 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging GPT-4 for Food Effect Summarization to Enhance Product-Specific Guidance Development via Iterative Prompting
Jun 28, 2023



Food effect summarization from New Drug Application (NDA) is an essential component of product-specific guidance (PSG) development and assessment. However, manual summarization of food effect from extensive drug application review documents is time-consuming, which arouses a need to develop automated methods. Recent advances in large language models (LLMs) such as ChatGPT and GPT-4, have demonstrated great potential in improving the effectiveness of automated text summarization, but its ability regarding the accuracy in summarizing food effect for PSG assessment remains unclear. In this study, we introduce a simple yet effective approach, iterative prompting, which allows one to interact with ChatGPT or GPT-4 more effectively and efficiently through multi-turn interaction. Specifically, we propose a three-turn iterative prompting approach to food effect summarization in which the keyword-focused and length-controlled prompts are respectively provided in consecutive turns to refine the quality of the generated summary. We conduct a series of extensive evaluations, ranging from automated metrics to FDA professionals and even evaluation by GPT-4, on 100 NDA review documents selected over the past five years. We observe that the summary quality is progressively improved throughout the process. Moreover, we find that GPT-4 performs better than ChatGPT, as evaluated by FDA professionals (43% vs. 12%) and GPT-4 (64% vs. 35%). Importantly, all the FDA professionals unanimously rated that 85% of the summaries generated by GPT-4 are factually consistent with the golden reference summary, a finding further supported by GPT-4 rating of 72% consistency. These results strongly suggest a great potential for GPT-4 to draft food effect summaries that could be reviewed by FDA professionals, thereby improving the efficiency of PSG assessment cycle and promoting the generic drug product development.
Fine-Tuning BERT for Automatic ADME Semantic Labeling in FDA Drug Labeling to Enhance Product-Specific Guidance Assessment
Jul 25, 2022

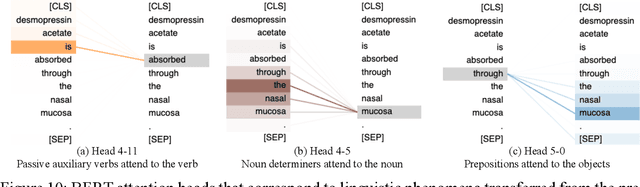
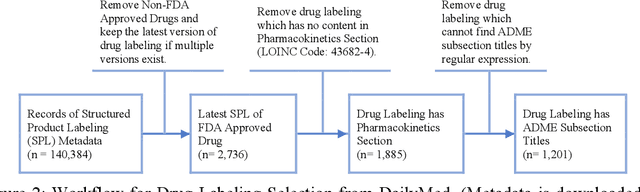
Product-specific guidances (PSGs) recommended by the United States Food and Drug Administration (FDA) are instrumental to promote and guide generic drug product development. To assess a PSG, the FDA assessor needs to take extensive time and effort to manually retrieve supportive drug information of absorption, distribution, metabolism, and excretion (ADME) from the reference listed drug labeling. In this work, we leveraged the state-of-the-art pre-trained language models to automatically label the ADME paragraphs in the pharmacokinetics section from the FDA-approved drug labeling to facilitate PSG assessment. We applied a transfer learning approach by fine-tuning the pre-trained Bidirectional Encoder Representations from Transformers (BERT) model to develop a novel application of ADME semantic labeling, which can automatically retrieve ADME paragraphs from drug labeling instead of manual work. We demonstrated that fine-tuning the pre-trained BERT model can outperform the conventional machine learning techniques, achieving up to 11.6% absolute F1 improvement. To our knowledge, we were the first to successfully apply BERT to solve the ADME semantic labeling task. We further assessed the relative contribution of pre-training and fine-tuning to the overall performance of the BERT model in the ADME semantic labeling task using a series of analysis methods such as attention similarity and layer-based ablations. Our analysis revealed that the information learned via fine-tuning is focused on task-specific knowledge in the top layers of the BERT, whereas the benefit from the pre-trained BERT model is from the bottom layers.
Two-Stage Fine-Tuning: A Novel Strategy for Learning Class-Imbalanced Data
Jul 22, 2022
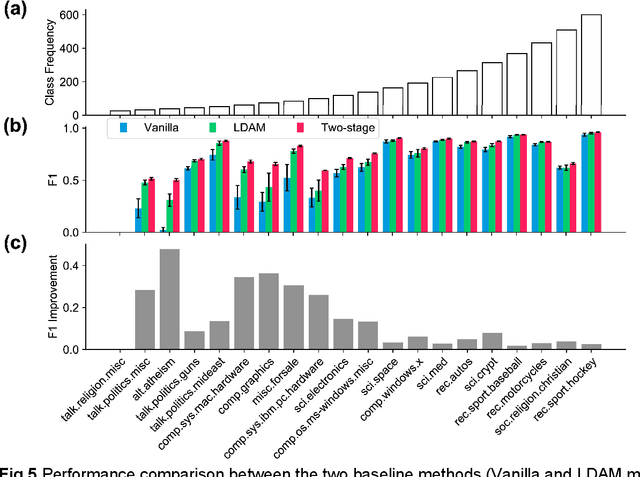
Classification on long-tailed distributed data is a challenging problem, which suffers from serious class-imbalance and hence poor performance on tail classes with only a few samples. Owing to this paucity of samples, learning on the tail classes is especially challenging for the fine-tuning when transferring a pretrained model to a downstream task. In this work, we present a simple modification of standard fine-tuning to cope with these challenges. Specifically, we propose a two-stage fine-tuning: we first fine-tune the final layer of the pretrained model with class-balanced reweighting loss, and then we perform the standard fine-tuning. Our modification has several benefits: (1) it leverages pretrained representations by only fine-tuning a small portion of the model parameters while keeping the rest untouched; (2) it allows the model to learn an initial representation of the specific task; and importantly (3) it protects the learning of tail classes from being at a disadvantage during the model updating. We conduct extensive experiments on synthetic datasets of both two-class and multi-class tasks of text classification as well as a real-world application to ADME (i.e., absorption, distribution, metabolism, and excretion) semantic labeling. The experimental results show that the proposed two-stage fine-tuning outperforms both fine-tuning with conventional loss and fine-tuning with a reweighting loss on the above datasets.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).