 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduled Sampling in Vision-Language Pretraining with Decoupled Encoder-Decoder Network
Jan 27, 2021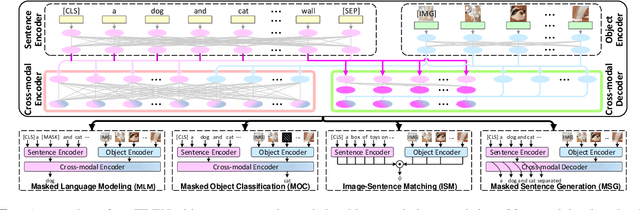
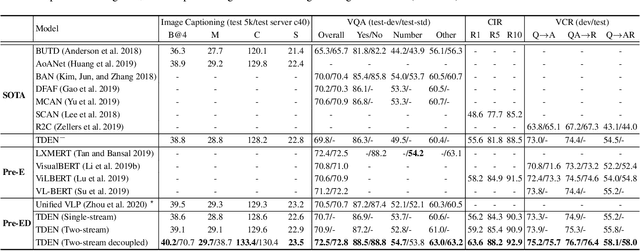

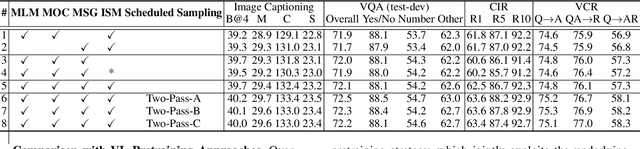
Despite having impressive vision-language (VL) pretraining with BERT-based encoder for VL understanding, the pretraining of a universal encoder-decoder for both VL understanding and generation remains challenging. The difficulty originates from the inherently different peculiarities of the two disciplines, e.g., VL understanding tasks capitalize on the unrestricted message passing across modalities, while generation tasks only employ visual-to-textual message passing. In this paper, we start with a two-stream decoupled design of encoder-decoder structure, in which two decoupled cross-modal encoder and decoder are involved to separately perform each type of proxy tasks, for simultaneous VL understanding and generation pretraining. Moreover, for VL pretraining, the dominant way is to replace some input visual/word tokens with mask tokens and enforce the multi-modal encoder/decoder to reconstruct the original tokens, but no mask token is involved when fine-tuning on downstream tasks. As an alternative, we propose a primary scheduled sampling strategy that elegantly mitigates such discrepancy via pretraining encoder-decoder in a two-pass manner. Extensive experiments demonstrate the compelling generalizability of our pretrained encoder-decoder by fine-tuning on four VL understanding and generation downstream tasks. Source code is available at \url{https://github.com/YehLi/TDEN}.
Pre-training for Video Captioning Challenge 2020 Summary
Jul 27, 2020
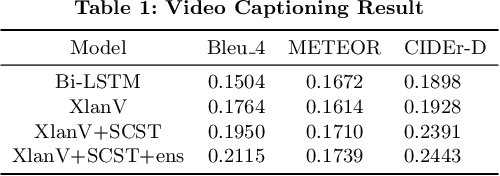
The Pre-training for Video Captioning Challenge 2020 Summary: results and challenge participants' technical reports.
Auto-captions on GIF: A Large-scale Video-sentence Dataset for Vision-language Pre-training
Jul 05, 2020
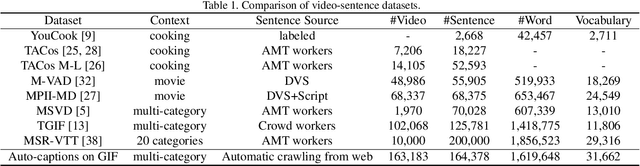
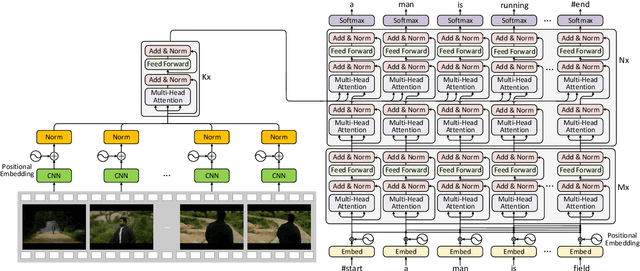
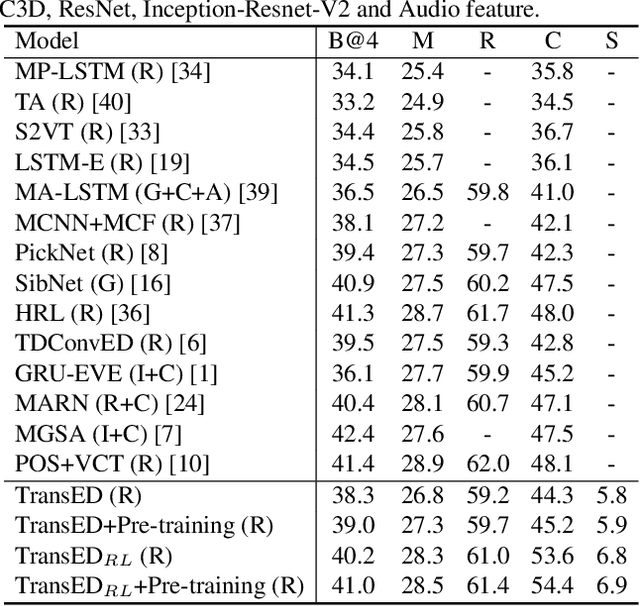
In this work, we present Auto-captions on GIF, which is a new large-scale pre-training dataset for generic video understanding. All video-sentence pairs are created by automatically extracting and filtering video caption annotations from billions of web pages. Auto-captions on GIF dataset can be utilized to pre-train the generic feature representation or encoder-decoder structure for video captioning, and other downstream tasks (e.g., sentence localization in videos, video question answering, etc.) as well. We present a detailed analysis of Auto-captions on GIF dataset in comparison to existing video-sentence datasets. We also provide an evaluation of a Transformer-based encoder-decoder structure for vision-language pre-training, which is further adapted to video captioning downstream task and yields the compelling generalizability on MSR-VTT. The dataset is available at \url{http://www.auto-video-captions.top/2020/dataset}.
Exploring Category-Agnostic Clusters for Open-Set Domain Adaptation
Jun 11, 2020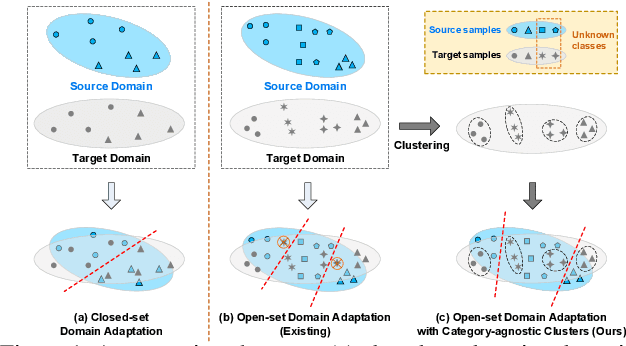
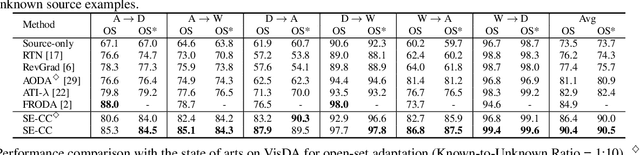
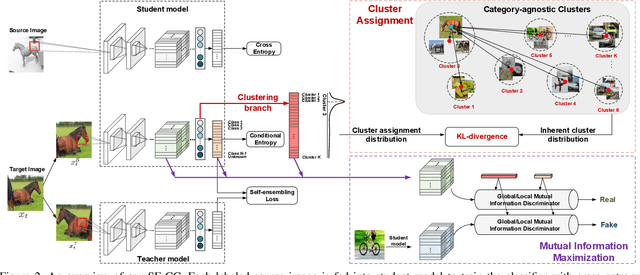
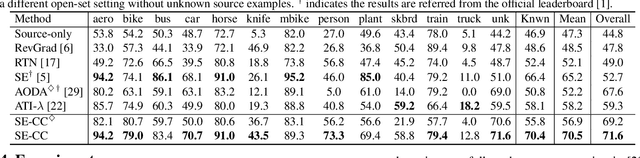
Unsupervised domain adaptation has received significant attention in recent years. Most of existing works tackle the closed-set scenario, assuming that the source and target domains share the exactly same categories. In practice, nevertheless, a target domain often contains samples of classes unseen in source domain (i.e., unknown class). The extension of domain adaptation from closed-set to such open-set situation is not trivial since the target samples in unknown class are not expected to align with the source. In this paper, we address this problem by augmenting the state-of-the-art domain adaptation technique, Self-Ensembling, with category-agnostic clusters in target domain. Specifically, we present Self-Ensembling with Category-agnostic Clusters (SE-CC) -- a novel architecture that steers domain adaptation with the additional guidance of category-agnostic clusters that are specific to target domain. These clustering information provides domain-specific visual cues, facilitating the generalization of Self-Ensembling for both closed-set and open-set scenarios. Technically, clustering is firstly performed over all the unlabeled target samples to obtain the category-agnostic clusters, which reveal the underlying data space structure peculiar to target domain. A clustering branch is capitalized on to ensure that the learnt representation preserves such underlying structure by matching the estimated assignment distribution over clusters to the inherent cluster distribution for each target sample. Furthermore, SE-CC enhances the learnt representation with mutual information maximization. Extensive experiments are conducted on Office and VisDA datasets for both open-set and closed-set domain adaptation, and superior results are reported when comparing to the state-of-the-art approaches.
X-Linear Attention Networks for Image Captioning
Mar 31, 2020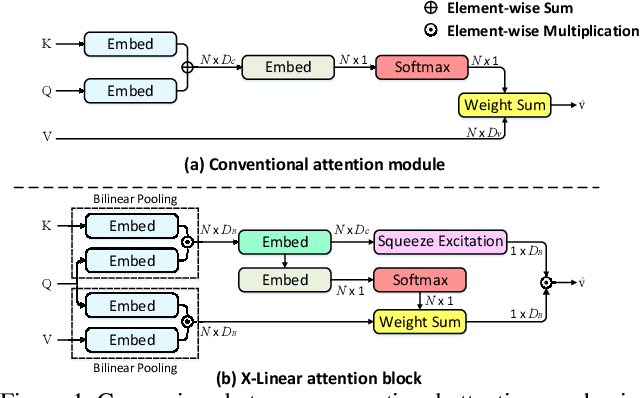
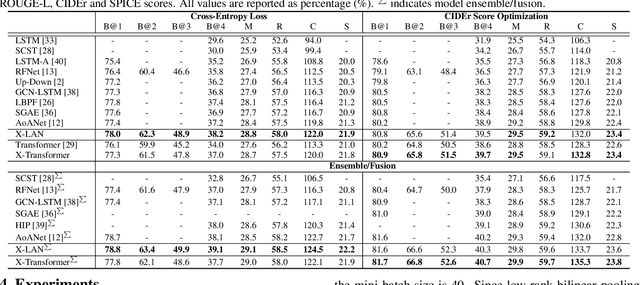
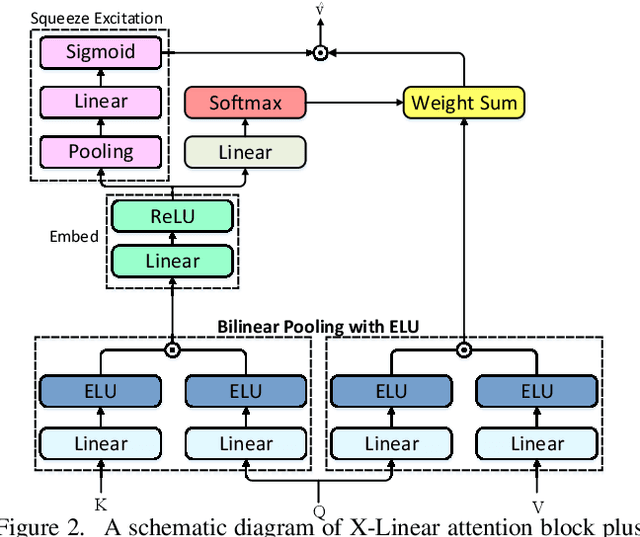
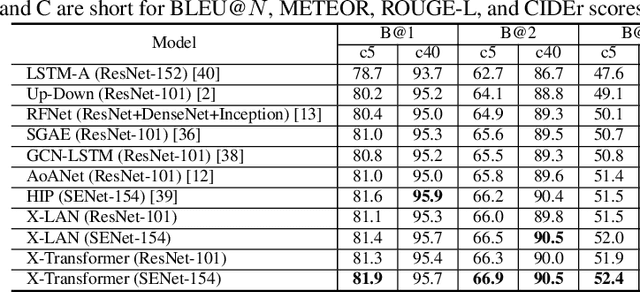
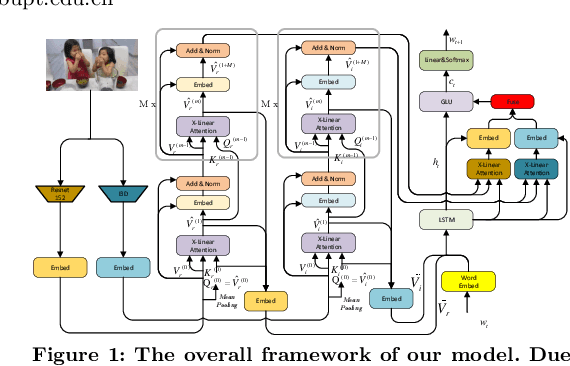
Recent progress on fine-grained visual recognition and visual question answering has featured Bilinear Pooling, which effectively models the 2$^{nd}$ order interactions across multi-modal inputs. Nevertheless, there has not been evidence in support of building such interactions concurrently with attention mechanism for image captioning. In this paper, we introduce a unified attention block -- X-Linear attention block, that fully employs bilinear pooling to selectively capitalize on visual information or perform multi-modal reasoning. Technically, X-Linear attention block simultaneously exploits both the spatial and channel-wise bilinear attention distributions to capture the 2$^{nd}$ order interactions between the input single-modal or multi-modal features. Higher and even infinity order feature interactions are readily modeled through stacking multiple X-Linear attention blocks and equipping the block with Exponential Linear Unit (ELU) in a parameter-free fashion, respectively. Furthermore, we present X-Linear Attention Networks (dubbed as X-LAN) that novelly integrates X-Linear attention block(s) into image encoder and sentence decoder of image captioning model to leverage higher order intra- and inter-modal interactions. The experiments on COCO benchmark demonstrate that our X-LAN obtains to-date the best published CIDEr performance of 132.0% on COCO Karpathy test split. When further endowing Transformer with X-Linear attention blocks, CIDEr is boosted up to 132.8%. Source code is available at \url{https://github.com/Panda-Peter/image-captioning}.
Multi-Source Domain Adaptation and Semi-Supervised Domain Adaptation with Focus on Visual Domain Adaptation Challenge 2019
Oct 14, 2019
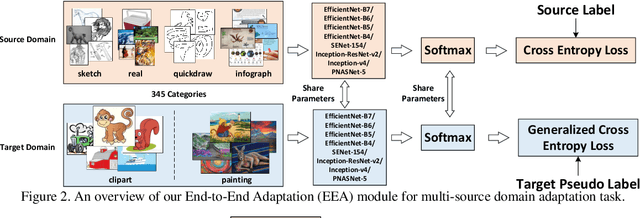
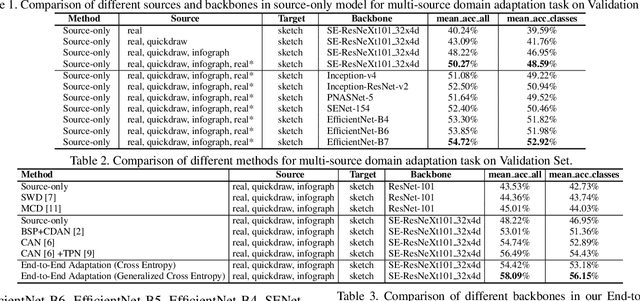
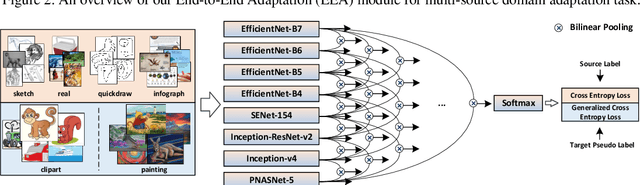
This notebook paper presents an overview and comparative analysis of our systems designed for the following two tasks in Visual Domain Adaptation Challenge (VisDA-2019): multi-source domain adaptation and semi-supervised domain adaptation. Multi-Source Domain Adaptation: We investigate both pixel-level and feature-level adaptation for multi-source domain adaptation task, i.e., directly hallucinating labeled target sample via CycleGAN and learning domain-invariant feature representations through self-learning. Moreover, the mechanism of fusing features from different backbones is further studied to facilitate the learning of domain-invariant classifiers. Source code and pre-trained models are available at \url{https://github.com/Panda-Peter/visda2019-multisource}. Semi-Supervised Domain Adaptation: For this task, we adopt a standard self-learning framework to construct a classifier based on the labeled source and target data, and generate the pseudo labels for unlabeled target data. These target data with pseudo labels are then exploited to re-training the classifier in a following iteration. Furthermore, a prototype-based classification module is additionally utilized to strengthen the predictions. Source code and pre-trained models are available at \url{https://github.com/Panda-Peter/visda2019-semisupervised}.
Hierarchy Parsing for Image Captioning
Sep 10, 2019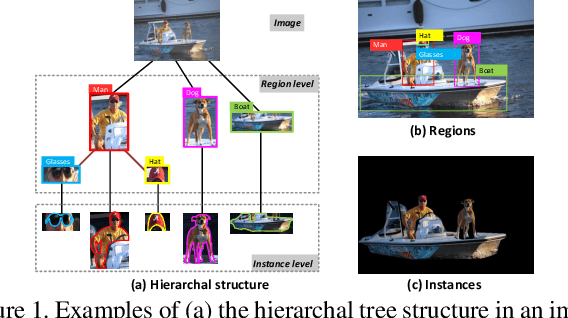
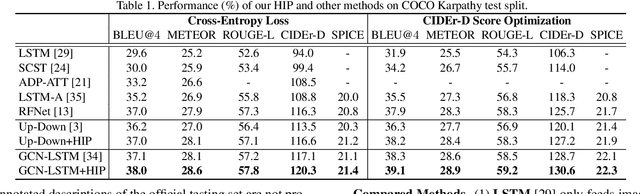
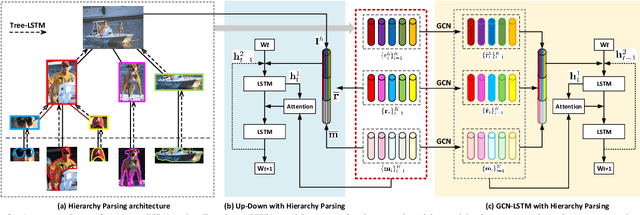
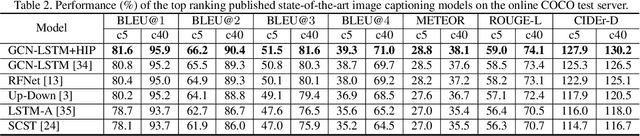
It is always well believed that parsing an image into constituent visual patterns would be helpful for understanding and representing an image. Nevertheless, there has not been evidence in support of the idea on describing an image with a natural-language utterance. In this paper, we introduce a new design to model a hierarchy from instance level (segmentation), region level (detection) to the whole image to delve into a thorough image understanding for captioning. Specifically, we present a HIerarchy Parsing (HIP) architecture that novelly integrates hierarchical structure into image encoder. Technically, an image decomposes into a set of regions and some of the regions are resolved into finer ones. Each region then regresses to an instance, i.e., foreground of the region. Such process naturally builds a hierarchal tree. A tree-structured Long Short-Term Memory (Tree-LSTM) network is then employed to interpret the hierarchal structure and enhance all the instance-level, region-level and image-level features. Our HIP is appealing in view that it is pluggable to any neural captioning models. Extensive experiments on COCO image captioning dataset demonstrate the superiority of HIP. More remarkably, HIP plus a top-down attention-based LSTM decoder increases CIDEr-D performance from 120.1% to 127.2% on COCO Karpathy test split. When further endowing instance-level and region-level features from HIP with semantic relation learnt through Graph Convolutional Networks (GCN), CIDEr-D is boosted up to 130.6%.
Deep Metric Learning with Density Adaptivity
Sep 09, 2019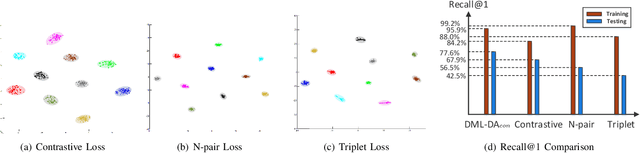
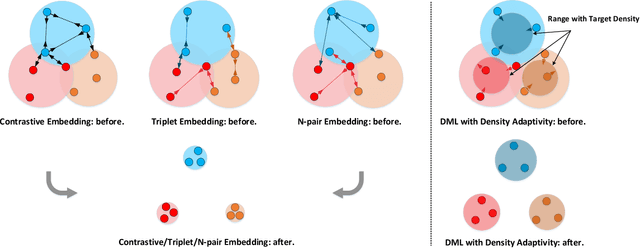
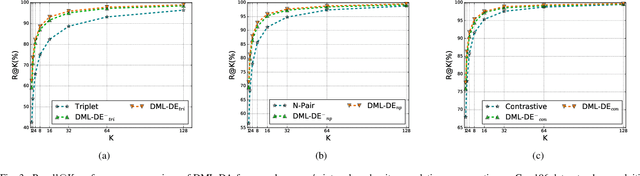
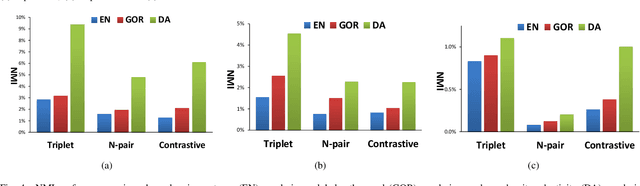
The problem of distance metric learning is mostly considered from the perspective of learning an embedding space, where the distances between pairs of examples are in correspondence with a similarity metric. With the rise and success of Convolutional Neural Networks (CNN), deep metric learning (DML) involves training a network to learn a nonlinear transformation to the embedding space. Existing DML approaches often express the supervision through maximizing inter-class distance and minimizing intra-class variation. However, the results can suffer from overfitting problem, especially when the training examples of each class are embedded together tightly and the density of each class is very high. In this paper, we integrate density, i.e., the measure of data concentration in the representation, into the optimization of DML frameworks to adaptively balance inter-class similarity and intra-class variation by training the architecture in an end-to-end manner. Technically, the knowledge of density is employed as a regularizer, which is pluggable to any DML architecture with different objective functions such as contrastive loss, N-pair loss and triplet loss. Extensive experiments on three public datasets consistently demonstrate clear improvements by amending three types of embedding with the density adaptivity. More remarkably, our proposal increases Recall@1 from 67.95% to 77.62%, from 52.01% to 55.64% and from 68.20% to 70.56% on Cars196, CUB-200-2011 and Stanford Online Products dataset, respectively.
Trimmed Action Recognition, Dense-Captioning Events in Videos, and Spatio-temporal Action Localization with Focus on ActivityNet Challenge 2019
Jun 14, 2019
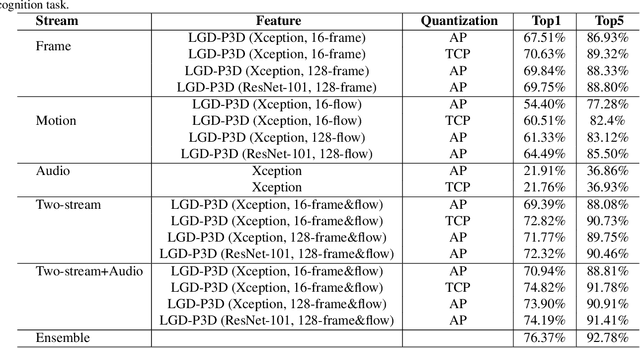

This notebook paper presents an overview and comparative analysis of our systems designed for the following three tasks in ActivityNet Challenge 2019: trimmed action recognition, dense-captioning events in videos, and spatio-temporal action localization.
Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning
May 03, 2019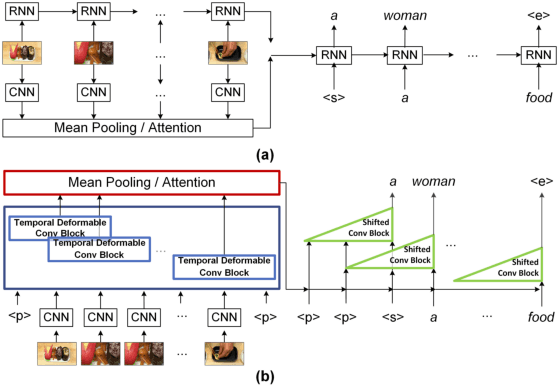
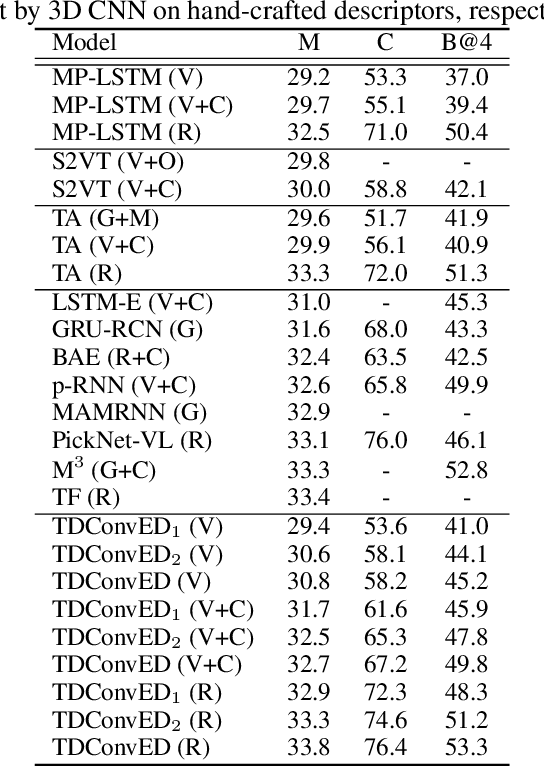
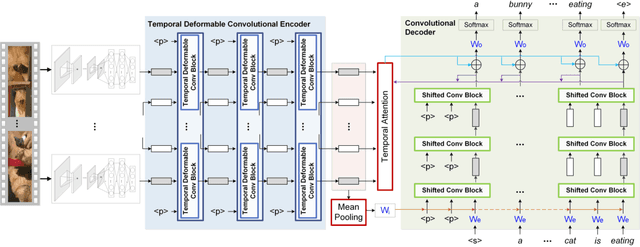
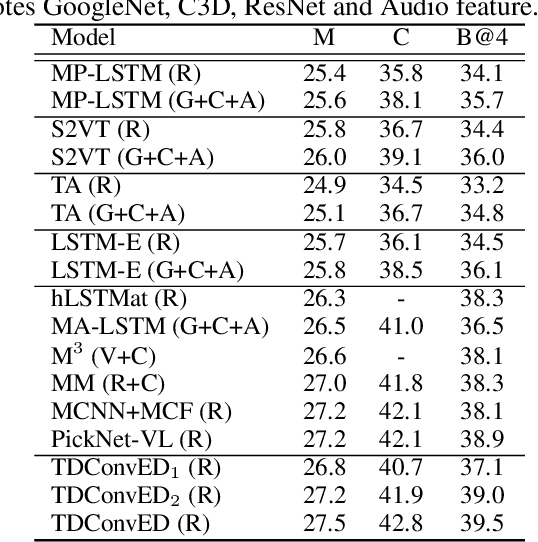
It is well believed that video captioning is a fundamental but challenging task in both computer vision and artificial intelligence fields. The prevalent approach is to map an input video to a variable-length output sentence in a sequence to sequence manner via Recurrent Neural Network (RNN). Nevertheless, the training of RNN still suffers to some degree from vanishing/exploding gradient problem, making the optimization difficult. Moreover, the inherently recurrent dependency in RNN prevents parallelization within a sequence during training and therefore limits the computations. In this paper, we present a novel design --- Temporal Deformable Convolutional Encoder-Decoder Networks (dubbed as TDConvED) that fully employ convolutions in both encoder and decoder networks for video captioning. Technically, we exploit convolutional block structures that compute intermediate states of a fixed number of inputs and stack several blocks to capture long-term relationships. The structure in encoder is further equipped with temporal deformable convolution to enable free-form deformation of temporal sampling. Our model also capitalizes on temporal attention mechanism for sentence generation. Extensive experiments are conducted on both MSVD and MSR-VTT video captioning datasets, and superior results are reported when comparing to conventional RNN-based encoder-decoder techniques. More remarkably, TDConvED increases CIDEr-D performance from 58.8% to 67.2% on MSVD.