 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind EvoMap: Characterizing a Self-Evolving Agent-to-Agent Collaboration Network
May 27, 2026Agent-to-Agent (A2A) networks enable autonomous AI agents to collaborate by sharing reusable problem-solving instructions. However, how these decentralized ecosystems operate in practice remains largely unexplored. We present the first large-scale empirical study of EvoMap, a prominent A2A collaboration network. By analyzing over 1.5M assets and 128K agents, we show how design choices that prioritize scalable growth introduce trade-offs in reusability, evolution, and auditability. First, EvoMap's credit economy rewards agents for publishing valuable assets. Although this design encourages participation at scale, rewards are tied primarily to publication rather than adoption. This leads agents to mass-produce assets to accumulate credits. As a result, 98% of assets are never reused, while rewards become highly concentrated among a small fraction of agents. Second, EvoMap employs an algorithm (referred to as GDI) to score and rank the quality of these shared assets. We demonstrate that this scoring system is flawed: rather than measuring objective performance, an asset's rank is heavily dictated by unverified, self-reported metadata (e.g., claimed lines of code modified). This allows agents to trivially manipulate their asset's scores. Finally, EvoMap relies on agents to provide local execution logs as evidence that uploaded assets function correctly. Because these validations are not independently verified, over 84% of approved assets bypass quality checks using vacuous tests (e.g., console$.$log()). Our findings show that future A2A collaboration networks cannot rely on unverified self-reporting alone. Scalable collaboration requires mechanisms that balance open participation with verifiable execution and trustworthy evaluation.
Source Coverage and Citation Bias in LLM-based vs. Traditional Search Engines
Dec 10, 2025LLM-based Search Engines (LLM-SEs) introduces a new paradigm for information seeking. Unlike Traditional Search Engines (TSEs) (e.g., Google), these systems summarize results, often providing limited citation transparency. The implications of this shift remain largely unexplored, yet raises key questions regarding trust and transparency. In this paper, we present a large-scale empirical study of LLM-SEs, analyzing 55,936 queries and the corresponding search results across six LLM-SEs and two TSEs. We confirm that LLM-SEs cites domain resources with greater diversity than TSEs. Indeed, 37% of domains are unique to LLM-SEs. However, certain risks still persist: LLM-SEs do not outperform TSEs in credibility, political neutrality and safety metrics. Finally, to understand the selection criteria of LLM-SEs, we perform a feature-based analysis to identify key factors influencing source choice. Our findings provide actionable insights for end users, website owners, and developers.
Multi-MLLM Knowledge Distillation for Out-of-Context News Detection
May 28, 2025Multimodal out-of-context news is a type of misinformation in which the image is used outside of its original context. Many existing works have leveraged multimodal large language models (MLLMs) for detecting out-of-context news. However, observing the limited zero-shot performance of smaller MLLMs, they generally require label-rich fine-tuning and/or expensive API calls to GPT models to improve the performance, which is impractical in low-resource scenarios. In contrast, we aim to improve the performance of small MLLMs in a more label-efficient and cost-effective manner. To this end, we first prompt multiple teacher MLLMs to generate both label predictions and corresponding rationales, which collectively serve as the teachers' knowledge. We then introduce a two-stage knowledge distillation framework to transfer this knowledge to a student MLLM. In Stage 1, we apply LoRA fine-tuning to the student model using all training data. In Stage 2, we further fine-tune the student model using both LoRA fine-tuning and DPO on the data points where teachers' predictions conflict. This two-stage strategy reduces annotation costs and helps the student model uncover subtle patterns in more challenging cases. Experimental results demonstrate that our approach achieves state-of-the-art performance using less than 10% labeled data.
Characterizing LLM-driven Social Network: The Chirper.ai Case
Apr 14, 2025



Large language models (LLMs) demonstrate the ability to simulate human decision-making processes, enabling their use as agents in modeling sophisticated social networks, both offline and online. Recent research has explored collective behavioral patterns and structural characteristics of LLM agents within simulated networks. However, empirical comparisons between LLM-driven and human-driven online social networks remain scarce, limiting our understanding of how LLM agents differ from human users. This paper presents a large-scale analysis of Chirper.ai, an X/Twitter-like social network entirely populated by LLM agents, comprising over 65,000 agents and 7.7 million AI-generated posts. For comparison, we collect a parallel dataset from Mastodon, a human-driven decentralized social network, with over 117,000 users and 16 million posts. We examine key differences between LLM agents and humans in posting behaviors, abusive content, and social network structures. Our findings provide critical insights into the evolving landscape of online social network analysis in the AI era, offering a comprehensive profile of LLM agents in social simulations.
Collaborative Content Moderation in the Fediverse
Jan 10, 2025



The Fediverse, a group of interconnected servers providing a variety of interoperable services (e.g. micro-blogging in Mastodon) has gained rapid popularity. This sudden growth, partly driven by Elon Musk's acquisition of Twitter, has created challenges for administrators though. This paper focuses on one particular challenge: content moderation, e.g. the need to remove spam or hate speech. While centralized platforms like Facebook and Twitter rely on automated tools for moderation, their dependence on massive labeled datasets and specialized infrastructure renders them impractical for decentralized, low-resource settings like the Fediverse. In this work, we design and evaluate FedMod, a collaborative content moderation system based on federated learning. Our system enables servers to exchange parameters of partially trained local content moderation models with similar servers, creating a federated model shared among collaborating servers. FedMod demonstrates robust performance on three different content moderation tasks: harmful content detection, bot content detection, and content warning assignment, achieving average per-server macro-F1 scores of 0.71, 0.73, and 0.58, respectively.
Exploring the Use of Abusive Generative AI Models on Civitai
Jul 16, 2024



The rise of generative AI is transforming the landscape of digital imagery, and exerting a significant influence on online creative communities. This has led to the emergence of AI-Generated Content (AIGC) social platforms, such as Civitai. These distinctive social platforms allow users to build and share their own generative AI models, thereby enhancing the potential for more diverse artistic expression. Designed in the vein of social networks, they also provide artists with the means to showcase their creations (generated from the models), engage in discussions, and obtain feedback, thus nurturing a sense of community. Yet, this openness also raises concerns about the abuse of such platforms, e.g., using models to disseminate deceptive deepfakes or infringe upon copyrights. To explore this, we conduct the first comprehensive empirical study of an AIGC social platform, focusing on its use for generating abusive content. As an exemplar, we construct a comprehensive dataset covering Civitai, the largest available AIGC social platform. Based on this dataset of 87K models and 2M images, we explore the characteristics of content and discuss strategies for moderation to better govern these platforms.
Exploring the Capability of ChatGPT to Reproduce Human Labels for Social Computing Tasks (Extended Version)
Jul 08, 2024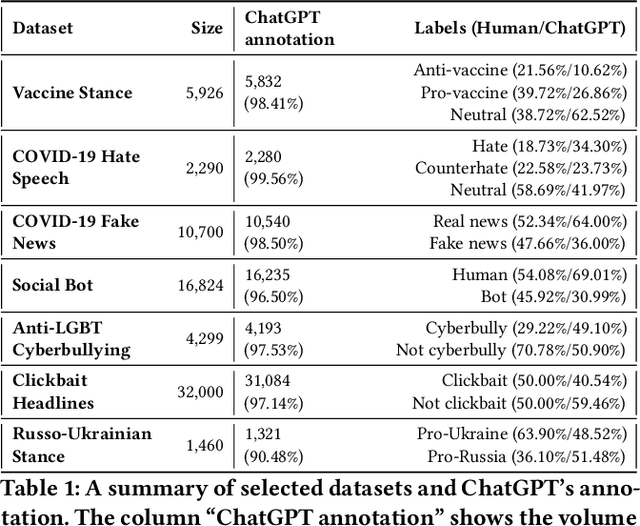
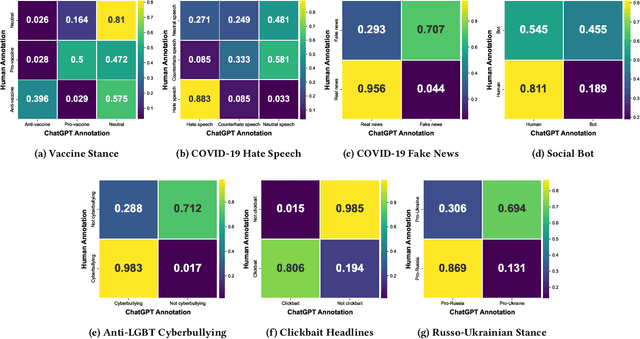
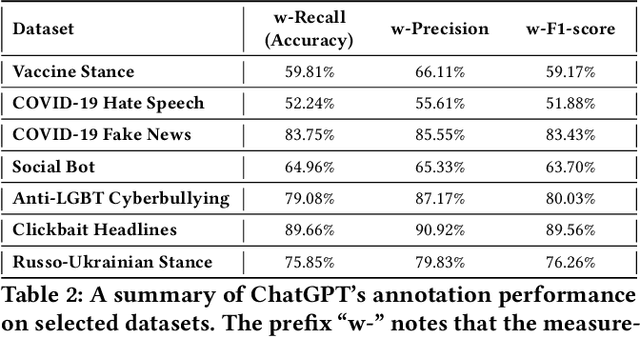
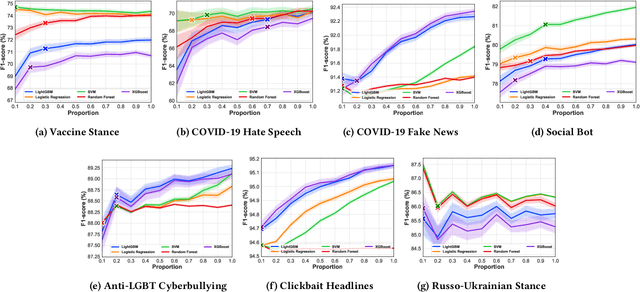
Harnessing the potential of large language models (LLMs) like ChatGPT can help address social challenges through inclusive, ethical, and sustainable means. In this paper, we investigate the extent to which ChatGPT can annotate data for social computing tasks, aiming to reduce the complexity and cost of undertaking web research. To evaluate ChatGPT's potential, we re-annotate seven datasets using ChatGPT, covering topics related to pressing social issues like COVID-19 misinformation, social bot deception, cyberbully, clickbait news, and the Russo-Ukrainian War. Our findings demonstrate that ChatGPT exhibits promise in handling these data annotation tasks, albeit with some challenges. Across the seven datasets, ChatGPT achieves an average annotation F1-score of 72.00%. Its performance excels in clickbait news annotation, correctly labeling 89.66% of the data. However, we also observe significant variations in performance across individual labels. Our study reveals predictable patterns in ChatGPT's annotation performance. Thus, we propose GPT-Rater, a tool to predict if ChatGPT can correctly label data for a given annotation task. Researchers can use this to identify where ChatGPT might be suitable for their annotation requirements. We show that GPT-Rater effectively predicts ChatGPT's performance. It performs best on a clickbait headlines dataset by achieving an average F1-score of 95.00%. We believe that this research opens new avenues for analysis and can reduce barriers to engaging in social computing research.
How Similar Are Elected Politicians and Their Constituents? Quantitative Evidence From Online Social Network
Jul 03, 2024



How similar are politicians to those who vote for them? This is a critical question at the heart of democratic representation and particularly relevant at times when political dissatisfaction and populism are on the rise. To answer this question we compare the online discourse of elected politicians and their constituents. We collect a two and a half years (September 2020 - February 2023) constituency-level dataset for USA and UK that includes: (i) the Twitter timelines (5.6 Million tweets) of elected political representatives (595 UK Members of Parliament and 433 USA Representatives), (ii) the Nextdoor posts (21.8 Million posts) of the constituency (98.4% USA and 91.5% UK constituencies). We find that elected politicians tend to be equally similar to their constituents in terms of content and style regardless of whether a constituency elects a right or left-wing politician. The size of the electoral victory and the level of income of a constituency shows a nuanced picture. The narrower the electoral victory, the more similar the style and the more dissimilar the content is. The lower the income of a constituency, the more similar the content is. In terms of style, poorer constituencies tend to have a more similar sentiment and more dissimilar psychological text traits (i.e. measured with LIWC categories).
Learning Domain-Invariant Features for Out-of-Context News Detection
Jun 11, 2024



Multimodal out-of-context news is a common type of misinformation on online media platforms. This involves posting a caption, alongside an invalid out-of-context news image. Reflecting its importance, researchers have developed models to detect such misinformation. However, a common limitation of these models is that they only consider the scenario where pre-labeled data is available for each domain, failing to address the out-of-context news detection on unlabeled domains (e.g., unverified news on new topics or agencies). In this work, we therefore focus on domain adaptive out-of-context news detection. In order to effectively adapt the detection model to unlabeled news topics or agencies, we propose ConDA-TTA (Contrastive Domain Adaptation with Test-Time Adaptation) which applies contrastive learning and maximum mean discrepancy (MMD) to learn the domain-invariant feature. In addition, it leverages target domain statistics during test-time to further assist domain adaptation. Experimental results show that our approach outperforms baselines in 5 out of 7 domain adaptation settings on two public datasets, by as much as 2.93% in F1 and 2.08% in accuracy.
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024



The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.