 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Multi-Modal Planning for Fixed-Altitude Sparse Target Search and Sampling
Mar 09, 2026Efficient monitoring of sparse benthic phenomena, such as coral colonies, presents a great challenge for Autonomous Underwater Vehicles. Traditional exhaustive coverage strategies are energy-inefficient, while recent adaptive sampling approaches rely on costly vertical maneuvers. To address these limitations, we propose HIMoS (Hierarchical Informative Multi-Modal Search), a fixed-altitude framework for sparse coral search-and-sample missions. The system integrates a heterogeneous sensor suite within a two-layer planning architecture. At the strategic level, a Global Planner optimizes topological routes to maximize potential discovery. At the tactical level, a receding-horizon Local Planner leverages differentiable belief propagation to generate kinematically feasible trajectories that balance acoustic substrate exploration, visual coral search, and close-range sampling. Validated in high-fidelity simulations derived from real-world coral reef benthic surveys, our approach demonstrates superior mission efficiency compared to state-of-the-art baselines.
Let Samples Speak: Mitigating Spurious Correlation by Exploiting the Clusterness of Samples
Dec 28, 2025Deep learning models are known to often learn features that spuriously correlate with the class label during training but are irrelevant to the prediction task. Existing methods typically address this issue by annotating potential spurious attributes, or filtering spurious features based on some empirical assumptions (e.g., simplicity of bias). However, these methods may yield unsatisfactory performance due to the intricate and elusive nature of spurious correlations in real-world data. In this paper, we propose a data-oriented approach to mitigate the spurious correlation in deep learning models. We observe that samples that are influenced by spurious features tend to exhibit a dispersed distribution in the learned feature space. This allows us to identify the presence of spurious features. Subsequently, we obtain a bias-invariant representation by neutralizing the spurious features based on a simple grouping strategy. Then, we learn a feature transformation to eliminate the spurious features by aligning with this bias-invariant representation. Finally, we update the classifier by incorporating the learned feature transformation and obtain an unbiased model. By integrating the aforementioned identifying, neutralizing, eliminating and updating procedures, we build an effective pipeline for mitigating spurious correlation. Experiments on image and NLP debiasing benchmarks show an improvement in worst group accuracy of more than 20% compared to standard empirical risk minimization (ERM). Codes and checkpoints are available at https://github.com/davelee-uestc/nsf_debiasing .
Symskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation
Oct 02, 2025Multi-step manipulation in dynamic environments remains challenging. Two major families of methods fail in distinct ways: (i) imitation learning (IL) is reactive but lacks compositional generalization, as monolithic policies do not decide which skill to reuse when scenes change; (ii) classical task-and-motion planning (TAMP) offers compositionality but has prohibitive planning latency, preventing real-time failure recovery. We introduce SymSkill, a unified learning framework that combines the benefits of IL and TAMP, allowing compositional generalization and failure recovery in real-time. Offline, SymSkill jointly learns predicates, operators, and skills directly from unlabeled and unsegmented demonstrations. At execution time, upon specifying a conjunction of one or more learned predicates, SymSkill uses a symbolic planner to compose and reorder learned skills to achieve the symbolic goals, while performing recovery at both the motion and symbolic levels in real time. Coupled with a compliant controller, SymSkill enables safe and uninterrupted execution under human and environmental disturbances. In RoboCasa simulation, SymSkill can execute 12 single-step tasks with 85% success rate. Without additional data, it composes these skills into multi-step plans requiring up to 6 skill recompositions, recovering robustly from execution failures. On a real Franka robot, we demonstrate SymSkill, learning from 5 minutes of unsegmented and unlabeled play data, is capable of performing multiple tasks simply by goal specifications. The source code and additional analysis can be found on https://sites.google.com/view/symskill.
Make Both Ends Meet: A Synergistic Optimization Infrared Small Target Detection with Streamlined Computational Overhead
Apr 30, 2025
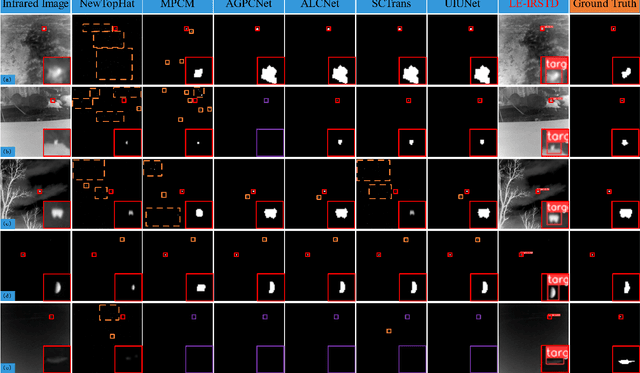
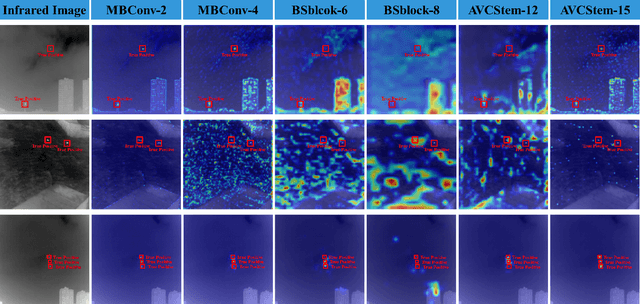
Infrared small target detection(IRSTD) is widely recognized as a challenging task due to the inherent limitations of infrared imaging, including low signal-to-noise ratios, lack of texture details, and complex background interference. While most existing methods model IRSTD as a semantic segmentation task, but they suffer from two critical drawbacks: (1)blurred target boundaries caused by long-distance imaging dispersion; and (2) excessive computational overhead due to indiscriminate feature stackin. To address these issues, we propose the Lightweight Efficiency Infrared Small Target Detection (LE-IRSTD), a lightweight and efficient framework based on YOLOv8n, with following key innovations. Firstly, we identify that the multiple bottleneck structures within the C2f component of the YOLOv8-n backbone contribute to an increased computational burden. Therefore, we implement the Mobile Inverted Bottleneck Convolution block (MBConvblock) and Bottleneck Structure block (BSblock) in the backbone, effectively balancing the trade-off between computational efficiency and the extraction of deep semantic information. Secondly, we introduce the Attention-based Variable Convolution Stem (AVCStem) structure, substituting the final convolution with Variable Kernel Convolution (VKConv), which allows for adaptive convolutional kernels that can transform into various shapes, facilitating the receptive field for the extraction of targets. Finally, we employ Global Shuffle Convolution (GSConv) to shuffle the channel dimension features obtained from different convolutional approaches, thereby enhancing the robustness and generalization capabilities of our method. Experimental results demonstrate that our LE-IRSTD method achieves compelling results in both accuracy and lightweight performance, outperforming several state-of-the-art deep learning methods.
Selective Variable Convolution Meets Dynamic Content Guided Attention for Infrared Small Target Detection
Apr 30, 2025
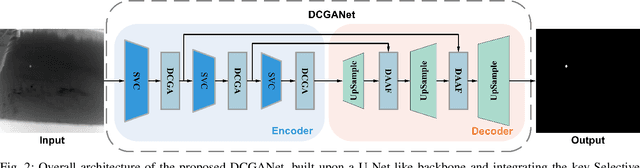
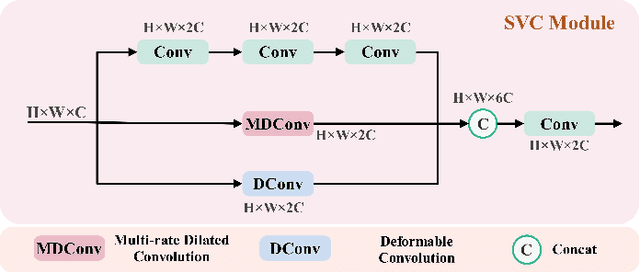
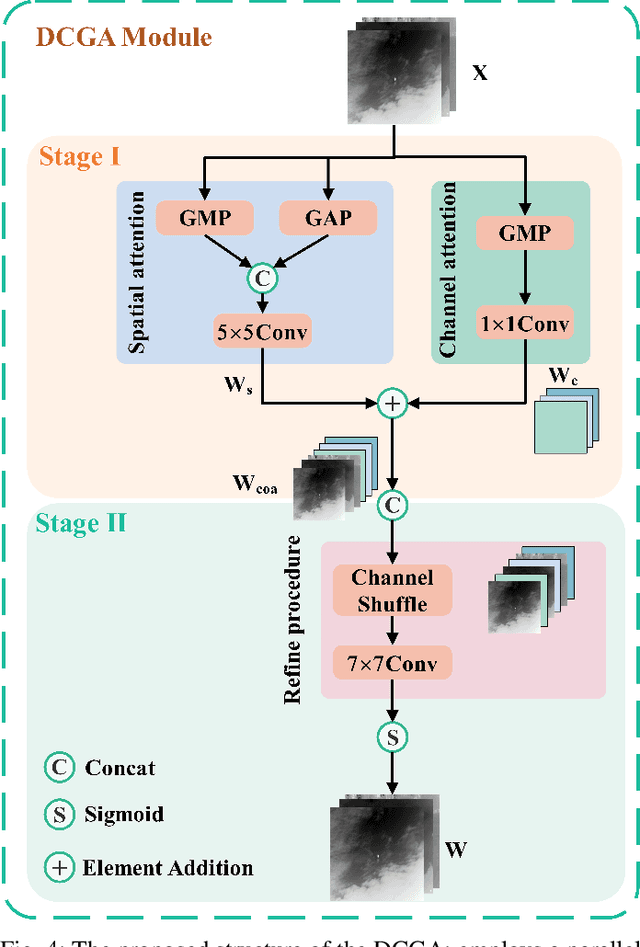
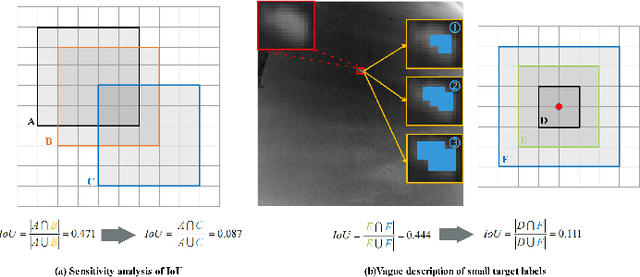
Infrared Small Target Detection (IRSTD) system aims to identify small targets in complex backgrounds. Due to the convolution operation in Convolutional Neural Networks (CNNs), applying traditional CNNs to IRSTD presents challenges, since the feature extraction of small targets is often insufficient, resulting in the loss of critical features. To address these issues, we propose a dynamic content guided attention multiscale feature aggregation network (DCGANet), which adheres to the attention principle of 'coarse-to-fine' and achieves high detection accuracy. First, we propose a selective variable convolution (SVC) module that integrates the benefits of standard convolution, irregular deformable convolution, and multi-rate dilated convolution. This module is designed to expand the receptive field and enhance non-local features, thereby effectively improving the discrimination of targets from backgrounds. Second, the core component of DCGANet is a two-stage content guided attention module. This module employs two-stage attention mechanism to initially direct the network's focus to salient regions within the feature maps and subsequently determine whether these regions correspond to targets or background interference. By retaining the most significant responses, this mechanism effectively suppresses false alarms. Additionally, we propose adaptive dynamic feature fusion (ADFF) module to substitute for static feature cascading. This dynamic feature fusion strategy enables DCGANet to adaptively integrate contextual features, thereby enhancing its ability to discriminate true targets from false alarms. DCGANet has achieved new benchmarks across multiple datasets.
LAM-YOLO: Drones-based Small Object Detection on Lighting-Occlusion Attention Mechanism YOLO
Nov 01, 2024



Drone-based target detection presents inherent challenges, such as the high density and overlap of targets in drone-based images, as well as the blurriness of targets under varying lighting conditions, which complicates identification. Traditional methods often struggle to recognize numerous densely packed small targets under complex background. To address these challenges, we propose LAM-YOLO, an object detection model specifically designed for drone-based. First, we introduce a light-occlusion attention mechanism to enhance the visibility of small targets under different lighting conditions. Meanwhile, we incroporate incorporate Involution modules to improve interaction among feature layers. Second, we utilize an improved SIB-IoU as the regression loss function to accelerate model convergence and enhance localization accuracy. Finally, we implement a novel detection strategy that introduces two auxiliary detection heads for identifying smaller-scale targets.Our quantitative results demonstrate that LAM-YOLO outperforms methods such as Faster R-CNN, YOLOv9, and YOLOv10 in terms of mAP@0.5 and mAP@0.5:0.95 on the VisDrone2019 public dataset. Compared to the original YOLOv8, the average precision increases by 7.1\%. Additionally, the proposed SIB-IoU loss function shows improved faster convergence speed during training and improved average precision over the traditional loss function.
Optimal Rejection Function Meets Character Recognition Tasks
Mar 17, 2022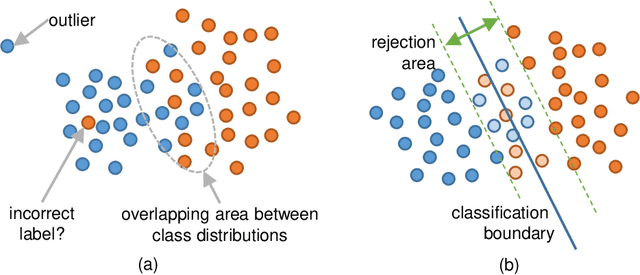
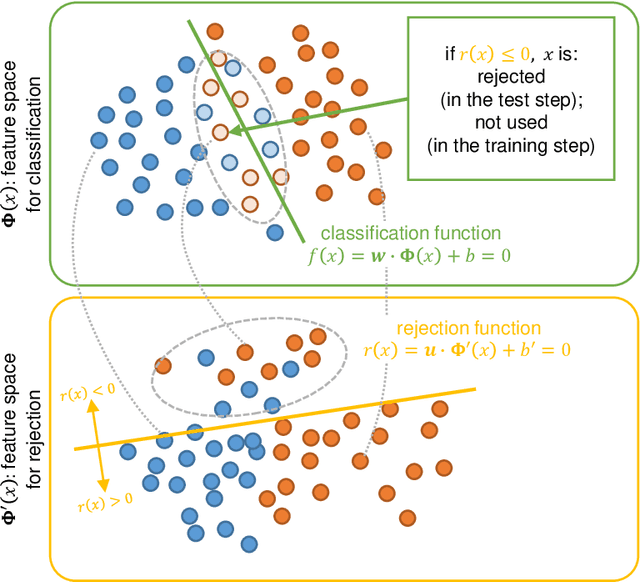
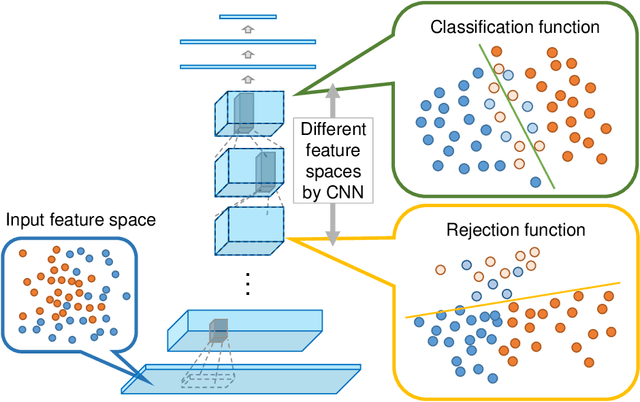

In this paper, we propose an optimal rejection method for rejecting ambiguous samples by a rejection function. This rejection function is trained together with a classification function under the framework of Learning-with-Rejection (LwR). The highlights of LwR are: (1) the rejection strategy is not heuristic but has a strong background from a machine learning theory, and (2) the rejection function can be trained on an arbitrary feature space which is different from the feature space for classification. The latter suggests we can choose a feature space that is more suitable for rejection. Although the past research on LwR focused only on its theoretical aspect, we propose to utilize LwR for practical pattern classification tasks. Moreover, we propose to use features from different CNN layers for classification and rejection. Our extensive experiments of notMNIST classification and character/non-character classification demonstrate that the proposed method achieves better performance than traditional rejection strategies.
Regularized Pooling
May 06, 2020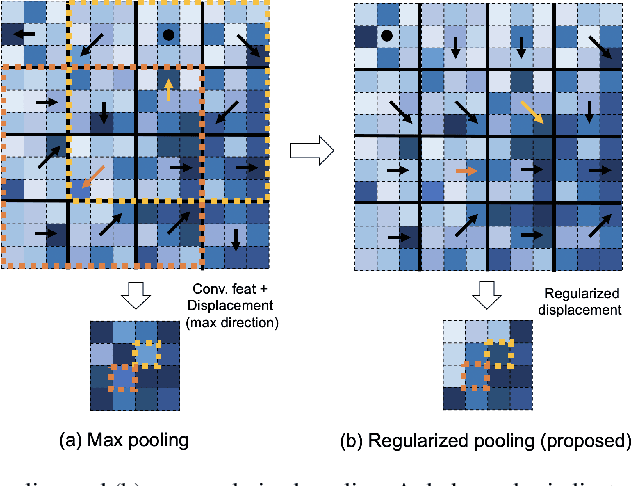

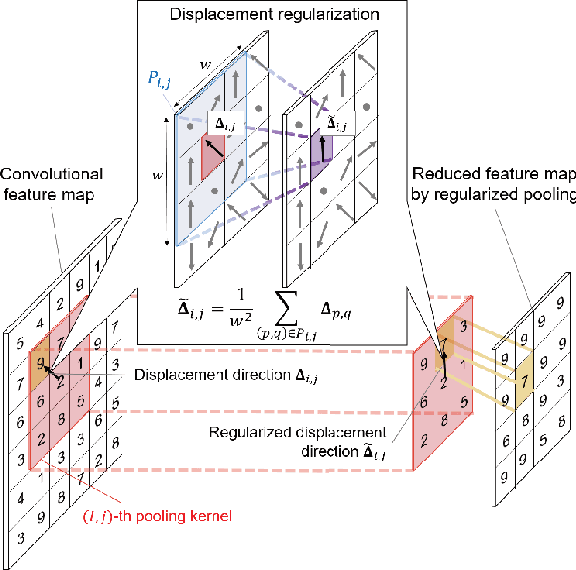
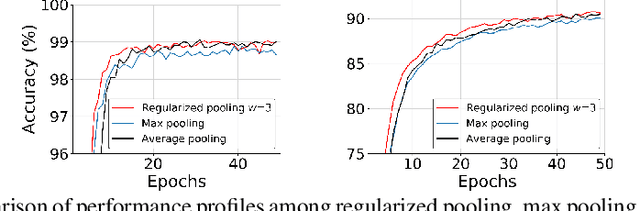
In convolutional neural networks (CNNs), pooling operations play important roles such as dimensionality reduction and deformation compensation. In general, max pooling, which is the most widely used operation for local pooling, is performed independently for each kernel. However, the deformation may be spatially smooth over the neighboring kernels. This means that max pooling is too flexible to compensate for actual deformations. In other words, its excessive flexibility risks canceling the essential spatial differences between classes. In this paper, we propose regularized pooling, which enables the value selection direction in the pooling operation to be spatially smooth across adjacent kernels so as to compensate only for actual deformations. The results of experiments on handwritten character images and texture images showed that regularized pooling not only improves recognition accuracy but also accelerates the convergence of learning compared with conventional pooling operations.