 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexHiL: A Human-in-the-Loop Framework for Vision-Language-Action Model Post-Training in Dexterous Manipulation
Mar 10, 2026While Vision-Language-Action (VLA) models have demonstrated promising generalization capabilities in robotic manipulation, deploying them on specific and complex downstream tasks still demands effective post-training. In parallel, Human-in-the-Loop (HiL) learning has proven to be a powerful mechanism for refining robot policies. However, extending this paradigm to dexterous manipulation remains challenging: multi-finger control is high-dimensional, contact-intensive, and exhibits execution distributions that differ markedly from standard arm motions, leaving existing dexterous VLA systems limited in reliability and adaptability. We present DexHiL, the first integrated arm-hand human-in-the-loop framework for dexterous VLA models, enabling coordinated interventions over the arm and the dexterous hand within a single system. DexHiL introduces an intervention-aware data sampling strategy that prioritizes corrective segments for post-training, alongside a lightweight teleoperation interface that supports instantaneous human corrections during execution. Real-robot experiments demonstrate that DexHiL serves as an effective post-training framework, yielding a substantial performance leap, outperforming standard offline-only fine-tuning baselines by an average of 25% in success rates across distinct tasks. Project page: https://chenzhongxi-sjtu.github.io/dexhil/
Every SAM Drop Counts: Embracing Semantic Priors for Multi-Modality Image Fusion and Beyond
Mar 03, 2025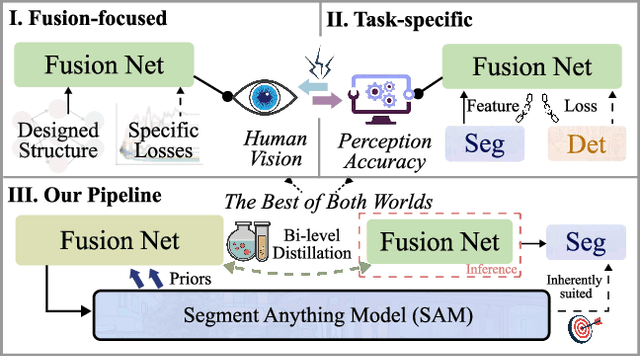
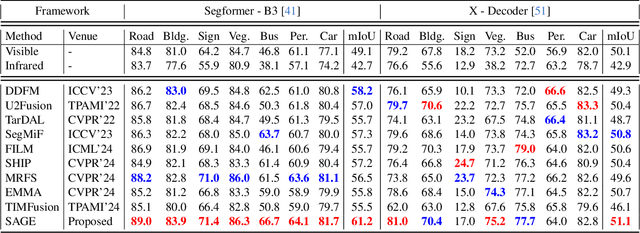

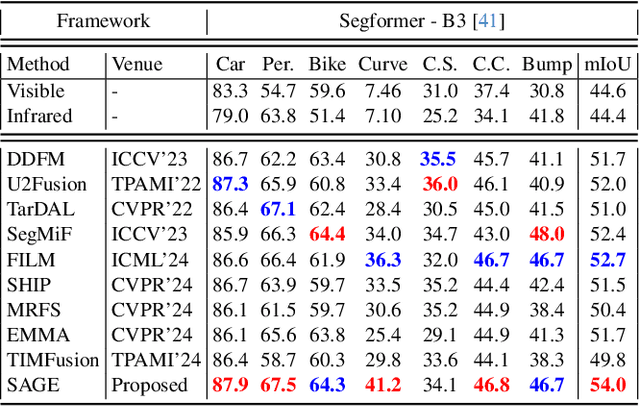
Multi-modality image fusion, particularly infrared and visible image fusion, plays a crucial role in integrating diverse modalities to enhance scene understanding. Early research primarily focused on visual quality, yet challenges remain in preserving fine details, making it difficult to adapt to subsequent tasks. Recent approaches have shifted towards task-specific design, but struggle to achieve the ``The Best of Both Worlds'' due to inconsistent optimization goals. To address these issues, we propose a novel method that leverages the semantic knowledge from the Segment Anything Model (SAM) to Grow the quality of fusion results and Establish downstream task adaptability, namely SAGE. Specifically, we design a Semantic Persistent Attention (SPA) Module that efficiently maintains source information via the persistent repository while extracting high-level semantic priors from SAM. More importantly, to eliminate the impractical dependence on SAM during inference, we introduce a bi-level optimization-driven distillation mechanism with triplet losses, which allow the student network to effectively extract knowledge at the feature, pixel, and contrastive semantic levels, thereby removing reliance on the cumbersome SAM model. Extensive experiments show that our method achieves a balance between high-quality visual results and downstream task adaptability while maintaining practical deployment efficiency.