 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Domain Perspective on Degradation-Aware Fusion: A VLM-Guided Robust Infrared and Visible Image Fusion Framework
Sep 05, 2025



Most existing infrared-visible image fusion (IVIF) methods assume high-quality inputs, and therefore struggle to handle dual-source degraded scenarios, typically requiring manual selection and sequential application of multiple pre-enhancement steps. This decoupled pre-enhancement-to-fusion pipeline inevitably leads to error accumulation and performance degradation. To overcome these limitations, we propose Guided Dual-Domain Fusion (GD^2Fusion), a novel framework that synergistically integrates vision-language models (VLMs) for degradation perception with dual-domain (frequency/spatial) joint optimization. Concretely, the designed Guided Frequency Modality-Specific Extraction (GFMSE) module performs frequency-domain degradation perception and suppression and discriminatively extracts fusion-relevant sub-band features. Meanwhile, the Guided Spatial Modality-Aggregated Fusion (GSMAF) module carries out cross-modal degradation filtering and adaptive multi-source feature aggregation in the spatial domain to enhance modality complementarity and structural consistency. Extensive qualitative and quantitative experiments demonstrate that GD^2Fusion achieves superior fusion performance compared with existing algorithms and strategies in dual-source degraded scenarios. The code will be publicly released after acceptance of this paper.
FSATFusion: Frequency-Spatial Attention Transformer for Infrared and Visible Image Fusion
Jun 12, 2025



The infrared and visible images fusion (IVIF) is receiving increasing attention from both the research community and industry due to its excellent results in downstream applications. Existing deep learning approaches often utilize convolutional neural networks to extract image features. However, the inherently capacity of convolution operations to capture global context can lead to information loss, thereby restricting fusion performance. To address this limitation, we propose an end-to-end fusion network named the Frequency-Spatial Attention Transformer Fusion Network (FSATFusion). The FSATFusion contains a frequency-spatial attention Transformer (FSAT) module designed to effectively capture discriminate features from source images. This FSAT module includes a frequency-spatial attention mechanism (FSAM) capable of extracting significant features from feature maps. Additionally, we propose an improved Transformer module (ITM) to enhance the ability to extract global context information of vanilla Transformer. We conducted both qualitative and quantitative comparative experiments, demonstrating the superior fusion quality and efficiency of FSATFusion compared to other state-of-the-art methods. Furthermore, our network was tested on two additional tasks without any modifications, to verify the excellent generalization capability of FSATFusion. Finally, the object detection experiment demonstrated the superiority of FSATFusion in downstream visual tasks. Our code is available at https://github.com/Lmmh058/FSATFusion.
Selective Variable Convolution Meets Dynamic Content Guided Attention for Infrared Small Target Detection
Apr 30, 2025
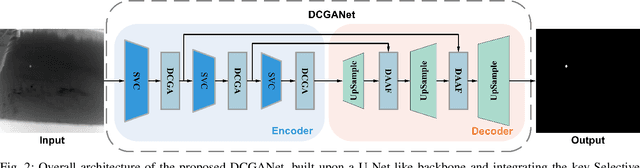
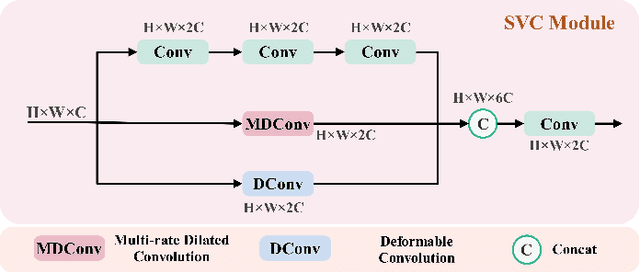
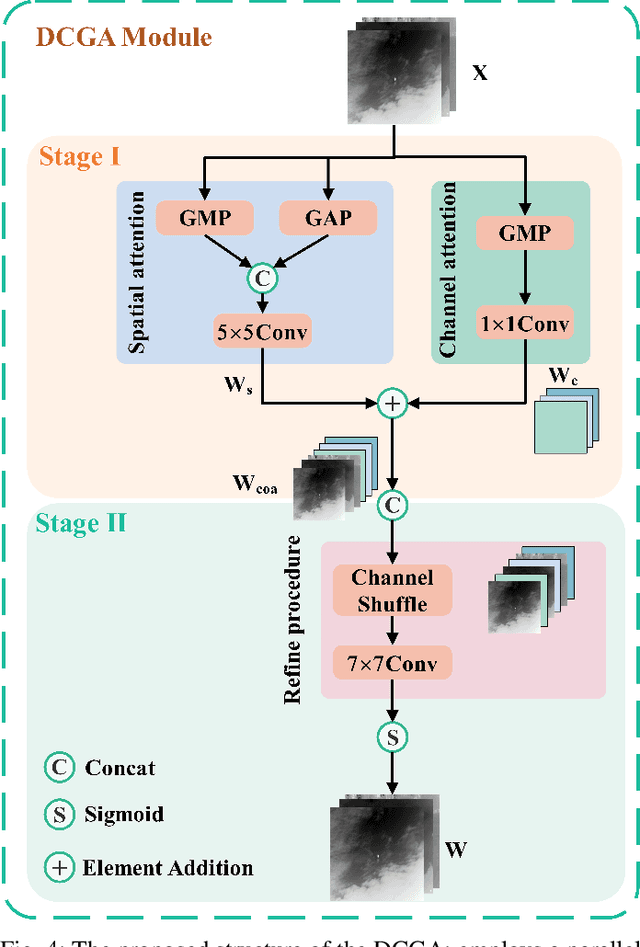
Infrared Small Target Detection (IRSTD) system aims to identify small targets in complex backgrounds. Due to the convolution operation in Convolutional Neural Networks (CNNs), applying traditional CNNs to IRSTD presents challenges, since the feature extraction of small targets is often insufficient, resulting in the loss of critical features. To address these issues, we propose a dynamic content guided attention multiscale feature aggregation network (DCGANet), which adheres to the attention principle of 'coarse-to-fine' and achieves high detection accuracy. First, we propose a selective variable convolution (SVC) module that integrates the benefits of standard convolution, irregular deformable convolution, and multi-rate dilated convolution. This module is designed to expand the receptive field and enhance non-local features, thereby effectively improving the discrimination of targets from backgrounds. Second, the core component of DCGANet is a two-stage content guided attention module. This module employs two-stage attention mechanism to initially direct the network's focus to salient regions within the feature maps and subsequently determine whether these regions correspond to targets or background interference. By retaining the most significant responses, this mechanism effectively suppresses false alarms. Additionally, we propose adaptive dynamic feature fusion (ADFF) module to substitute for static feature cascading. This dynamic feature fusion strategy enables DCGANet to adaptively integrate contextual features, thereby enhancing its ability to discriminate true targets from false alarms. DCGANet has achieved new benchmarks across multiple datasets.
Make Both Ends Meet: A Synergistic Optimization Infrared Small Target Detection with Streamlined Computational Overhead
Apr 30, 2025
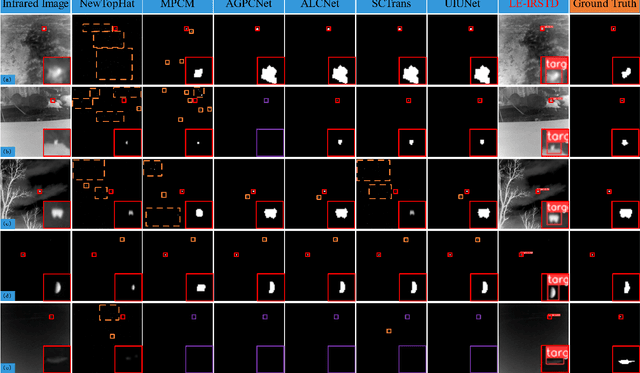
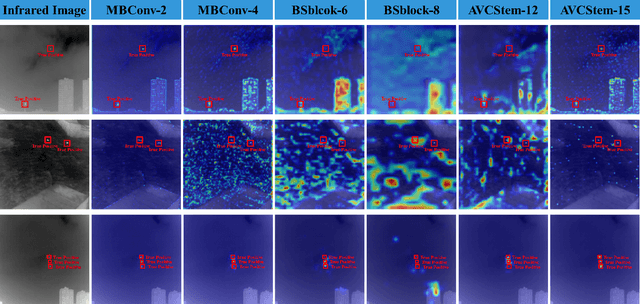
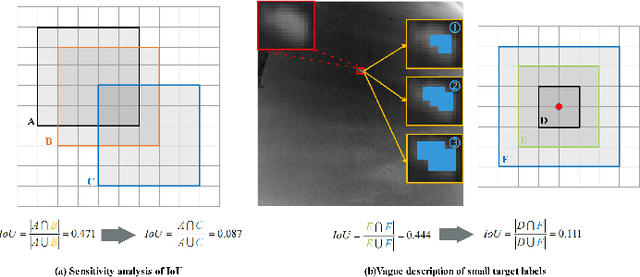
Infrared small target detection(IRSTD) is widely recognized as a challenging task due to the inherent limitations of infrared imaging, including low signal-to-noise ratios, lack of texture details, and complex background interference. While most existing methods model IRSTD as a semantic segmentation task, but they suffer from two critical drawbacks: (1)blurred target boundaries caused by long-distance imaging dispersion; and (2) excessive computational overhead due to indiscriminate feature stackin. To address these issues, we propose the Lightweight Efficiency Infrared Small Target Detection (LE-IRSTD), a lightweight and efficient framework based on YOLOv8n, with following key innovations. Firstly, we identify that the multiple bottleneck structures within the C2f component of the YOLOv8-n backbone contribute to an increased computational burden. Therefore, we implement the Mobile Inverted Bottleneck Convolution block (MBConvblock) and Bottleneck Structure block (BSblock) in the backbone, effectively balancing the trade-off between computational efficiency and the extraction of deep semantic information. Secondly, we introduce the Attention-based Variable Convolution Stem (AVCStem) structure, substituting the final convolution with Variable Kernel Convolution (VKConv), which allows for adaptive convolutional kernels that can transform into various shapes, facilitating the receptive field for the extraction of targets. Finally, we employ Global Shuffle Convolution (GSConv) to shuffle the channel dimension features obtained from different convolutional approaches, thereby enhancing the robustness and generalization capabilities of our method. Experimental results demonstrate that our LE-IRSTD method achieves compelling results in both accuracy and lightweight performance, outperforming several state-of-the-art deep learning methods.
DAAF:Degradation-Aware Adaptive Fusion Framework for Robust Infrared and Visible Images Fusion
Apr 15, 2025



Existing infrared and visible image fusion(IVIF) algorithms often prioritize high-quality images, neglecting image degradation such as low light and noise, which limits the practical potential. This paper propose Degradation-Aware Adaptive image Fusion (DAAF), which achieves unified modeling of adaptive degradation optimization and image fusion. Specifically, DAAF comprises an auxiliary Adaptive Degradation Optimization Network (ADON) and a Feature Interactive Local-Global Fusion (FILGF) Network. Firstly, ADON includes infrared and visible-light branches. Within the infrared branch, frequency-domain feature decomposition and extraction are employed to isolate Gaussian and stripe noise. In the visible-light branch, Retinex decomposition is applied to extract illumination and reflectance components, enabling complementary enhancement of detail and illumination distribution. Subsequently, FILGF performs interactive multi-scale local-global feature fusion. Local feature fusion consists of intra-inter model feature complement, while global feature fusion is achieved through a interactive cross-model attention. Extensive experiments have shown that DAAF outperforms current IVIF algorithms in normal and complex degradation scenarios.