 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Speaker Verification
Apr 29, 2019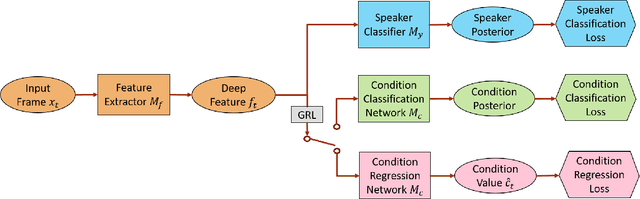
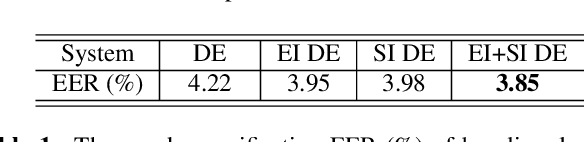
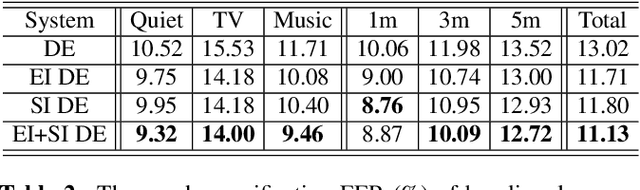
The use of deep networks to extract embeddings for speaker recognition has proven successfully. However, such embeddings are susceptible to performance degradation due to the mismatches among the training, enrollment, and test conditions. In this work, we propose an adversarial speaker verification (ASV) scheme to learn the condition-invariant deep embedding via adversarial multi-task training. In ASV, a speaker classification network and a condition identification network are jointly optimized to minimize the speaker classification loss and simultaneously mini-maximize the condition loss. The target labels of the condition network can be categorical (environment types) and continuous (SNR values). We further propose multi-factorial ASV to simultaneously suppress multiple factors that constitute the condition variability. Evaluated on a Microsoft Cortana text-dependent speaker verification task, the ASV achieves 8.8% and 14.5% relative improvements in equal error rates (EER) for known and unknown conditions, respectively.
* 5 pages, 1 figure, ICASSP 2019
Attentive Adversarial Learning for Domain-Invariant Training
Apr 28, 2019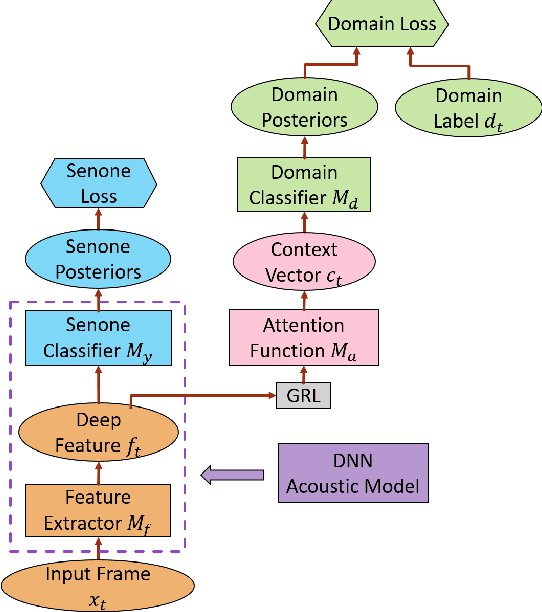

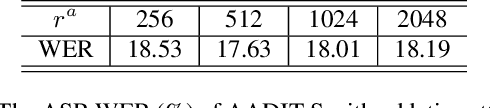
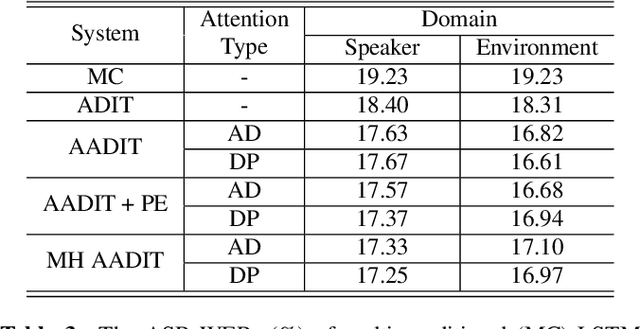
Adversarial domain-invariant training (ADIT) proves to be effective in suppressing the effects of domain variability in acoustic modeling and has led to improved performance in automatic speech recognition (ASR). In ADIT, an auxiliary domain classifier takes in equally-weighted deep features from a deep neural network (DNN) acoustic model and is trained to improve their domain-invariance by optimizing an adversarial loss function. In this work, we propose an attentive ADIT (AADIT) in which we advance the domain classifier with an attention mechanism to automatically weight the input deep features according to their importance in domain classification. With this attentive re-weighting, AADIT can focus on the domain normalization of phonetic components that are more susceptible to domain variability and generates deep features with improved domain-invariance and senone-discriminativity over ADIT. Most importantly, the attention block serves only as an external component to the DNN acoustic model and is not involved in ASR, so AADIT can be used to improve the acoustic modeling with any DNN architectures. More generally, the same methodology can improve any adversarial learning system with an auxiliary discriminator. Evaluated on CHiME-3 dataset, the AADIT achieves 13.6% and 9.3% relative WER improvements, respectively, over a multi-conditional model and a strong ADIT baseline.
* 5 pages, 1 figure, ICASSP 2019
Conditional Teacher-Student Learning
Apr 28, 2019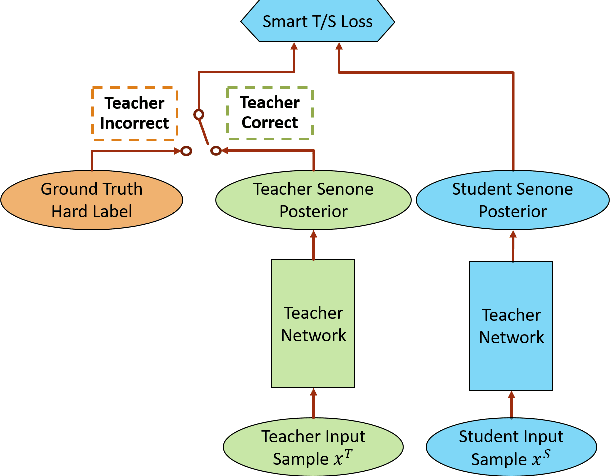
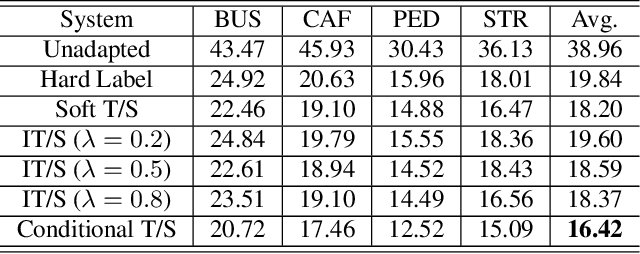
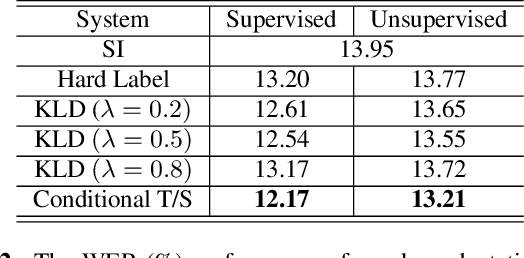
The teacher-student (T/S) learning has been shown to be effective for a variety of problems such as domain adaptation and model compression. One shortcoming of the T/S learning is that a teacher model, not always perfect, sporadically produces wrong guidance in form of posterior probabilities that misleads the student model towards a suboptimal performance. To overcome this problem, we propose a conditional T/S learning scheme, in which a "smart" student model selectively chooses to learn from either the teacher model or the ground truth labels conditioned on whether the teacher can correctly predict the ground truth. Unlike a naive linear combination of the two knowledge sources, the conditional learning is exclusively engaged with the teacher model when the teacher model's prediction is correct, and otherwise backs off to the ground truth. Thus, the student model is able to learn effectively from the teacher and even potentially surpass the teacher. We examine the proposed learning scheme on two tasks: domain adaptation on CHiME-3 dataset and speaker adaptation on Microsoft short message dictation dataset. The proposed method achieves 9.8% and 12.8% relative word error rate reductions, respectively, over T/S learning for environment adaptation and speaker-independent model for speaker adaptation.
* 5 pages, 1 figure, ICASSP 2019
Speaker Adaptation for End-to-End CTC Models
Jan 04, 2019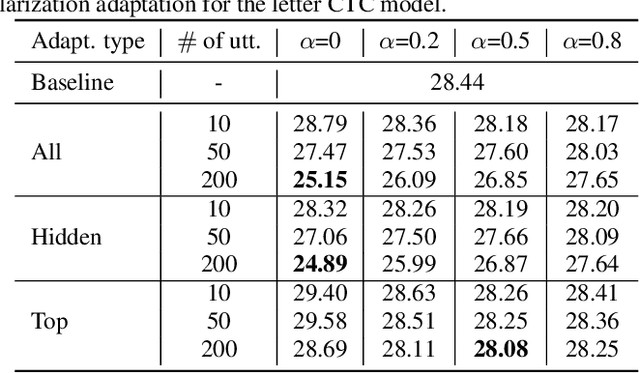
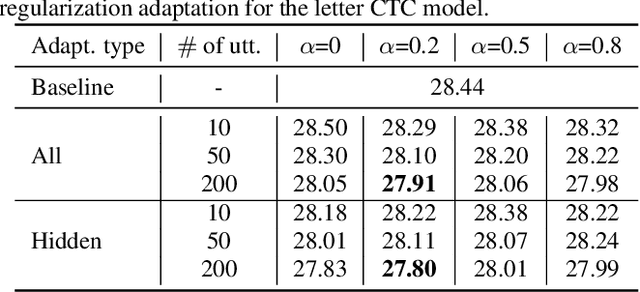
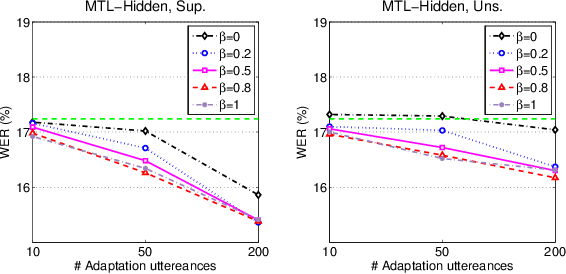
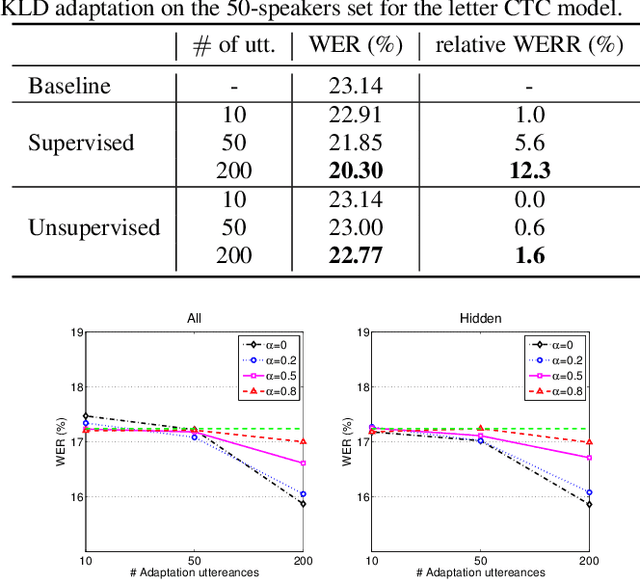
We propose two approaches for speaker adaptation in end-to-end (E2E) automatic speech recognition systems. One is Kullback-Leibler divergence (KLD) regularization and the other is multi-task learning (MTL). Both approaches aim to address the data sparsity especially output target sparsity issue of speaker adaptation in E2E systems. The KLD regularization adapts a model by forcing the output distribution from the adapted model to be close to the unadapted one. The MTL utilizes a jointly trained auxiliary task to improve the performance of the main task. We investigated our approaches on E2E connectionist temporal classification (CTC) models with three different types of output units. Experiments on the Microsoft short message dictation task demonstrated that MTL outperforms KLD regularization. In particular, the MTL adaptation obtained 8.8\% and 4.0\% relative word error rate reductions (WERRs) for supervised and unsupervised adaptations for the word CTC model, and 9.6% and 3.8% relative WERRs for the mix-unit CTC model, respectively.
Advancing Acoustic-to-Word CTC Model with Attention and Mixed-Units
Dec 31, 2018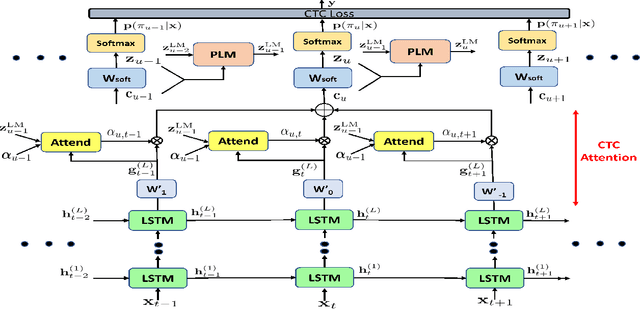
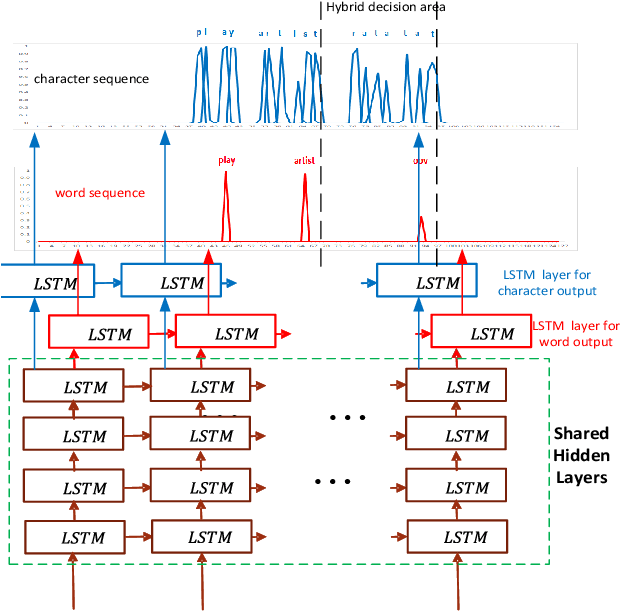
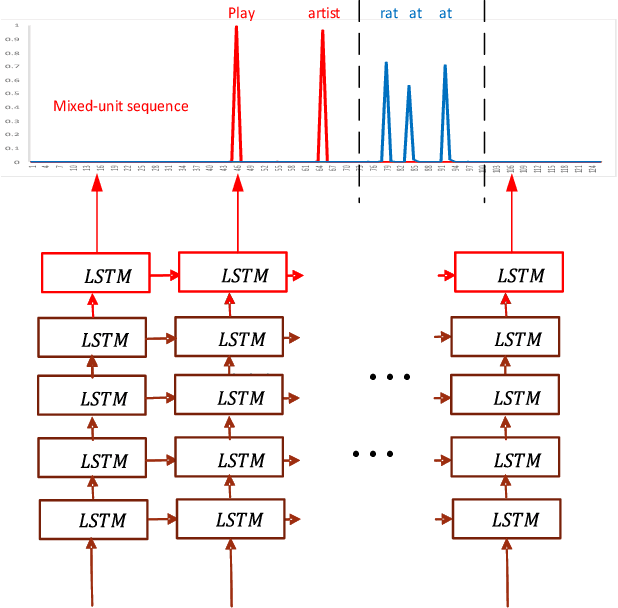

The acoustic-to-word model based on the Connectionist Temporal Classification (CTC) criterion is a natural end-to-end (E2E) system directly targeting word as output unit. Two issues exist in the system: first, the current output of the CTC model relies on the current input and does not account for context weighted inputs. This is the hard alignment issue. Second, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue. This means it can model only the frequently occurring words while tagging the remaining words as OOV. Hence, such a model is limited in its capacity in recognizing only a fixed set of frequent words. In this study, we propose addressing these problems using a combination of attention mechanism and mixed-units. In particular, we introduce Attention CTC, Self-Attention CTC, Hybrid CTC, and Mixed-unit CTC. First, we blend attention modeling capabilities directly into the CTC network using Attention CTC and Self-Attention CTC. Second, to alleviate the OOV issue, we present Hybrid CTC which uses a word and letter CTC with shared hidden layers. The Hybrid CTC consults the letter CTC when the word CTC emits an OOV. Then, we propose a much better solution by training a Mixed-unit CTC which decomposes all the OOV words into sequences of frequent words and multi-letter units. Evaluated on a 3400 hours Microsoft Cortana voice assistant task, our final acoustic-to-word solution using attention and mixed-units achieves a relative reduction in word error rate (WER) over the vanilla word CTC by 12.09%. Such an E2E model without using any language model (LM) or complex decoder also outperforms a traditional context-dependent (CD) phoneme CTC with strong LM and decoder by 6.79% relative.
Speaker-Invariant Training via Adversarial Learning
Oct 16, 2018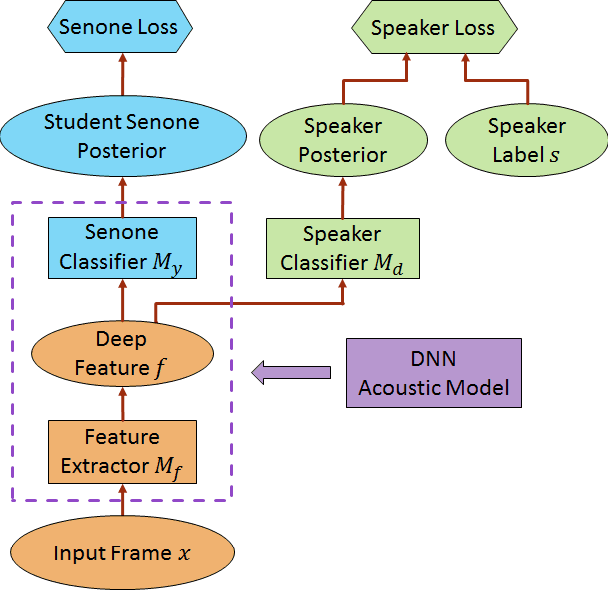
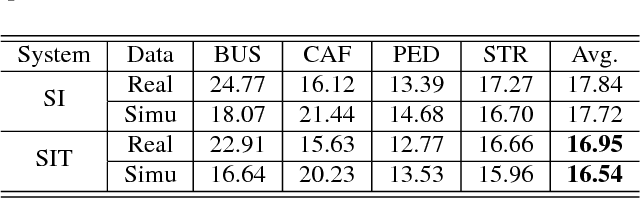
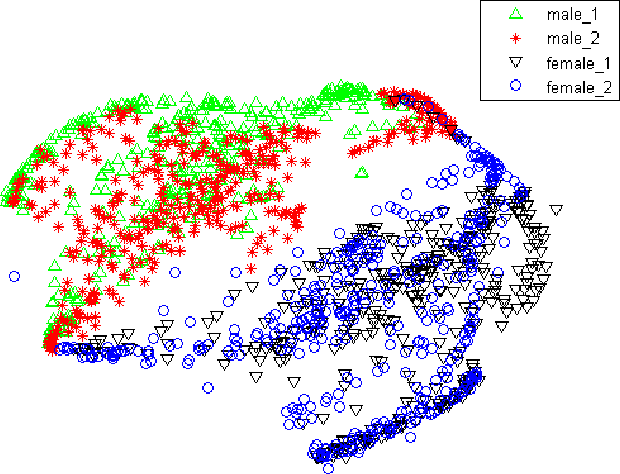
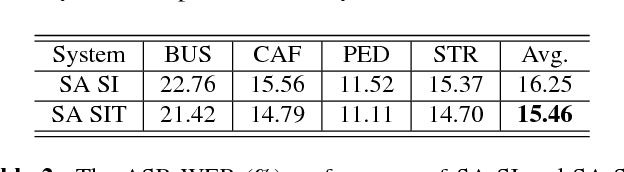
We propose a novel adversarial multi-task learning scheme, aiming at actively curtailing the inter-talker feature variability while maximizing its senone discriminability so as to enhance the performance of a deep neural network (DNN) based ASR system. We call the scheme speaker-invariant training (SIT). In SIT, a DNN acoustic model and a speaker classifier network are jointly optimized to minimize the senone (tied triphone state) classification loss, and simultaneously mini-maximize the speaker classification loss. A speaker-invariant and senone-discriminative deep feature is learned through this adversarial multi-task learning. With SIT, a canonical DNN acoustic model with significantly reduced variance in its output probabilities is learned with no explicit speaker-independent (SI) transformations or speaker-specific representations used in training or testing. Evaluated on the CHiME-3 dataset, the SIT achieves 4.99% relative word error rate (WER) improvement over the conventional SI acoustic model. With additional unsupervised speaker adaptation, the speaker-adapted (SA) SIT model achieves 4.86% relative WER gain over the SA SI acoustic model.
* 5 pages, 3 figures, 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Cycle-Consistent Speech Enhancement
Sep 06, 2018


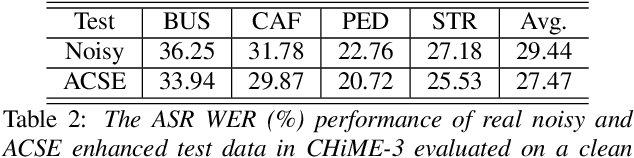
Feature mapping using deep neural networks is an effective approach for single-channel speech enhancement. Noisy features are transformed to the enhanced ones through a mapping network and the mean square errors between the enhanced and clean features are minimized. In this paper, we propose a cycle-consistent speech enhancement (CSE) in which an additional inverse mapping network is introduced to reconstruct the noisy features from the enhanced ones. A cycle-consistent constraint is enforced to minimize the reconstruction loss. Similarly, a backward cycle of mappings is performed in the opposite direction with the same networks and losses. With cycle-consistency, the speech structure is well preserved in the enhanced features while noise is effectively reduced such that the feature-mapping network generalizes better to unseen data. In cases where only unparalleled noisy and clean data is available for training, two discriminator networks are used to distinguish the enhanced and noised features from the clean and noisy ones. The discrimination losses are jointly optimized with reconstruction losses through adversarial multi-task learning. Evaluated on the CHiME-3 dataset, the proposed CSE achieves 19.60% and 6.69% relative word error rate improvements respectively when using or without using parallel clean and noisy speech data.
* 5 pages, 2 figures. arXiv admin note: text overlap with arXiv:1809.02251
Adversarial Feature-Mapping for Speech Enhancement
Sep 06, 2018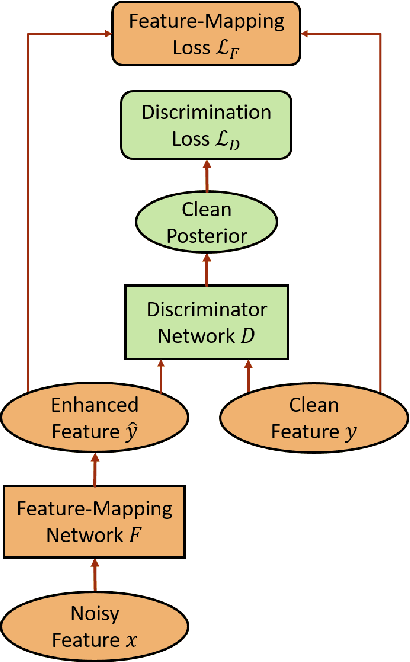
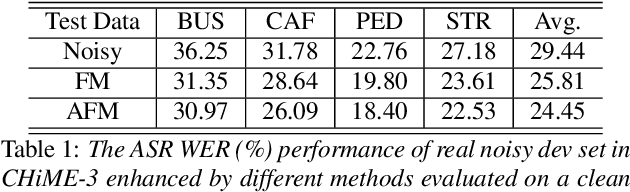
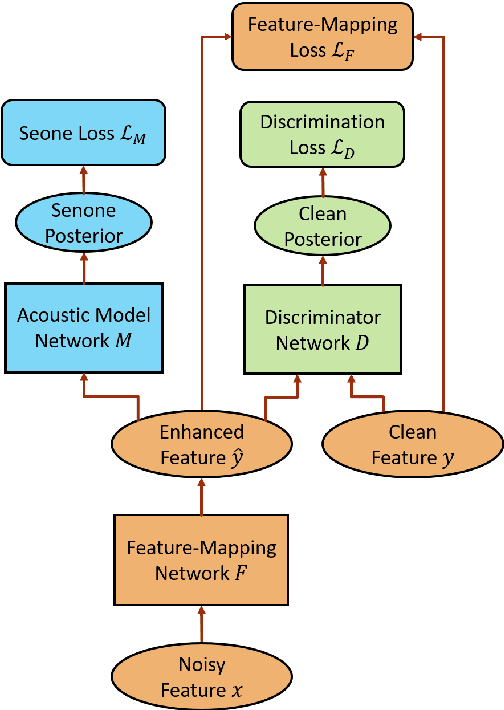
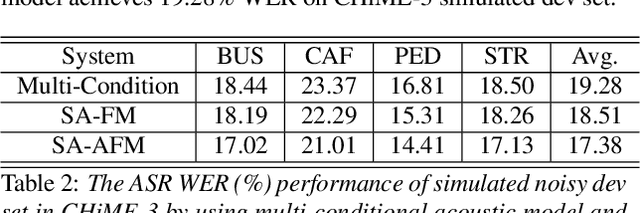
Feature-mapping with deep neural networks is commonly used for single-channel speech enhancement, in which a feature-mapping network directly transforms the noisy features to the corresponding enhanced ones and is trained to minimize the mean square errors between the enhanced and clean features. In this paper, we propose an adversarial feature-mapping (AFM) method for speech enhancement which advances the feature-mapping approach with adversarial learning. An additional discriminator network is introduced to distinguish the enhanced features from the real clean ones. The two networks are jointly optimized to minimize the feature-mapping loss and simultaneously mini-maximize the discrimination loss. The distribution of the enhanced features is further pushed towards that of the clean features through this adversarial multi-task training. To achieve better performance on ASR task, senone-aware (SA) AFM is further proposed in which an acoustic model network is jointly trained with the feature-mapping and discriminator networks to optimize the senone classification loss in addition to the AFM losses. Evaluated on the CHiME-3 dataset, the proposed AFM achieves 16.95% and 5.27% relative word error rate (WER) improvements over the real noisy data and the feature-mapping baseline respectively and the SA-AFM achieves 9.85% relative WER improvement over the multi-conditional acoustic model.
* 5 pages, 2 figures
Layer Trajectory LSTM
Aug 28, 2018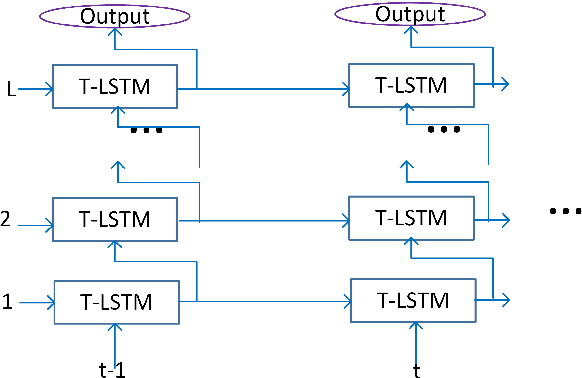
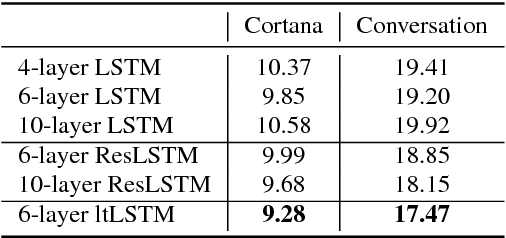
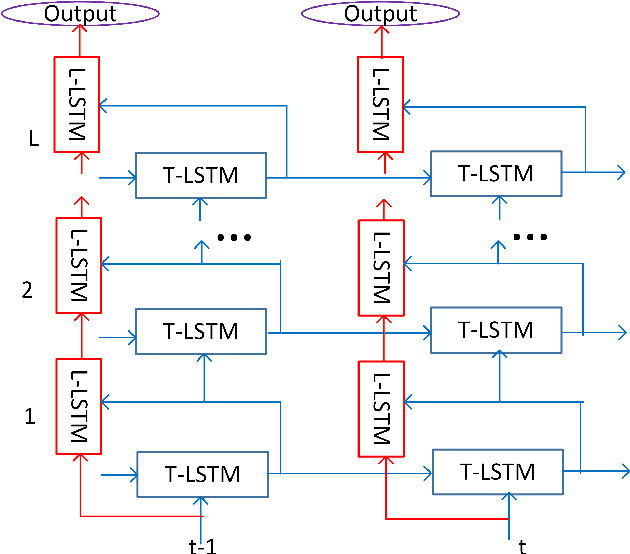
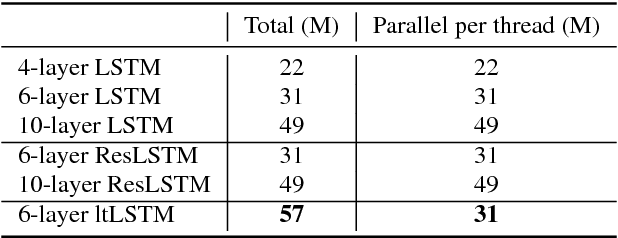
It is popular to stack LSTM layers to get better modeling power, especially when large amount of training data is available. However, an LSTM-RNN with too many vanilla LSTM layers is very hard to train and there still exists the gradient vanishing issue if the network goes too deep. This issue can be partially solved by adding skip connections between layers, such as residual LSTM. In this paper, we propose a layer trajectory LSTM (ltLSTM) which builds a layer-LSTM using all the layer outputs from a standard multi-layer time-LSTM. This layer-LSTM scans the outputs from time-LSTMs, and uses the summarized layer trajectory information for final senone classification. The forward-propagation of time-LSTM and layer-LSTM can be handled in two separate threads in parallel so that the network computation time is the same as the standard time-LSTM. With a layer-LSTM running through layers, a gated path is provided from the output layer to the bottom layer, alleviating the gradient vanishing issue. Trained with 30 thousand hours of EN-US Microsoft internal data, the proposed ltLSTM performed significantly better than the standard multi-layer LSTM and residual LSTM, with up to 9.0% relative word error rate reduction across different tasks.
Developing Far-Field Speaker System Via Teacher-Student Learning
Apr 14, 2018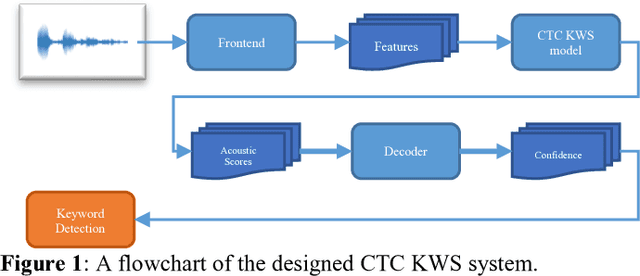
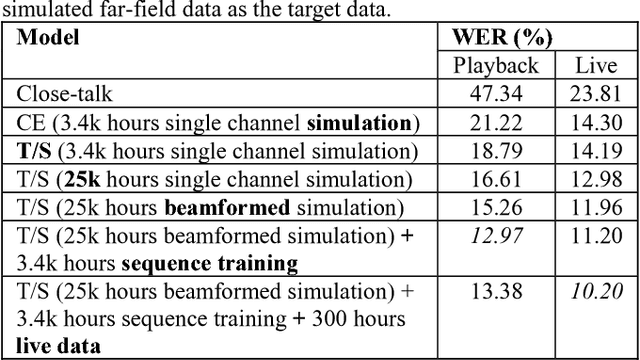
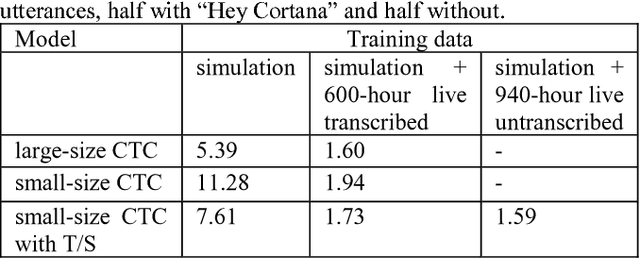
In this study, we develop the keyword spotting (KWS) and acoustic model (AM) components in a far-field speaker system. Specifically, we use teacher-student (T/S) learning to adapt a close-talk well-trained production AM to far-field by using parallel close-talk and simulated far-field data. We also use T/S learning to compress a large-size KWS model into a small-size one to fit the device computational cost. Without the need of transcription, T/S learning well utilizes untranscribed data to boost the model performance in both the AM adaptation and KWS model compression. We further optimize the models with sequence discriminative training and live data to reach the best performance of systems. The adapted AM improved from the baseline by 72.60% and 57.16% relative word error rate reduction on play-back and live test data, respectively. The final KWS model size was reduced by 27 times from a large-size KWS model without losing accuracy.