 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMCE: Probabilistic Multi-Granularity Semantics with Caption-Guided Enhancement for Few-Shot Learning
Jan 20, 2026Few-shot learning aims to identify novel categories from only a handful of labeled samples, where prototypes estimated from scarce data are often biased and generalize poorly. Semantic-based methods alleviate this by introducing coarse class-level information, but they are mostly applied on the support side, leaving query representations unchanged. In this paper, we present PMCE, a Probabilistic few-shot framework that leverages Multi-granularity semantics with Caption-guided Enhancement. PMCE constructs a nonparametric knowledge bank that stores visual statistics for each category as well as CLIP-encoded class name embeddings of the base classes. At meta-test time, the most relevant base classes are retrieved based on the similarities of class name embeddings for each novel category. These statistics are then aggregated into category-specific prior information and fused with the support set prototypes via a simple MAP update. Simultaneously, a frozen BLIP captioner provides label-free instance-level image descriptions, and a lightweight enhancer trained on base classes optimizes both support prototypes and query features under an inductive protocol with a consistency regularization to stabilize noisy captions. Experiments on four benchmarks show that PMCE consistently improves over strong baselines, achieving up to 7.71% absolute gain over the strongest semantic competitor on MiniImageNet in the 1-shot setting. Our code is available at https://anonymous.4open.science/r/PMCE-275D
UltraLogic: Enhancing LLM Reasoning through Large-Scale Data Synthesis and Bipolar Float Reward
Jan 06, 2026While Large Language Models (LLMs) have demonstrated significant potential in natural language processing , complex general-purpose reasoning requiring multi-step logic, planning, and verification remains a critical bottleneck. Although Reinforcement Learning with Verifiable Rewards (RLVR) has succeeded in specific domains , the field lacks large-scale, high-quality, and difficulty-calibrated data for general reasoning. To address this, we propose UltraLogic, a framework that decouples the logical core of a problem from its natural language expression through a Code-based Solving methodology to automate high-quality data production. The framework comprises hundreds of unique task types and an automated calibration pipeline across ten difficulty levels. Furthermore, to mitigate binary reward sparsity and the Non-negative Reward Trap, we introduce the Bipolar Float Reward (BFR) mechanism, utilizing graded penalties to effectively distinguish perfect responses from those with logical flaws. Our experiments demonstrate that task diversity is the primary driver for reasoning enhancement , and that BFR, combined with a difficulty matching strategy, significantly improves training efficiency, guiding models toward global logical optima.
SGE net: Video object detection with squeezed GRU and information entropy map
Jun 14, 2021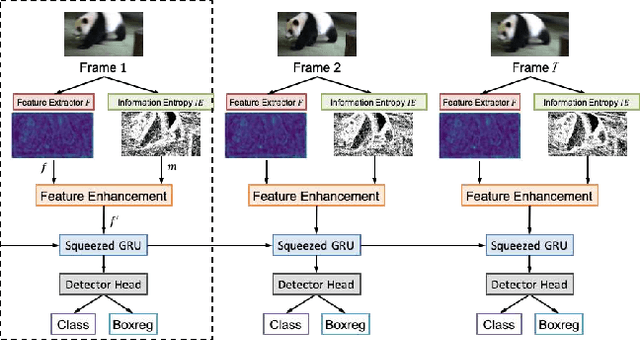
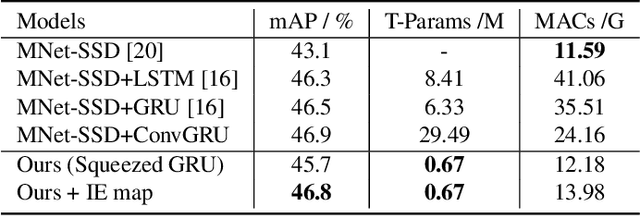
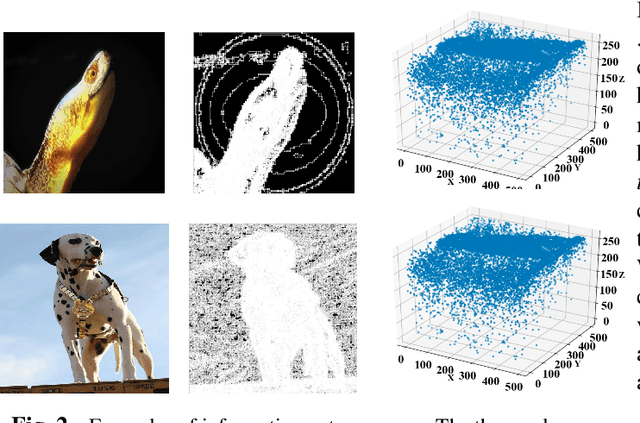
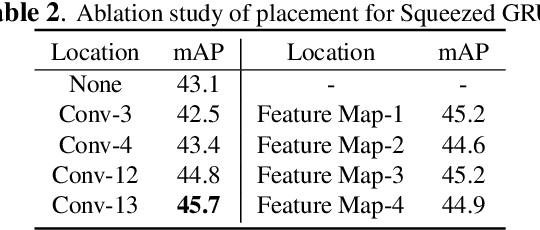
Recently, deep learning based video object detection has attracted more and more attention. Compared with object detection of static images, video object detection is more challenging due to the motion of objects, while providing rich temporal information. The RNN-based algorithm is an effective way to enhance detection performance in videos with temporal information. However, most studies in this area only focus on accuracy while ignoring the calculation cost and the number of parameters. In this paper, we propose an efficient method that combines channel-reduced convolutional GRU (Squeezed GRU), and Information Entropy map for video object detection (SGE-Net). The experimental results validate the accuracy improvement, computational savings of the Squeezed GRU, and superiority of the information entropy attention mechanism on the classification performance. The mAP has increased by 3.7 contrasted with the baseline, and the number of parameters has decreased from 6.33 million to 0.67 million compared with the standard GRU.
A Semi-Supervised Classification Method of Apicomplexan Parasites and Host Cell Using Contrastive Learning Strategy
Apr 14, 2021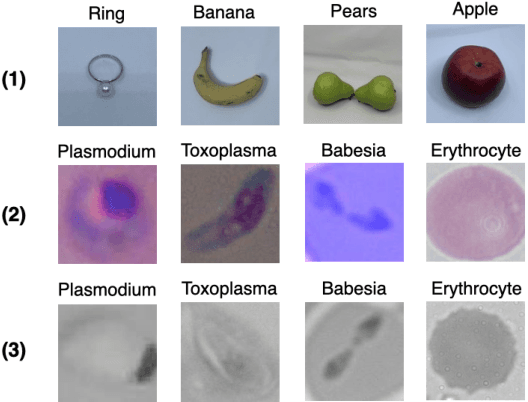
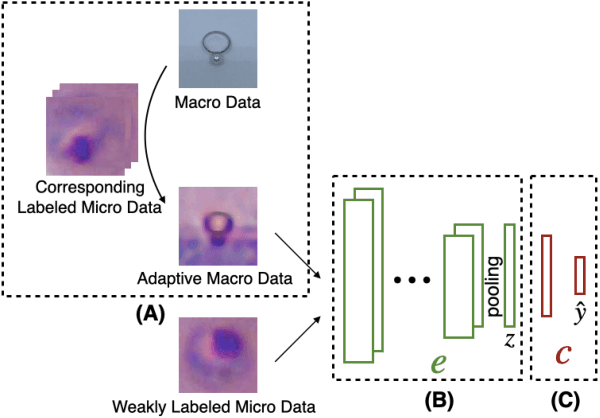
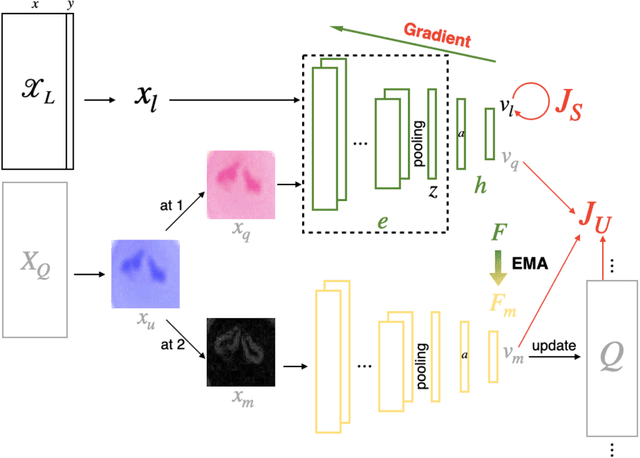
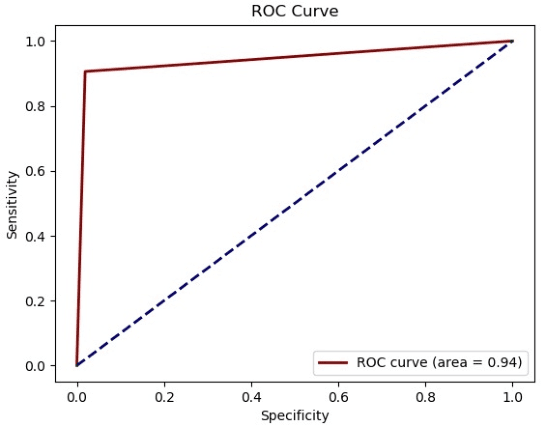
A common shortfall of supervised learning for medical imaging is the greedy need for human annotations, which is often expensive and time-consuming to obtain. This paper proposes a semi-supervised classification method for three kinds of apicomplexan parasites and non-infected host cells microscopic images, which uses a small number of labeled data and a large number of unlabeled data for training. There are two challenges in microscopic image recognition. The first is that salient structures of the microscopic images are more fuzzy and intricate than natural images' on a real-world scale. The second is that insignificant textures, like background staining, lightness, and contrast level, vary a lot in samples from different clinical scenarios. To address these challenges, we aim to learn a distinguishable and appearance-invariant representation by contrastive learning strategy. On one hand, macroscopic images, which share similar shape characteristics in morphology, are introduced to contrast for structure enhancement. On the other hand, different appearance transformations, including color distortion and flittering, are utilized to contrast for texture elimination. In the case where only 1% of microscopic images are labeled, the proposed method reaches an accuracy of 94.90% in a generalized testing set.