 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamPPG: Low-Latency rPPG Estimation via Consistent Privileged Learning
Jun 22, 2026Remote photoplethysmography (rPPG) estimates the blood volume pulse (BVP) signal from facial videos, enabling contact-free health monitoring. Conventional clip-wise approaches, which use video clips as input, require capturing over one hundred frames before inference, thus introducing several seconds of delay and hindering real-time use. Meanwhile, frame-wise approaches struggle to capture long-range temporal and periodic features of physiological rhythms, and therefore lead to reduced estimation accuracy. To overcome these issues, we propose StreamPPG, a unified architecture that enables low-latency frame-wise physiological signal estimation while achieving competitive accuracy compared with clip-wise approaches. StreamPPG is trained under a consistent privileged learning (CPL) strategy, which leverages ground-truth rPPG signals as privileged information to enhance the model's representation capability. Extensive experiments demonstrate that StreamPPG achieves state-of-the-art accuracy across multiple datasets while maintaining real-time throughput on edge devices.
AnyPoC: Universal Proof-of-Concept Test Generation for Scalable LLM-Based Bug Detection
Apr 13, 2026While recent LLM-based agents can identify many candidate bugs in source code, their reports remain static hypotheses that require manual validation, limiting the practicality of automated bug detection. We frame this challenge as a test generation task: given a candidate report, synthesizing an executable proof-of-concept test, or simply a PoC - such as a script, command sequence, or crafted input - to trigger the suspected defect. Automated PoC generation can act as a scalable validation oracle, enabling end-to-end autonomous bug detection by providing concrete execution evidence. However, naive LLM agents are unreliable validators: they are biased toward "success" and may reward-hack by producing plausible but non-functional PoCs or even hallucinated traces. To address this, we present AnyPoC, a general multi-agent framework that (1) analyzes and fact-checks a candidate bug report, (2) iteratively synthesizes and executes a PoC while collecting execution traces, and (3) independently re-executes and scrutinizes the PoC to mitigate hallucination and reward hacking. In addition, AnyPoC also continuously extracts and evolves a PoC knowledge base to handle heterogeneous tasks. AnyPoC operates on candidate bug reports regardless of their source and can be paired with different bug reporters. To demonstrate practicality and generality, we apply AnyPoC, with a simple agentic bug reporter, on 12 critical software systems across diverse languages/domains (many with millions of lines of code) including Firefox, Chromium, LLVM, OpenSSL, SQLite, FFmpeg, and Redis. Compared to the state-of-the-art coding agents, e.g., Claude Code and Codex, AnyPoC produces 1.3x more valid PoCs for true-positive bug reports and rejects 9.8x more false-positive bug reports. To date, AnyPoC has discovered 122 new bugs (105 confirmed, 86 already fixed), with 45 generated PoCs adopted as official regression tests.
Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
Apr 11, 2024



High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
Multi-Head Online Learning for Delayed Feedback Modeling
May 24, 2022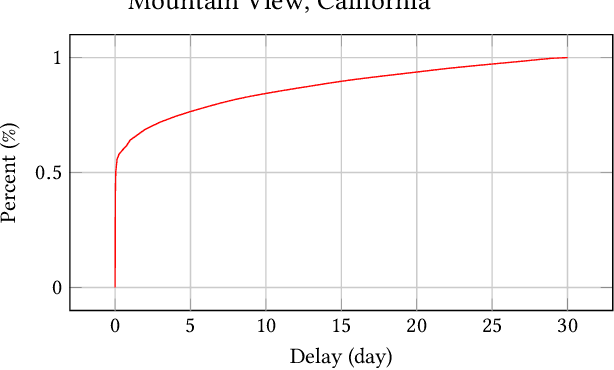
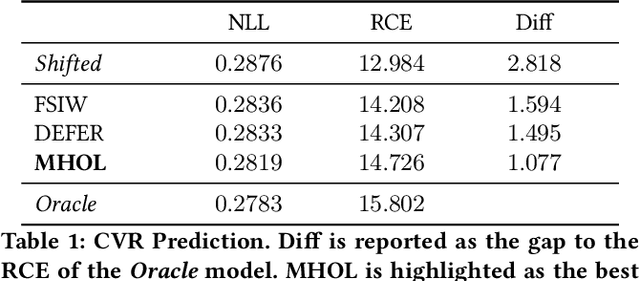
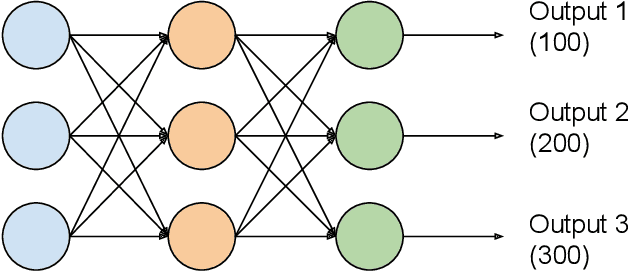
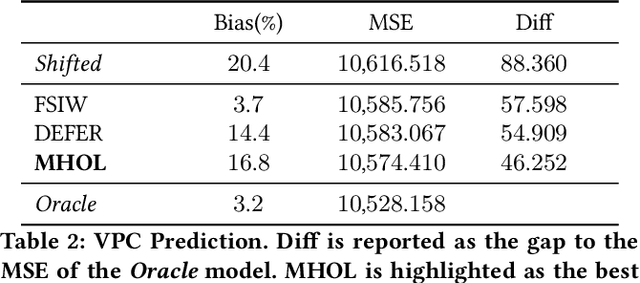
In online advertising, it is highly important to predict the probability and the value of a conversion (e.g., a purchase). It not only impacts user experience by showing relevant ads, but also affects ROI of advertisers and revenue of marketplaces. Unlike clicks, which often occur within minutes after impressions, conversions are expected to happen over a long period of time (e.g., 30 days for online shopping). It creates a challenge, as the true labels are only available after the long delays. Either inaccurate labels (partial conversions) are used, or models are trained on stale data (e.g., from 30 days ago). The problem is more eminent in online learning, which focuses on the live performance on the latest data. In this paper, a novel solution is presented to address this challenge using multi-head modeling. Unlike traditional methods, it directly quantizes conversions into multiple windows, such as day 1, day 2, day 3-7, and day 8-30. A sub-model is trained specifically on conversions within each window. Label freshness is maximally preserved in early models (e.g., day 1 and day 2), while late conversions are accurately utilized in models with longer delays (e.g., day 8-30). It is shown to greatly exceed the performance of known methods in online learning experiments for both conversion rate (CVR) and value per click (VPC) predictions. Lastly, as a general method for delayed feedback modeling, it can be combined with any advanced ML techniques to further improve the performance.