 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture-of-Expert Approach to RL-based Dialogue Management
May 31, 2022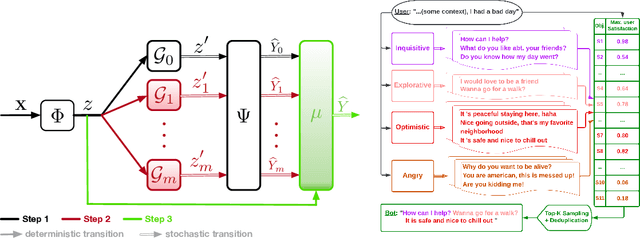

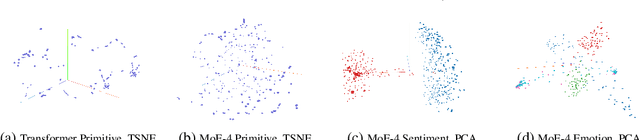

Despite recent advancements in language models (LMs), their application to dialogue management (DM) problems and ability to carry on rich conversations remain a challenge. We use reinforcement learning (RL) to develop a dialogue agent that avoids being short-sighted (outputting generic utterances) and maximizes overall user satisfaction. Most existing RL approaches to DM train the agent at the word-level, and thus, have to deal with a combinatorially complex action space even for a medium-size vocabulary. As a result, they struggle to produce a successful and engaging dialogue even if they are warm-started with a pre-trained LM. To address this issue, we develop a RL-based DM using a novel mixture of expert language model (MoE-LM) that consists of (i) a LM capable of learning diverse semantics for conversation histories, (ii) a number of {\em specialized} LMs (or experts) capable of generating utterances corresponding to a particular attribute or personality, and (iii) a RL-based DM that performs dialogue planning with the utterances generated by the experts. Our MoE approach provides greater flexibility to generate sensible utterances with different intents and allows RL to focus on conversational-level DM. We compare it with SOTA baselines on open-domain dialogues and demonstrate its effectiveness both in terms of the diversity and sensibility of the generated utterances and the overall DM performance.
Efficient Risk-Averse Reinforcement Learning
May 10, 2022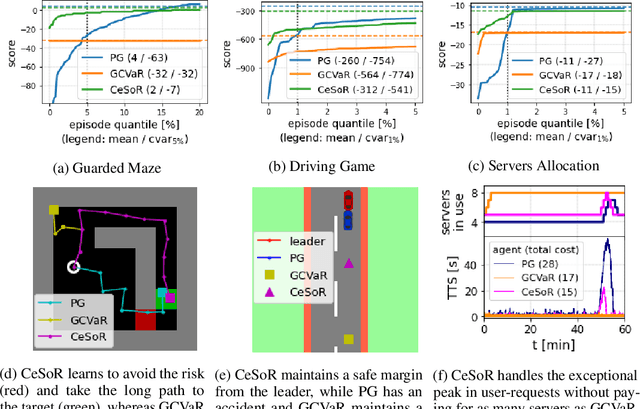
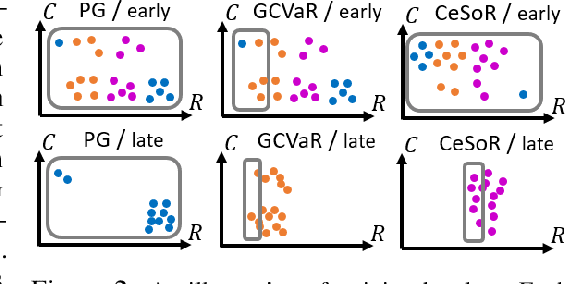
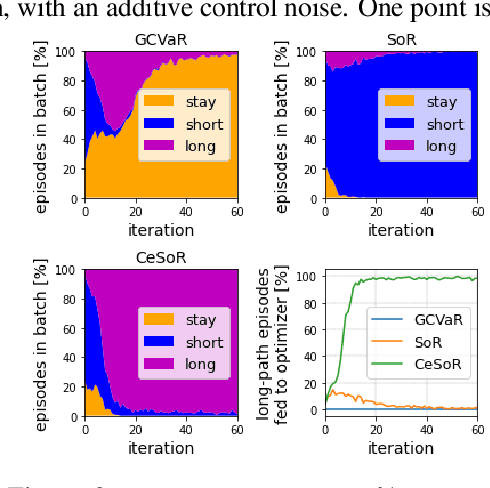
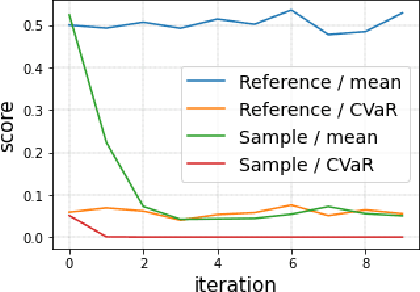
In risk-averse reinforcement learning (RL), the goal is to optimize some risk measure of the returns. A risk measure often focuses on the worst returns out of the agent's experience. As a result, standard methods for risk-averse RL often ignore high-return strategies. We prove that under certain conditions this inevitably leads to a local-optimum barrier, and propose a soft risk mechanism to bypass it. We also devise a novel Cross Entropy module for risk sampling, which (1) preserves risk aversion despite the soft risk; (2) independently improves sample efficiency. By separating the risk aversion of the sampler and the optimizer, we can sample episodes with poor conditions, yet optimize with respect to successful strategies. We combine these two concepts in CeSoR - Cross-entropy Soft-Risk optimization algorithm - which can be applied on top of any risk-averse policy gradient (PG) method. We demonstrate improved risk aversion in maze navigation, autonomous driving, and resource allocation benchmarks, including in scenarios where standard risk-averse PG completely fails.
SAFER: Data-Efficient and Safe Reinforcement Learning via Skill Acquisition
Feb 10, 2022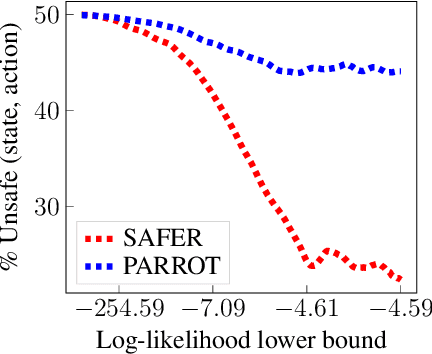
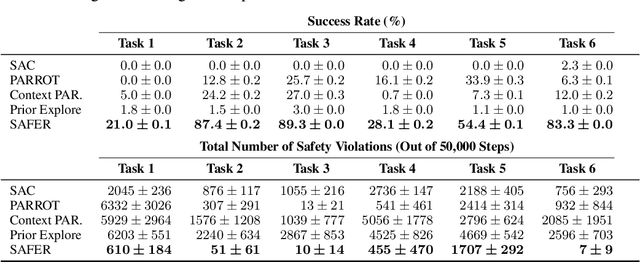
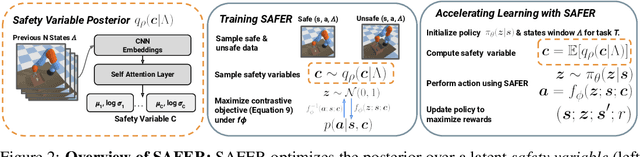
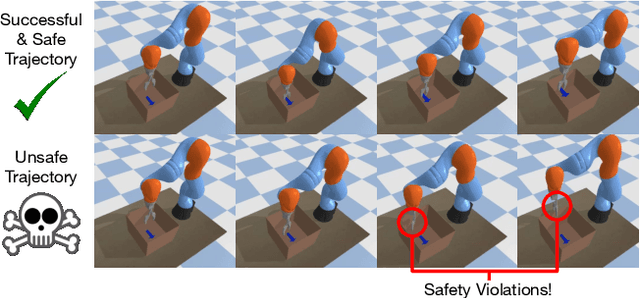
Though many reinforcement learning (RL) problems involve learning policies in settings with difficult-to-specify safety constraints and sparse rewards, current methods struggle to acquire successful and safe policies. Methods that extract useful policy primitives from offline datasets using generative modeling have recently shown promise at accelerating RL in these more complex settings. However, we discover that current primitive-learning methods may not be well-equipped for safe policy learning and may promote unsafe behavior due to their tendency to ignore data from undesirable behaviors. To overcome these issues, we propose SAFEty skill pRiors (SAFER), an algorithm that accelerates policy learning on complex control tasks under safety constraints. Through principled training on an offline dataset, SAFER learns to extract safe primitive skills. In the inference stage, policies trained with SAFER learn to compose safe skills into successful policies. We theoretically characterize why SAFER can enforce safe policy learning and demonstrate its effectiveness on several complex safety-critical robotic grasping tasks inspired by the game Operation, in which SAFER outperforms baseline methods in learning successful policies and enforcing safety.
Discovering Personalized Semantics for Soft Attributes in Recommender Systems using Concept Activation Vectors
Feb 06, 2022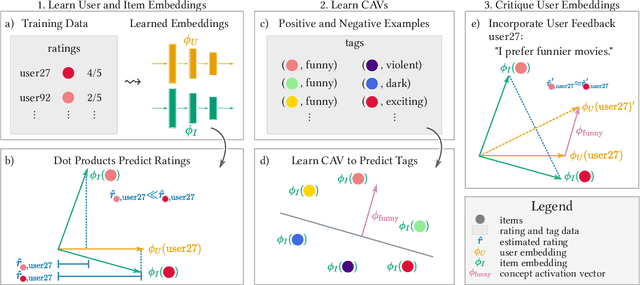


Interactive recommender systems (RSs) allow users to express intent, preferences and contexts in a rich fashion, often using natural language. One challenge in using such feedback is inferring a user's semantic intent from the open-ended terms used to describe an item, and using it to refine recommendation results. Leveraging concept activation vectors (CAVs) [21], we develop a framework to learn a representation that captures the semantics of such attributes and connects them to user preferences and behaviors in RSs. A novel feature of our approach is its ability to distinguish objective and subjective attributes and associate different senses with different users. Using synthetic and real-world datasets, we show that our CAV representation accurately interprets users' subjective semantics, and can improve recommendations via interactive critiquing
Non-Stationary Latent Bandits
Dec 01, 2020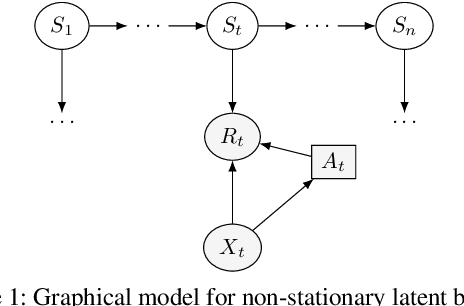
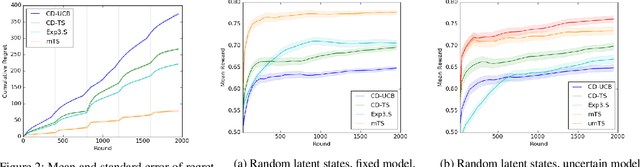
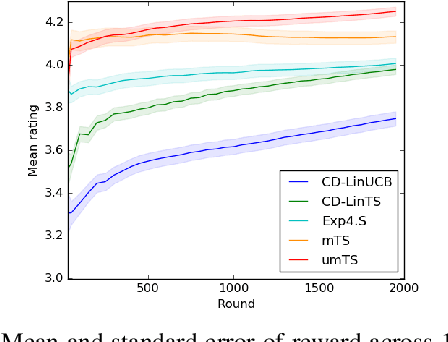
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
CoinDICE: Off-Policy Confidence Interval Estimation
Oct 22, 2020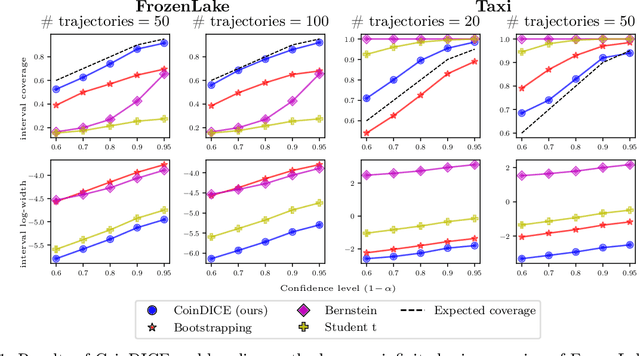
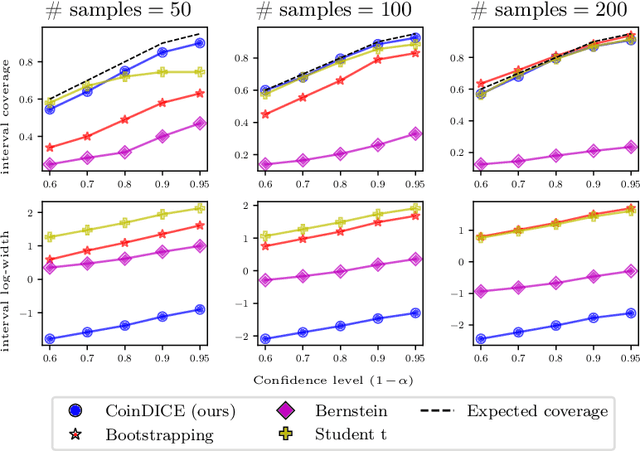
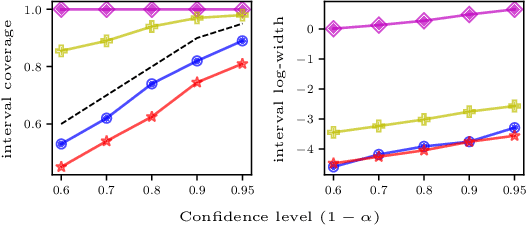
We study high-confidence behavior-agnostic off-policy evaluation in reinforcement learning, where the goal is to estimate a confidence interval on a target policy's value, given only access to a static experience dataset collected by unknown behavior policies. Starting from a function space embedding of the linear program formulation of the $Q$-function, we obtain an optimization problem with generalized estimating equation constraints. By applying the generalized empirical likelihood method to the resulting Lagrangian, we propose CoinDICE, a novel and efficient algorithm for computing confidence intervals. Theoretically, we prove the obtained confidence intervals are valid, in both asymptotic and finite-sample regimes. Empirically, we show in a variety of benchmarks that the confidence interval estimates are tighter and more accurate than existing methods.
Safe Reinforcement Learning with Natural Language Constraints
Oct 11, 2020
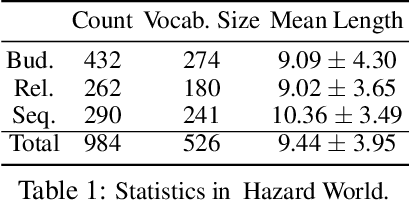
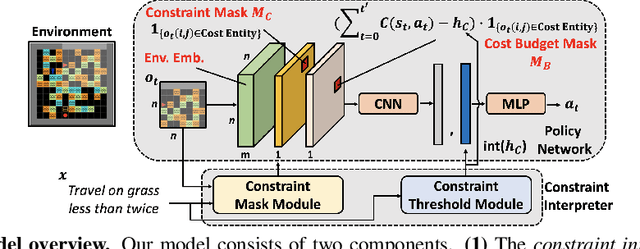
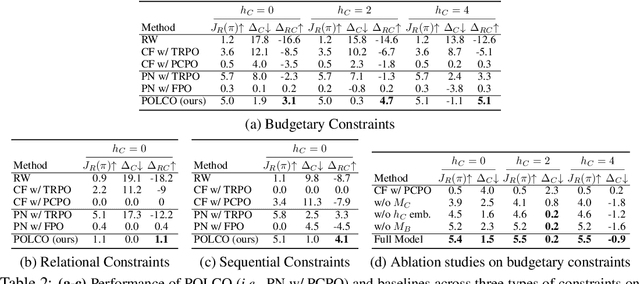
In this paper, we tackle the problem of learning control policies for tasks when provided with constraints in natural language. In contrast to instruction following, language here is used not to specify goals, but rather to describe situations that an agent must avoid during its exploration of the environment. Specifying constraints in natural language also differs from the predominant paradigm in safe reinforcement learning, where safety criteria are enforced by hand-defined cost functions. While natural language allows for easy and flexible specification of safety constraints and budget limitations, its ambiguous nature presents a challenge when mapping these specifications into representations that can be used by techniques for safe reinforcement learning. To address this, we develop a model that contains two components: (1) a constraint interpreter to encode natural language constraints into vector representations capturing spatial and temporal information on forbidden states, and (2) a policy network that uses these representations to output a policy with minimal constraint violations. Our model is end-to-end differentiable and we train it using a recently proposed algorithm for constrained policy optimization. To empirically demonstrate the effectiveness of our approach, we create a new benchmark task for autonomous navigation with crowd-sourced free-form text specifying three different types of constraints. Our method outperforms several baselines by achieving 6-7 times higher returns and 76% fewer constraint violations on average. Dataset and code to reproduce our experiments are available at https://sites.google.com/view/polco-hazard-world/.
Variational Model-based Policy Optimization
Jun 24, 2020
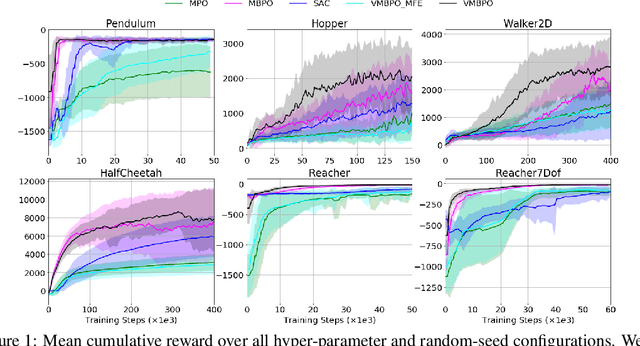
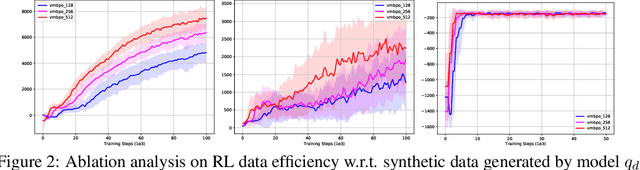
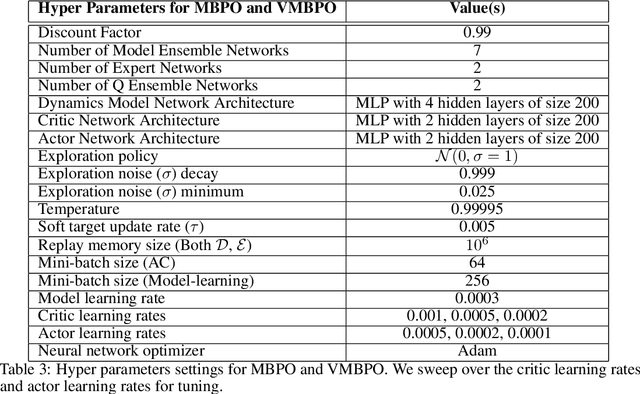
Model-based reinforcement learning (RL) algorithms allow us to combine model-generated data with those collected from interaction with the real system in order to alleviate the data efficiency problem in RL. However, designing such algorithms is often challenging because the bias in simulated data may overshadow the ease of data generation. A potential solution to this challenge is to jointly learn and improve model and policy using a universal objective function. In this paper, we leverage the connection between RL and probabilistic inference, and formulate such an objective function as a variational lower-bound of a log-likelihood. This allows us to use expectation maximization (EM) and iteratively fix a baseline policy and learn a variational distribution, consisting of a model and a policy (E-step), followed by improving the baseline policy given the learned variational distribution (M-step). We propose model-based and model-free policy iteration (actor-critic) style algorithms for the E-step and show how the variational distribution learned by them can be used to optimize the M-step in a fully model-based fashion. Our experiments on a number of continuous control tasks show that despite being more complex, our model-based (E-step) algorithm, called {\em variational model-based policy optimization} (VMBPO), is more sample-efficient and robust to hyper-parameter tuning than its model-free (E-step) counterpart. Using the same control tasks, we also compare VMBPO with several state-of-the-art model-based and model-free RL algorithms and show its sample efficiency and performance.
Control-Aware Representations for Model-based Reinforcement Learning
Jun 24, 2020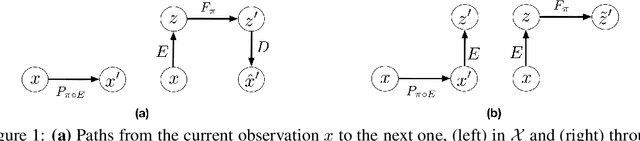

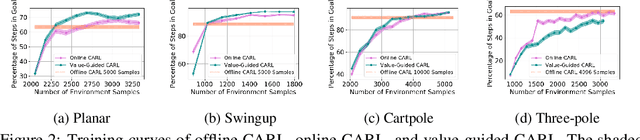
A major challenge in modern reinforcement learning (RL) is efficient control of dynamical systems from high-dimensional sensory observations. Learning controllable embedding (LCE) is a promising approach that addresses this challenge by embedding the observations into a lower-dimensional latent space, estimating the latent dynamics, and utilizing it to perform control in the latent space. Two important questions in this area are how to learn a representation that is amenable to the control problem at hand, and how to achieve an end-to-end framework for representation learning and control. In this paper, we take a few steps towards addressing these questions. We first formulate a LCE model to learn representations that are suitable to be used by a policy iteration style algorithm in the latent space. We call this model control-aware representation learning (CARL). We derive a loss function for CARL that has close connection to the prediction, consistency, and curvature (PCC) principle for representation learning. We derive three implementations of CARL. In the offline implementation, we replace the locally-linear control algorithm (e.g.,~iLQR) used by the existing LCE methods with a RL algorithm, namely model-based soft actor-critic, and show that it results in significant improvement. In online CARL, we interleave representation learning and control, and demonstrate further gain in performance. Finally, we propose value-guided CARL, a variation in which we optimize a weighted version of the CARL loss function, where the weights depend on the TD-error of the current policy. We evaluate the proposed algorithms by extensive experiments on benchmark tasks and compare them with several LCE baselines.
Latent Bandits Revisited
Jun 15, 2020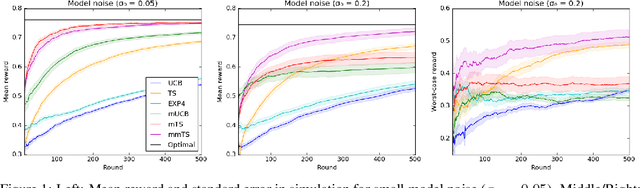
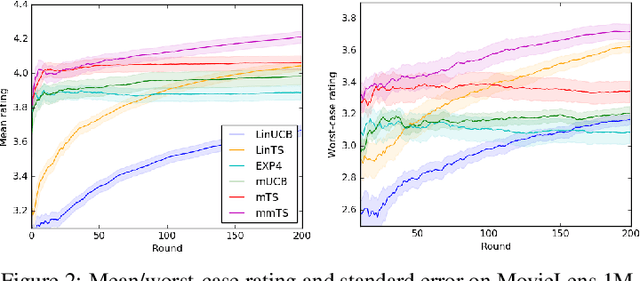
A latent bandit problem is one in which the learning agent knows the arm reward distributions conditioned on an unknown discrete latent state. The primary goal of the agent is to identify the latent state, after which it can act optimally. This setting is a natural midpoint between online and offline learning---complex models can be learned offline with the agent identifying latent state online---of practical relevance in, say, recommender systems. In this work, we propose general algorithms for this setting, based on both upper confidence bounds (UCBs) and Thompson sampling. Our methods are contextual and aware of model uncertainty and misspecification. We provide a unified theoretical analysis of our algorithms, which have lower regret than classic bandit policies when the number of latent states is smaller than actions. A comprehensive empirical study showcases the advantages of our approach.