 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation as Evolution: Transforming Adversarial Diffusion into Closed-Loop Curricula for Autonomous Vehicles
Apr 08, 2026Autonomous vehicles in interactive traffic environments are often limited by the scarcity of safety-critical tail events in static datasets, which biases learned policies toward average-case behaviors and reduces robustness. Existing evaluation methods attempt to address this through adversarial stress testing, but are predominantly open-loop and post-hoc, making it difficult to incorporate discovered failures back into the training process. We introduce Evaluation as Evolution ($E^2$), a closed-loop framework that transforms adversarial generation from a static validation step into an adaptive evolutionary curriculum. Specifically, $E^2$ formulates adversarial scenario synthesis as transport-regularized sparse control over a learned reverse-time SDE prior. To make this high-dimensional generation tractable, we utilize topology-driven support selection to identify critical interacting agents, and introduce Topological Anchoring to stabilize the process. This approach enables the targeted discovery of failure cases while strictly constraining deviations from realistic data distributions. Empirically, $E^2$ improves collision failure discovery by 9.01% on the nuScenes dataset and up to 21.43% on the nuPlan dataset over the strongest baselines, while maintaining low invalidity and high realism. It further yields substantial robustness gains when the resulting boundary cases are recycled for closed-loop policy fine-tuning.
A Knowledge-Driven Diffusion Policy for End-to-End Autonomous Driving Based on Expert Routing
Sep 05, 2025End-to-end autonomous driving remains constrained by the need to generate multi-modal actions, maintain temporal stability, and generalize across diverse scenarios. Existing methods often collapse multi-modality, struggle with long-horizon consistency, or lack modular adaptability. This paper presents KDP, a knowledge-driven diffusion policy that integrates generative diffusion modeling with a sparse mixture-of-experts routing mechanism. The diffusion component generates temporally coherent and multi-modal action sequences, while the expert routing mechanism activates specialized and reusable experts according to context, enabling modular knowledge composition. Extensive experiments across representative driving scenarios demonstrate that KDP achieves consistently higher success rates, reduced collision risk, and smoother control compared to prevailing paradigms. Ablation studies highlight the effectiveness of sparse expert activation and the Transformer backbone, and activation analyses reveal structured specialization and cross-scenario reuse of experts. These results establish diffusion with expert routing as a scalable and interpretable paradigm for knowledge-driven end-to-end autonomous driving.
Interactive Adversarial Testing of Autonomous Vehicles with Adjustable Confrontation Intensity
Jul 29, 2025Scientific testing techniques are essential for ensuring the safe operation of autonomous vehicles (AVs), with high-risk, highly interactive scenarios being a primary focus. To address the limitations of existing testing methods, such as their heavy reliance on high-quality test data, weak interaction capabilities, and low adversarial robustness, this paper proposes ExamPPO, an interactive adversarial testing framework that enables scenario-adaptive and intensity-controllable evaluation of autonomous vehicles. The framework models the Surrounding Vehicle (SV) as an intelligent examiner, equipped with a multi-head attention-enhanced policy network, enabling context-sensitive and sustained behavioral interventions. A scalar confrontation factor is introduced to modulate the intensity of adversarial behaviors, allowing continuous, fine-grained adjustment of test difficulty. Coupled with structured evaluation metrics, ExamPPO systematically probes AV's robustness across diverse scenarios and strategies. Extensive experiments across multiple scenarios and AV strategies demonstrate that ExamPPO can effectively modulate adversarial behavior, expose decision-making weaknesses in tested AVs, and generalize across heterogeneous environments, thereby offering a unified and reproducible solution for evaluating the safety and intelligence of autonomous decision-making systems.
Towards Human-Centric Autonomous Driving: A Fast-Slow Architecture Integrating Large Language Model Guidance with Reinforcement Learning
May 11, 2025Autonomous driving has made significant strides through data-driven techniques, achieving robust performance in standardized tasks. However, existing methods frequently overlook user-specific preferences, offering limited scope for interaction and adaptation with users. To address these challenges, we propose a "fast-slow" decision-making framework that integrates a Large Language Model (LLM) for high-level instruction parsing with a Reinforcement Learning (RL) agent for low-level real-time decision. In this dual system, the LLM operates as the "slow" module, translating user directives into structured guidance, while the RL agent functions as the "fast" module, making time-critical maneuvers under stringent latency constraints. By decoupling high-level decision making from rapid control, our framework enables personalized user-centric operation while maintaining robust safety margins. Experimental evaluations across various driving scenarios demonstrate the effectiveness of our method. Compared to baseline algorithms, the proposed architecture not only reduces collision rates but also aligns driving behaviors more closely with user preferences, thereby achieving a human-centric mode. By integrating user guidance at the decision level and refining it with real-time control, our framework bridges the gap between individual passenger needs and the rigor required for safe, reliable driving in complex traffic environments.
MAPPO-PIS: A Multi-Agent Proximal Policy Optimization Method with Prior Intent Sharing for CAVs' Cooperative Decision-Making
Aug 13, 2024



Vehicle-to-Vehicle (V2V) technologies have great potential for enhancing traffic flow efficiency and safety. However, cooperative decision-making in multi-agent systems, particularly in complex human-machine mixed merging areas, remains challenging for connected and autonomous vehicles (CAVs). Intent sharing, a key aspect of human coordination, may offer an effective solution to these decision-making problems, but its application in CAVs is under-explored. This paper presents an intent-sharing-based cooperative method, the Multi-Agent Proximal Policy Optimization with Prior Intent Sharing (MAPPO-PIS), which models the CAV cooperative decision-making problem as a Multi-Agent Reinforcement Learning (MARL) problem. It involves training and updating the agents' policies through the integration of two key modules: the Intention Generator Module (IGM) and the Safety Enhanced Module (SEM). The IGM is specifically crafted to generate and disseminate CAVs' intended trajectories spanning multiple future time-steps. On the other hand, the SEM serves a crucial role in assessing the safety of the decisions made and rectifying them if necessary. Merging area with human-machine mixed traffic flow is selected to validate our method. Results show that MAPPO-PIS significantly improves decision-making performance in multi-agent systems, surpassing state-of-the-art baselines in safety, efficiency, and overall traffic system performance. The code and video demo can be found at: \url{https://github.com/CCCC1dhcgd/A-MAPPO-PIS}.
Detecting Log Anomalies with Multi-Head Attention (LAMA)
Jan 07, 2021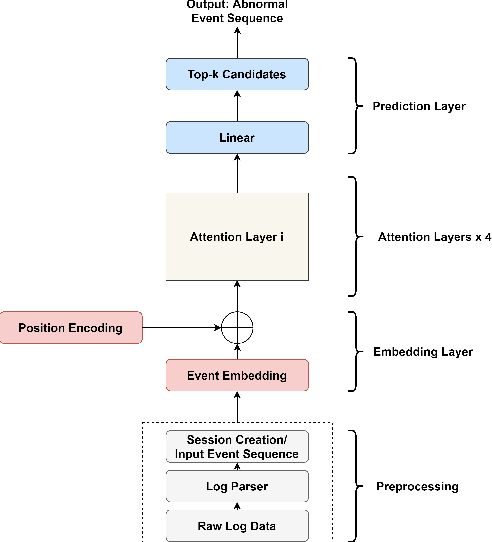

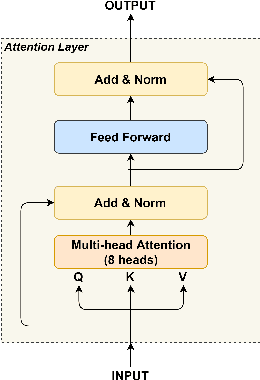
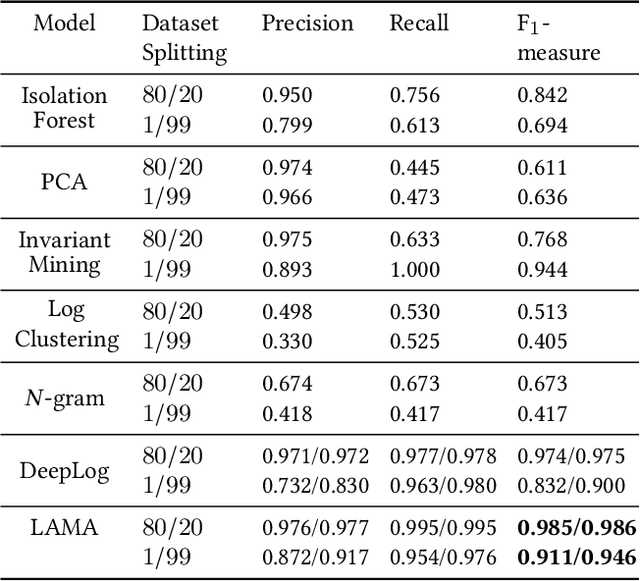
Anomaly detection is a crucial and challenging subject that has been studied within diverse research areas. In this work, we explore the task of log anomaly detection (especially computer system logs and user behavior logs) by analyzing logs' sequential information. We propose LAMA, a multi-head attention based sequential model to process log streams as template activity (event) sequences. A next event prediction task is applied to train the model for anomaly detection. Extensive empirical studies demonstrate that our new model outperforms existing log anomaly detection methods including statistical and deep learning methodologies, which validate the effectiveness of our proposed method in learning sequence patterns of log data.