 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleDiffusion: Prompt-Embedding Inversion for Text-Based Editing
Mar 28, 2023



A significant research effort is focused on exploiting the amazing capacities of pretrained diffusion models for the editing of images. They either finetune the model, or invert the image in the latent space of the pretrained model. However, they suffer from two problems: (1) Unsatisfying results for selected regions, and unexpected changes in nonselected regions. (2) They require careful text prompt editing where the prompt should include all visual objects in the input image. To address this, we propose two improvements: (1) Only optimizing the input of the value linear network in the cross-attention layers, is sufficiently powerful to reconstruct a real image. (2) We propose attention regularization to preserve the object-like attention maps after editing, enabling us to obtain accurate style editing without invoking significant structural changes. We further improve the editing technique which is used for the unconditional branch of classifier-free guidance, as well as the conditional one as used by P2P. Extensive experimental prompt-editing results on a variety of images, demonstrate qualitatively and quantitatively that our method has superior editing capabilities than existing and concurrent works.
3D-Aware Multi-Class Image-to-Image Translation with NeRFs
Mar 27, 2023Recent advances in 3D-aware generative models (3D-aware GANs) combined with Neural Radiance Fields (NeRF) have achieved impressive results. However no prior works investigate 3D-aware GANs for 3D consistent multi-class image-to-image (3D-aware I2I) translation. Naively using 2D-I2I translation methods suffers from unrealistic shape/identity change. To perform 3D-aware multi-class I2I translation, we decouple this learning process into a multi-class 3D-aware GAN step and a 3D-aware I2I translation step. In the first step, we propose two novel techniques: a new conditional architecture and an effective training strategy. In the second step, based on the well-trained multi-class 3D-aware GAN architecture, that preserves view-consistency, we construct a 3D-aware I2I translation system. To further reduce the view-consistency problems, we propose several new techniques, including a U-net-like adaptor network design, a hierarchical representation constrain and a relative regularization loss. In extensive experiments on two datasets, quantitative and qualitative results demonstrate that we successfully perform 3D-aware I2I translation with multi-view consistency.
Adaptive Texture Filtering for Single-Domain Generalized Segmentation
Mar 06, 2023



Domain generalization in semantic segmentation aims to alleviate the performance degradation on unseen domains through learning domain-invariant features. Existing methods diversify images in the source domain by adding complex or even abnormal textures to reduce the sensitivity to domain specific features. However, these approaches depend heavily on the richness of the texture bank, and training them can be time-consuming. In contrast to importing textures arbitrarily or augmenting styles randomly, we focus on the single source domain itself to achieve generalization. In this paper, we present a novel adaptive texture filtering mechanism to suppress the influence of texture without using augmentation, thus eliminating the interference of domain-specific features. Further, we design a hierarchical guidance generalization network equipped with structure-guided enhancement modules, which purpose is to learn the domain-invariant generalized knowledge. Extensive experiments together with ablation studies on widely-used datasets are conducted to verify the effectiveness of the proposed model, and reveal its superiority over other state-of-the-art alternatives.
One Ring to Bring Them All: Towards Open-Set Recognition under Domain Shift
Jun 07, 2022
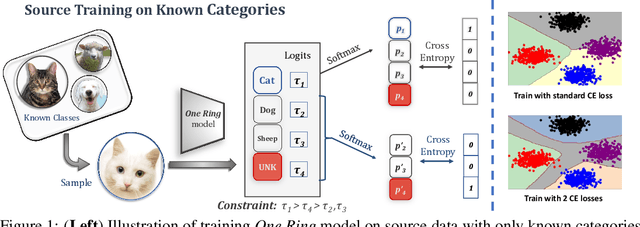


In this paper, we investigate $\textit{open-set recognition}$ with domain shift, where the final goal is to achieve $\textit{Source-free Universal Domain Adaptation}$ (SF-UNDA), which addresses the situation where there exist both domain and category shifts between source and target domains. Under the SF-UNDA setting, the model cannot access source data anymore during target adaptation, which aims to address data privacy concerns. We propose a novel training scheme to learn a ($n$+1)-way classifier to predict the $n$ source classes and the unknown class, where samples of only known source categories are available for training. Furthermore, for target adaptation, we simply adopt a weighted entropy minimization to adapt the source pretrained model to the unlabeled target domain without source data. In experiments, we show: $\textbf{1)}$ After source training, the resulting source model can get excellent performance for $\textit{open-set single domain generalization}$ and also $\textit{open-set recognition}$ tasks; $\textbf{2)}$ After target adaptation, our method surpasses current UNDA approaches which demand source data during adaptation on several benchmarks. The versatility to several different tasks strongly proves the efficacy and generalization ability of our method. $\textbf{3)}$ When augmented with a closed-set domain adaptation approach during target adaptation, our source-free method further outperforms the current state-of-the-art UNDA method by 2.5%, 7.2% and 13% on Office-31, Office-Home and VisDA respectively. Code will be available in https://github.com/Albert0147/OneRing.
MVMO: A Multi-Object Dataset for Wide Baseline Multi-View Semantic Segmentation
May 30, 2022
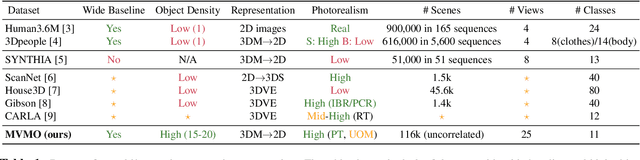
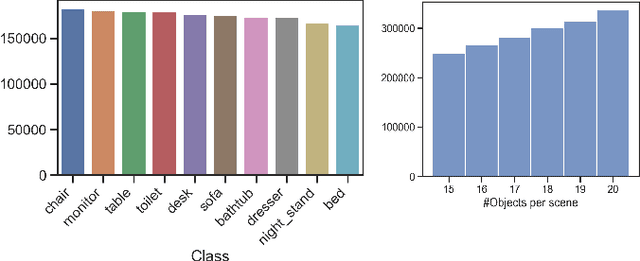
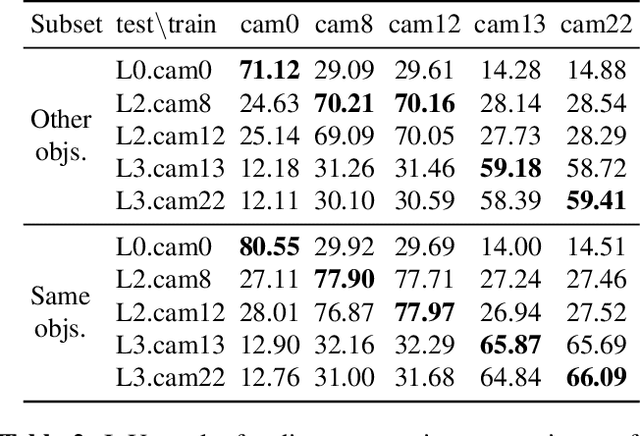
We present MVMO (Multi-View, Multi-Object dataset): a synthetic dataset of 116,000 scenes containing randomly placed objects of 10 distinct classes and captured from 25 camera locations in the upper hemisphere. MVMO comprises photorealistic, path-traced image renders, together with semantic segmentation ground truth for every view. Unlike existing multi-view datasets, MVMO features wide baselines between cameras and high density of objects, which lead to large disparities, heavy occlusions and view-dependent object appearance. Single view semantic segmentation is hindered by self and inter-object occlusions that could benefit from additional viewpoints. Therefore, we expect that MVMO will propel research in multi-view semantic segmentation and cross-view semantic transfer. We also provide baselines that show that new research is needed in such fields to exploit the complementary information of multi-view setups.
Attracting and Dispersing: A Simple Approach for Source-free Domain Adaptation
May 19, 2022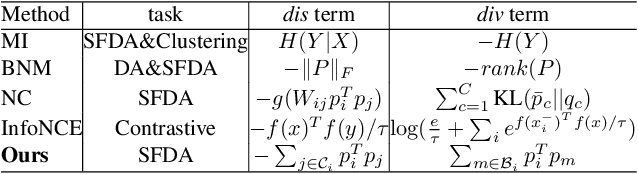

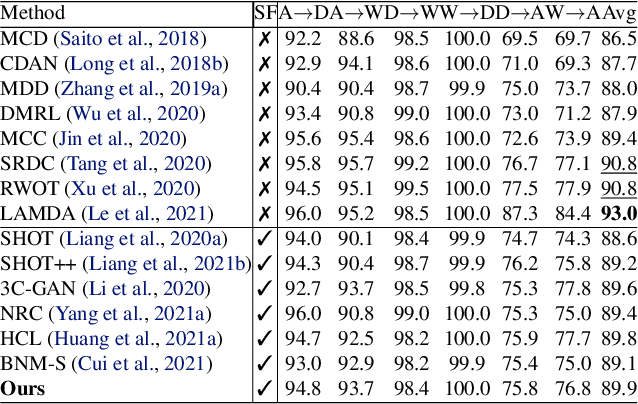
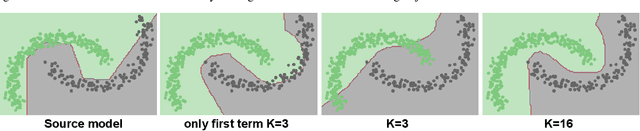
We propose a simple but effective source-free domain adaptation (SFDA) method. Treating SFDA as an unsupervised clustering problem and following the intuition that local neighbors in feature space should have more similar predictions than other features, we propose to optimize an objective of prediction consistency. This objective encourages local neighborhood features in feature space to have similar predictions while features farther away in feature space have dissimilar predictions, leading to efficient feature clustering and cluster assignment simultaneously. For efficient training, we seek to optimize an upper-bound of the objective resulting in two simple terms. Furthermore, we relate popular existing methods in domain adaptation, source-free domain adaptation and contrastive learning via the perspective of discriminability and diversity. The experimental results prove the superiority of our method, and our method can be adopted as a simple but strong baseline for future research in SFDA. Our method can be also adapted to source-free open-set and partial-set DA which further shows the generalization ability of our method.
Hyper-GAN: Transferring Unconditional to Conditional GANs with HyperNetworks
Dec 04, 2021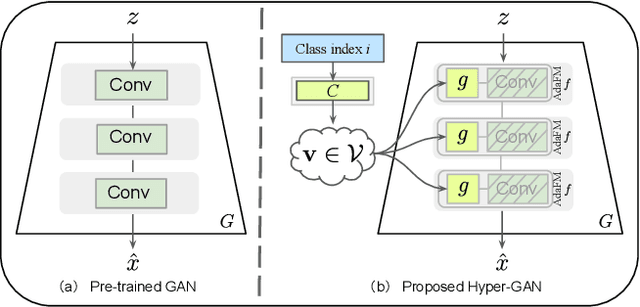

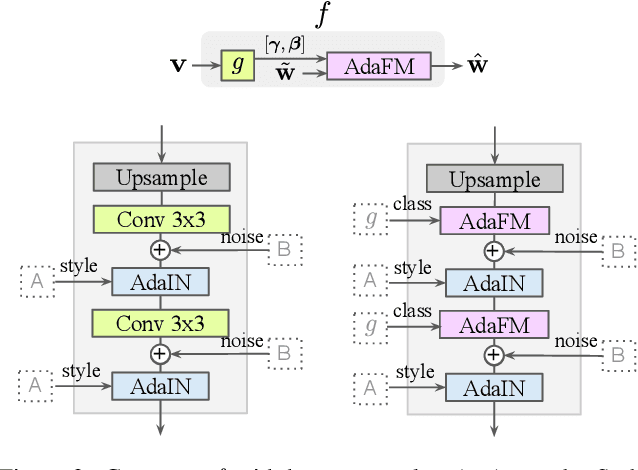
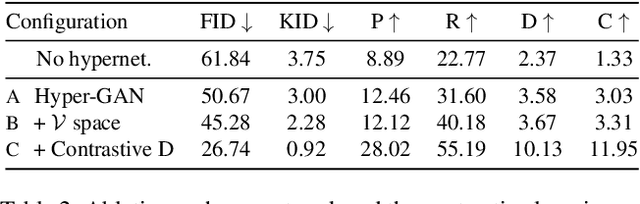
Conditional GANs have matured in recent years and are able to generate high-quality realistic images. However, the computational resources and the training data required for the training of high-quality GANs are enormous, and the study of transfer learning of these models is therefore an urgent topic. In this paper, we explore the transfer from high-quality pre-trained unconditional GANs to conditional GANs. To this end, we propose hypernetwork-based adaptive weight modulation. In addition, we introduce a self-initialization procedure that does not require any real data to initialize the hypernetwork parameters. To further improve the sample efficiency of the knowledge transfer, we propose to use a self-supervised (contrastive) loss to improve the GAN discriminator. In extensive experiments, we validate the efficiency of the hypernetworks, self-initialization and contrastive loss for knowledge transfer on several standard benchmarks.
A Novel Framework for Image-to-image Translation and Image Compression
Nov 25, 2021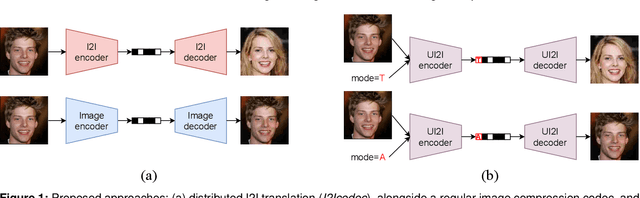
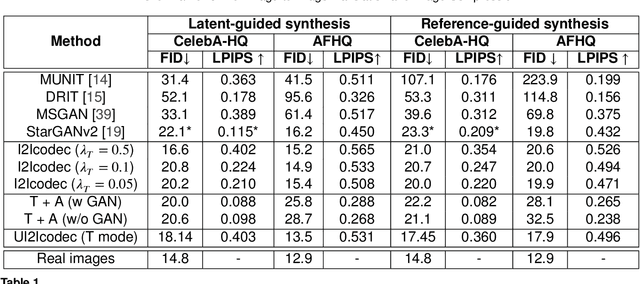
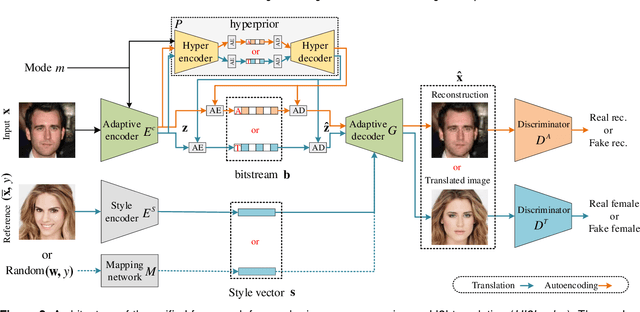

Data-driven paradigms using machine learning are becoming ubiquitous in image processing and communications. In particular, image-to-image (I2I) translation is a generic and widely used approach to image processing problems, such as image synthesis, style transfer, and image restoration. At the same time, neural image compression has emerged as a data-driven alternative to traditional coding approaches in visual communications. In this paper, we study the combination of these two paradigms into a joint I2I compression and translation framework, focusing on multi-domain image synthesis. We first propose distributed I2I translation by integrating quantization and entropy coding into an I2I translation framework (i.e. I2Icodec). In practice, the image compression functionality (i.e. autoencoding) is also desirable, requiring to deploy alongside I2Icodec a regular image codec. Thus, we further propose a unified framework that allows both translation and autoencoding capabilities in a single codec. Adaptive residual blocks conditioned on the translation/compression mode provide flexible adaptation to the desired functionality. The experiments show promising results in both I2I translation and image compression using a single model.
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021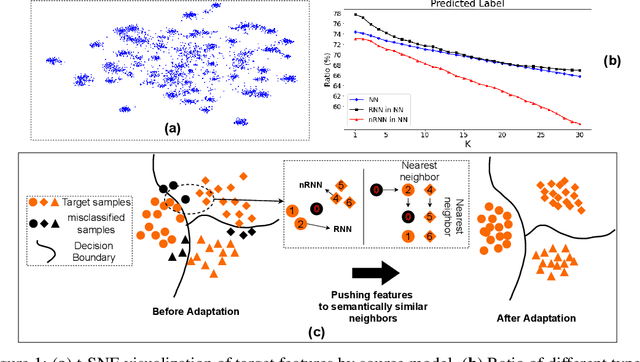
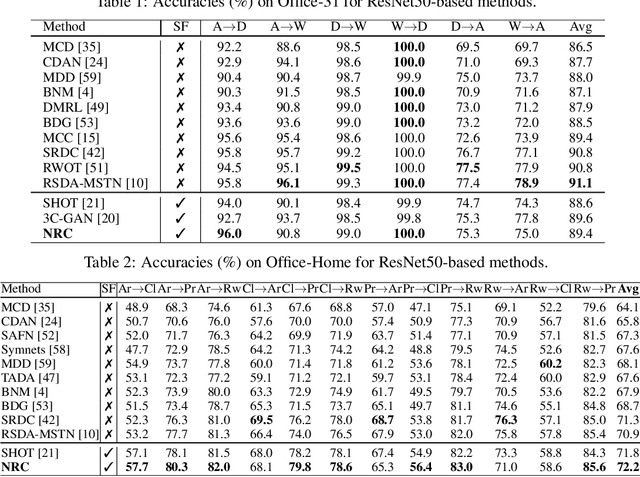
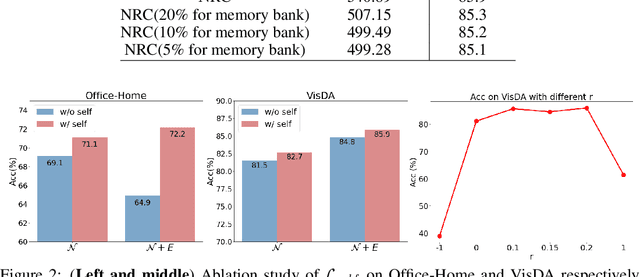
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.
Generalized Source-free Domain Adaptation
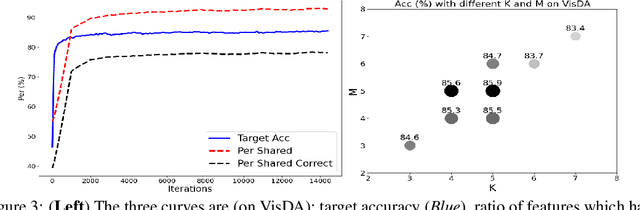
Aug 03, 2021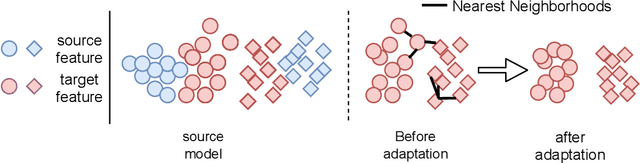
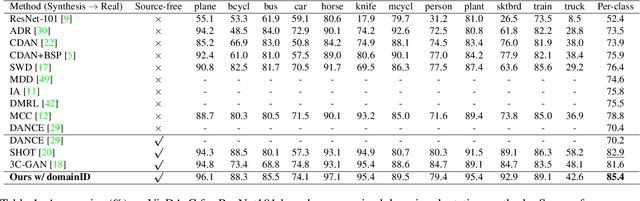
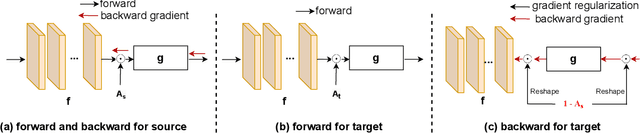
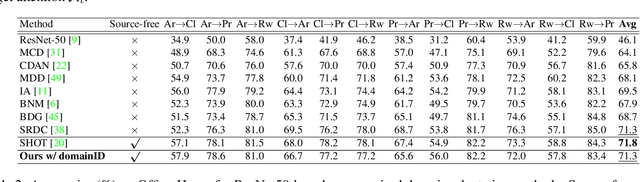
Domain adaptation (DA) aims to transfer the knowledge learned from a source domain to an unlabeled target domain. Some recent works tackle source-free domain adaptation (SFDA) where only a source pre-trained model is available for adaptation to the target domain. However, those methods do not consider keeping source performance which is of high practical value in real world applications. In this paper, we propose a new domain adaptation paradigm called Generalized Source-free Domain Adaptation (G-SFDA), where the learned model needs to perform well on both the target and source domains, with only access to current unlabeled target data during adaptation. First, we propose local structure clustering (LSC), aiming to cluster the target features with its semantically similar neighbors, which successfully adapts the model to the target domain in the absence of source data. Second, we propose sparse domain attention (SDA), it produces a binary domain specific attention to activate different feature channels for different domains, meanwhile the domain attention will be utilized to regularize the gradient during adaptation to keep source information. In the experiments, for target performance our method is on par with or better than existing DA and SFDA methods, specifically it achieves state-of-the-art performance (85.4%) on VisDA, and our method works well for all domains after adapting to single or multiple target domains. Code is available in https://github.com/Albert0147/G-SFDA.