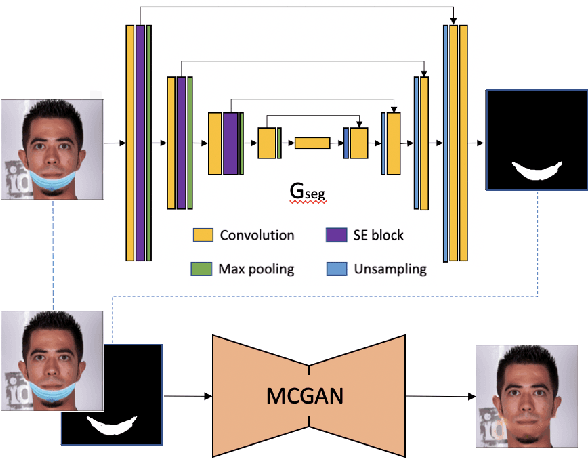
Wearing a mask is a strong protection against the COVID-19 pandemic, even though the vaccine has been successfully developed and is widely available. However, many people wear them incorrectly. This observation prompts us to devise an automated approach to monitor the condition of people wearing masks. Unlike previous studies, our work goes beyond mask detection; it focuses on generating a personalized demonstration on proper mask-wearing, which helps people use masks better through visual demonstration rather than text explanation. The pipeline starts from the detection of face covering. For images where faces are improperly covered, our mask overlay module incorporates statistical shape analysis (SSA) and dense landmark alignment to approximate the geometry of a face and generates corresponding face-covering examples. Our results show that the proposed system successfully identifies images with faces covered properly. Our ablation study on mask overlay suggests that the SSA model helps to address variations in face shapes, orientations, and scales. The final face-covering examples, especially half profile face images, surpass previous arts by a noticeable margin.