 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-DHL: WiFi, IMU, and Floorplan Fusion for Dense History of Locations in Indoor Environments
May 18, 2021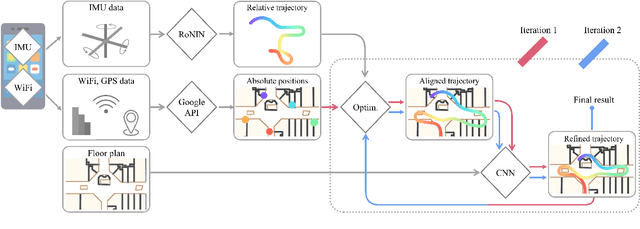
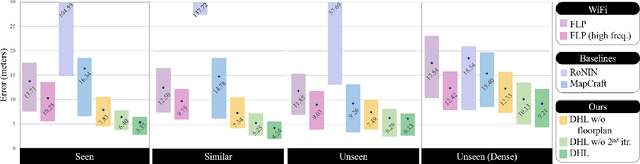
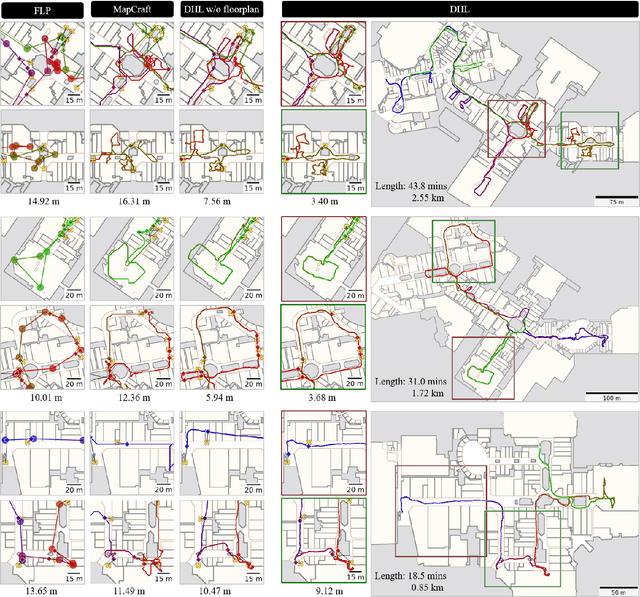
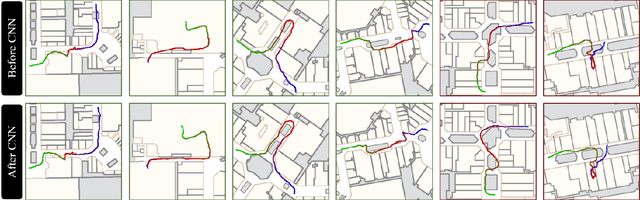
The paper proposes a multi-modal sensor fusion algorithm that fuses WiFi, IMU, and floorplan information to infer an accurate and dense location history in indoor environments. The algorithm uses 1) an inertial navigation algorithm to estimate a relative motion trajectory from IMU sensor data; 2) a WiFi-based localization API in industry to obtain positional constraints and geo-localize the trajectory; and 3) a convolutional neural network to refine the location history to be consistent with the floorplan. We have developed a data acquisition app to build a new dataset with WiFi, IMU, and floorplan data with ground-truth positions at 4 university buildings and 3 shopping malls. Our qualitative and quantitative evaluations demonstrate that the proposed system is able to produce twice as accurate and a few orders of magnitude denser location history than the current standard, while requiring minimal additional energy consumption. We will publicly share our code, data and models.
* To be published in ICRA 2021. Code and data: https://github.com/Sachini/Fusion-DHL
Heterogeneous Grid Convolution for Adaptive, Efficient, and Controllable Computation
Apr 22, 2021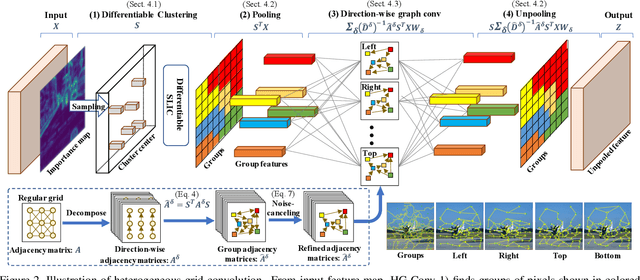
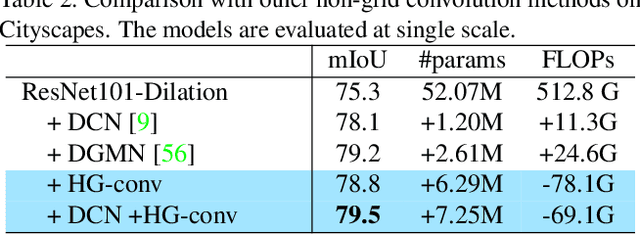

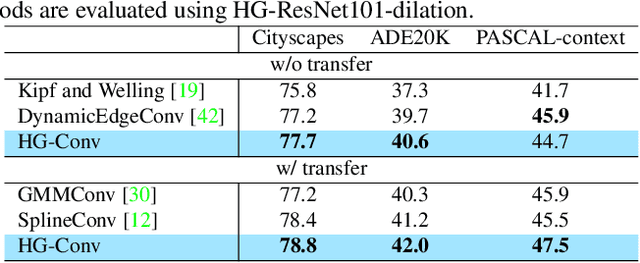
This paper proposes a novel heterogeneous grid convolution that builds a graph-based image representation by exploiting heterogeneity in the image content, enabling adaptive, efficient, and controllable computations in a convolutional architecture. More concretely, the approach builds a data-adaptive graph structure from a convolutional layer by a differentiable clustering method, pools features to the graph, performs a novel direction-aware graph convolution, and unpool features back to the convolutional layer. By using the developed module, the paper proposes heterogeneous grid convolutional networks, highly efficient yet strong extension of existing architectures. We have evaluated the proposed approach on four image understanding tasks, semantic segmentation, object localization, road extraction, and salient object detection. The proposed method is effective on three of the four tasks. Especially, the method outperforms a strong baseline with more than 90% reduction in floating-point operations for semantic segmentation, and achieves the state-of-the-art result for road extraction. We will share our code, model, and data.
House-GAN++: Generative Adversarial Layout Refinement Networks
Mar 03, 2021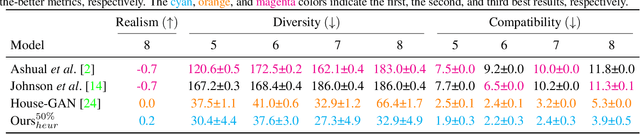
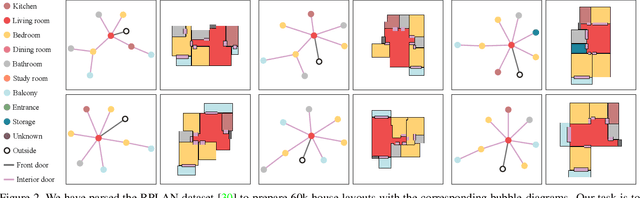
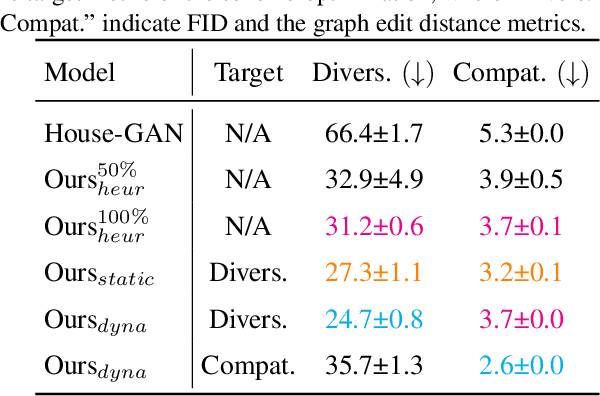
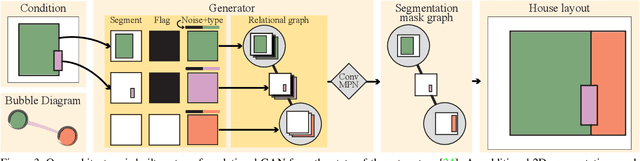
This paper proposes a novel generative adversarial layout refinement network for automated floorplan generation. Our architecture is an integration of a graph-constrained relational GAN and a conditional GAN, where a previously generated layout becomes the next input constraint, enabling iterative refinement. A surprising discovery of our research is that a simple non-iterative training process, dubbed component-wise GT-conditioning, is effective in learning such a generator. The iterative generator also creates a new opportunity in further improving a metric of choice via meta-optimization techniques by controlling when to pass which input constraints during iterative layout refinement. Our qualitative and quantitative evaluation based on the three standard metrics demonstrate that the proposed system makes significant improvements over the current state-of-the-art, even competitive against the ground-truth floorplans, designed by professional architects.
Roof-GAN: Learning to Generate Roof Geometry and Relations for Residential Houses
Dec 17, 2020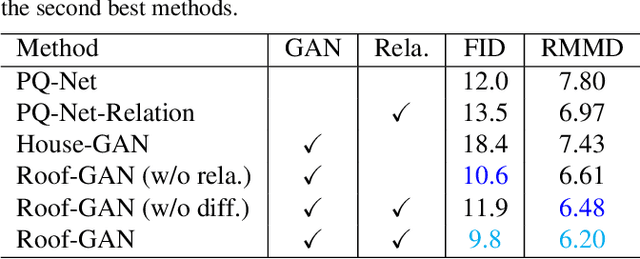
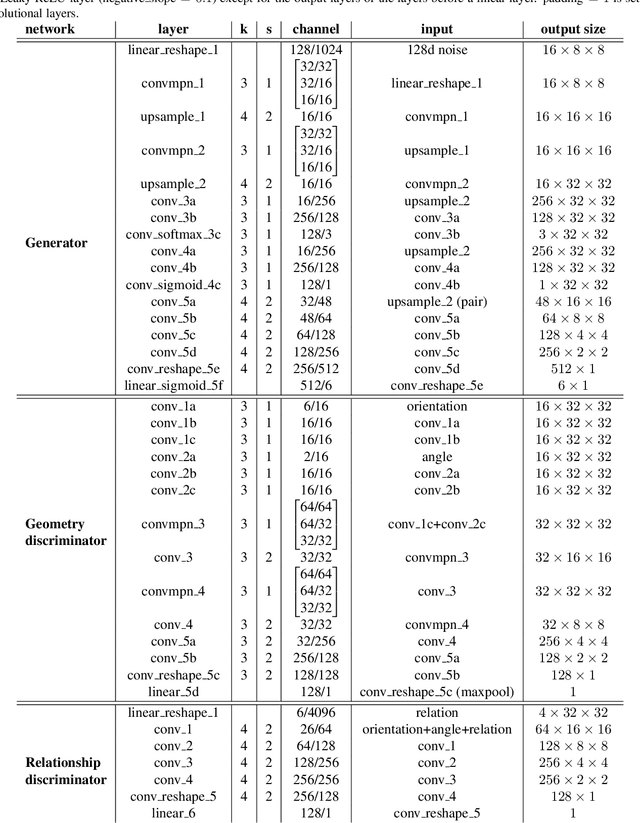
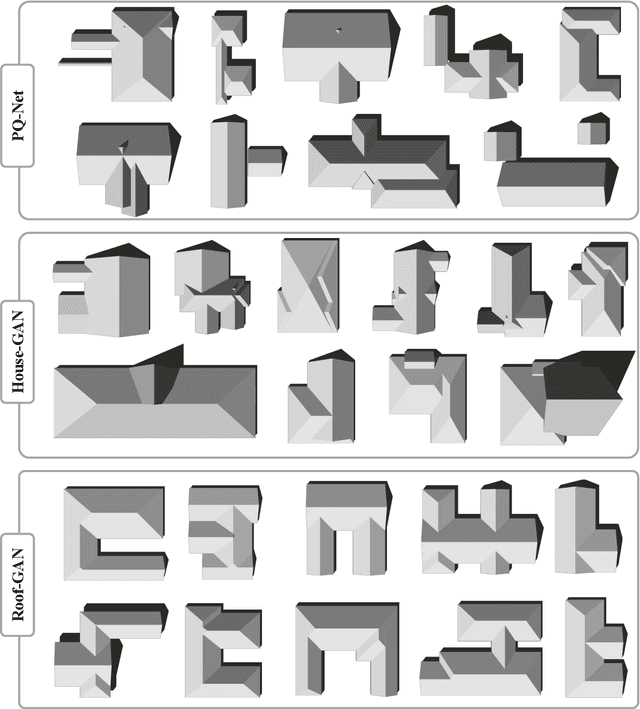
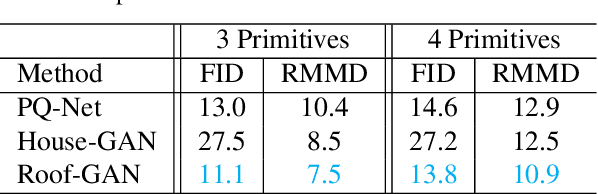
This paper presents Roof-GAN, a novel generative adversarial network that generates structured geometry of residential roof structures as a set of roof primitives and their relationships. Given the number of primitives, the generator produces a structured roof model as a graph, which consists of 1) primitive geometry as raster images at each node, encoding facet segmentation and angles; 2) inter-primitive colinear/coplanar relationships at each edge; and 3) primitive geometry in a vector format at each node, generated by a novel differentiable vectorizer while enforcing the relationships. The discriminator is trained to assess the primitive raster geometry, the primitive relationships, and the primitive vector geometry in a fully end-to-end architecture. Qualitative and quantitative evaluations demonstrate the effectiveness of our approach in generating diverse and realistic roof models over the competing methods with a novel metric proposed in this paper for the task of structured geometry generation. We will share our code and data.
House-GAN: Relational Generative Adversarial Networks for Graph-constrained House Layout Generation
Mar 16, 2020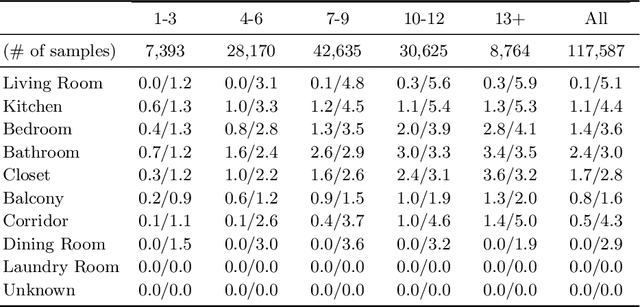
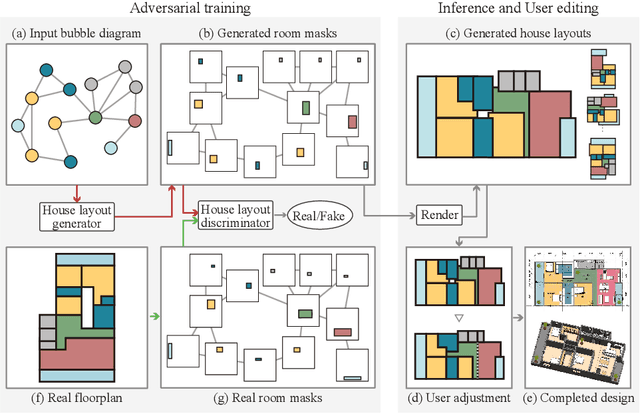
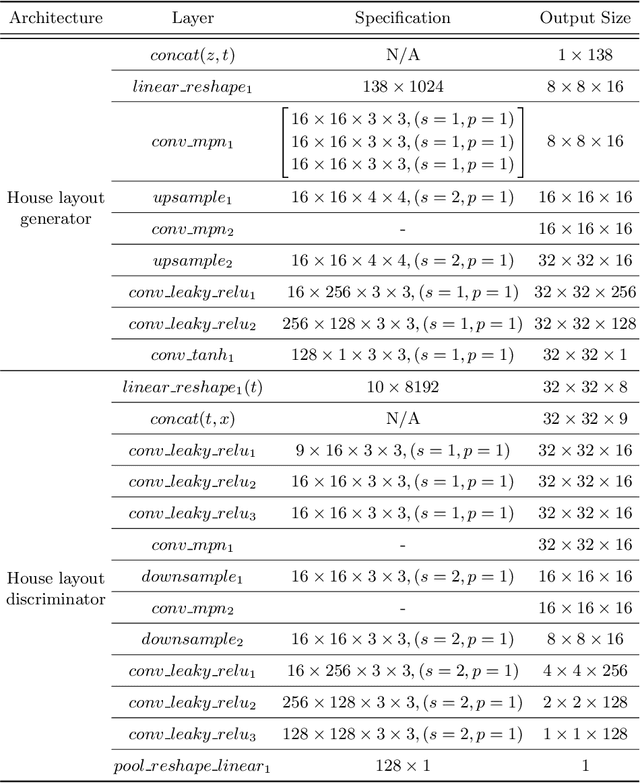
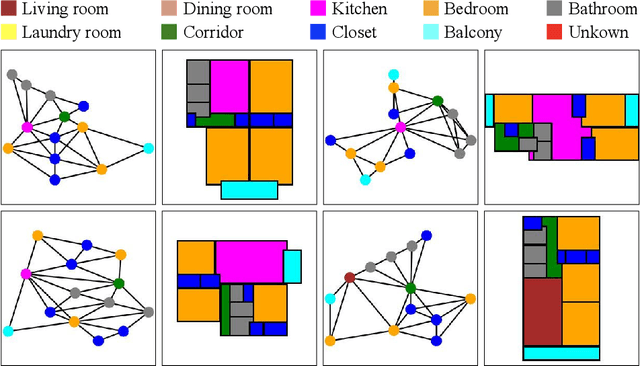
This paper proposes a novel graph-constrained generative adversarial network, whose generator and discriminator are built upon relational architecture. The main idea is to encode the constraint into the graph structure of its relational networks. We have demonstrated the proposed architecture for a new house layout generation problem, whose task is to take an architectural constraint as a graph (i.e., the number and types of rooms with their spatial adjacency) and produce a set of axis-aligned bounding boxes of rooms. We measure the quality of generated house layouts with the three metrics: the realism, the diversity, and the compatibility with the input graph constraint. Our qualitative and quantitative evaluations over 117,000 real floorplan images demonstrate that the proposed approach outperforms existing methods and baselines. We will publicly share all our code and data.
Vectorizing World Buildings: Planar Graph Reconstruction by Primitive Detection and Relationship Classification
Dec 12, 2019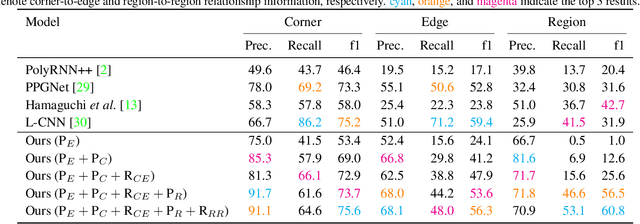


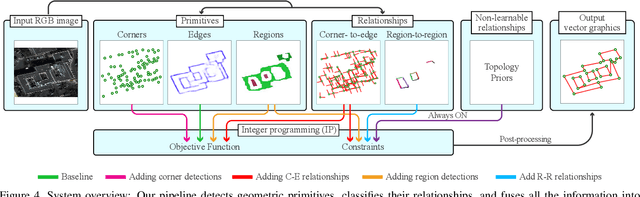
This paper tackles a 2D architecture vectorization problem, whose task is to infer an outdoor building architecture as a 2D planar graph from a single RGB image. We provide a new benchmark with ground-truth annotations for 2,001 complex buildings across the cities of Atlanta, Paris, and Las Vegas. We also propose a novel algorithm utilizing 1) convolutional neural networks (CNNs) that detects geometric primitives and classifies their relationships and 2) an integer programming (IP) that assembles the information into a 2D planar graph. While being a trivial task for human vision, the inference of a graph structure with an arbitrary topology is still an open problem for computer vision. Qualitative and quantitative evaluations demonstrate that our algorithm makes significant improvements over the current state-of-the-art, towards an intelligent system at the level of human perception. We will share code and data to promote further research.
Conv-MPN: Convolutional Message Passing Neural Network for Structured Outdoor Architecture Reconstruction
Dec 04, 2019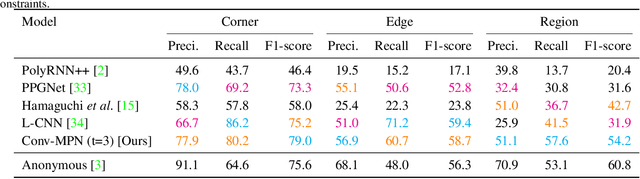

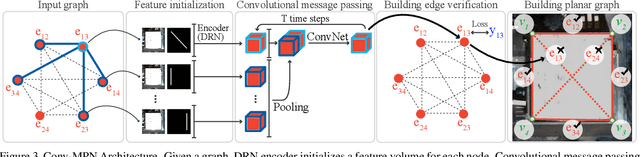
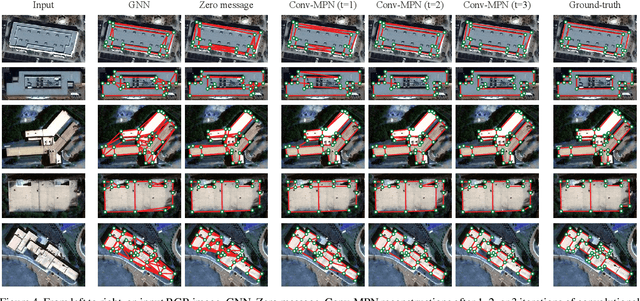
This paper proposes a novel message passing neural (MPN) architecture Conv-MPN, which reconstructs an outdoor building as a planar graph from a single RGB image. Conv-MPN is specifically designed for cases where nodes of a graph have explicit spatial embedding. In our problem, nodes correspond to building edges in an image. Conv-MPN is different from MPN in that 1) the feature associated with a node is represented as a feature volume instead of a 1D vector; and 2) convolutions encode messages instead of fully connected layers. Conv-MPN learns to select a true subset of nodes (i.e., building edges) to reconstruct a building planar graph. Our qualitative and quantitative evaluations over 2,000 buildings show that Conv-MPN makes significant improvements over the existing fully neural solutions. We believe that the paper has a potential to open a new line of graph neural network research for structured geometry reconstruction.
Floor-SP: Inverse CAD for Floorplans by Sequential Room-wise Shortest Path
Aug 19, 2019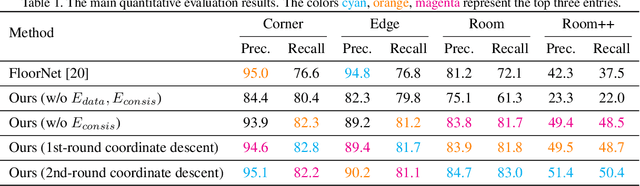
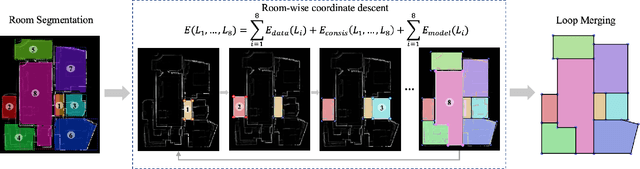
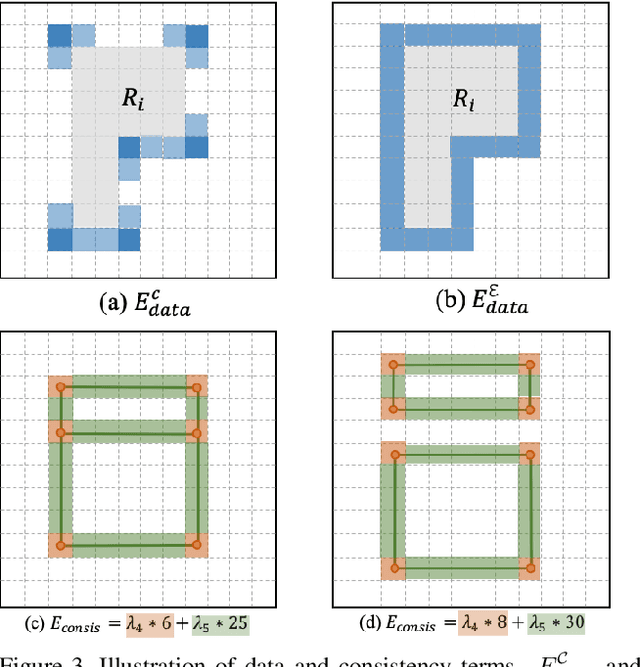
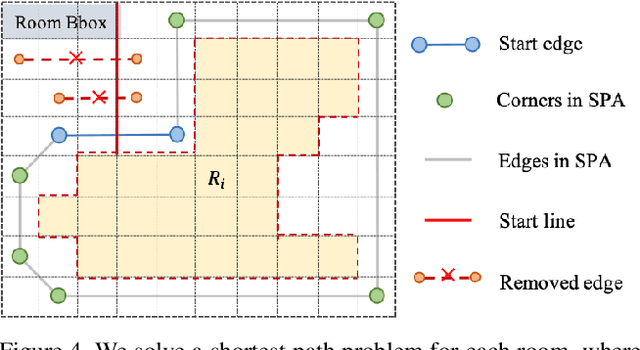
This paper proposes a new approach for automated floorplan reconstruction from RGBD scans, a major milestone in indoor mapping research. The approach, dubbed Floor-SP, formulates a novel optimization problem, where room-wise coordinate descent sequentially solves dynamic programming to optimize the floorplan graph structure. The objective function consists of data terms guided by deep neural networks, consistency terms encouraging adjacent rooms to share corners and walls, and the model complexity term. The approach does not require corner/edge detection with thresholds, unlike most other methods. We have evaluated our system on production-quality RGBD scans of 527 apartments or houses, including many units with non-Manhattan structures. Qualitative and quantitative evaluations demonstrate a significant performance boost over the current state-of-the-art. Please refer to our project website http://jcchen.me/floor-sp/ for code and data.
RoNIN: Robust Neural Inertial Navigation in the Wild: Benchmark, Evaluations, and New Methods
May 30, 2019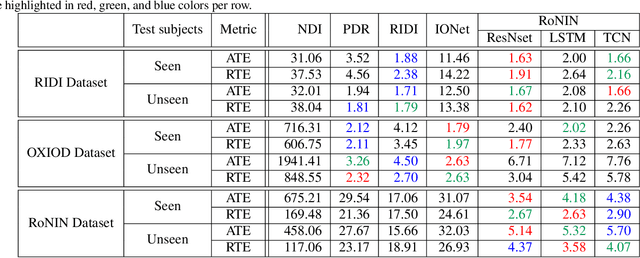
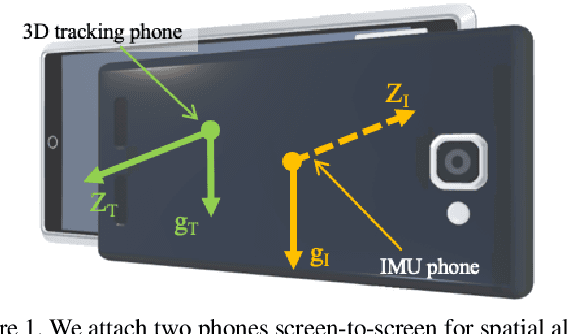
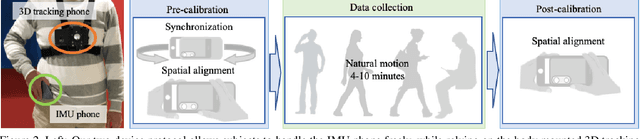
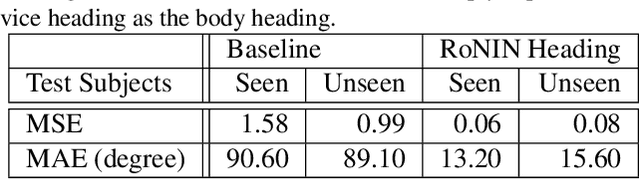
This paper sets a new foundation for data-driven inertial navigation research, where the task is the estimation of positions and orientations of a moving subject from a sequence of IMU sensor measurements. More concretely, the paper presents 1) a new benchmark containing more than 40 hours of IMU sensor data from 100 human subjects with ground-truth 3D trajectories under natural human motions; 2) novel neural inertial navigation architectures, making significant improvements for challenging motion cases; and 3) qualitative and quantitative evaluations of the competing methods over three inertial navigation benchmarks. We will share the code and data to promote further research.
MASC: Multi-scale Affinity with Sparse Convolution for 3D Instance Segmentation
Feb 12, 2019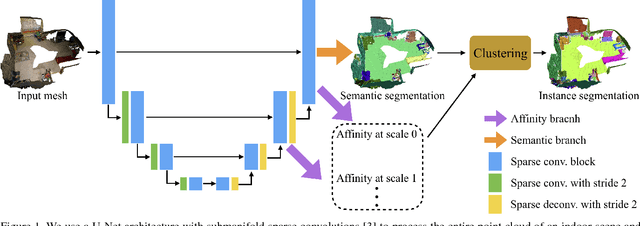


We propose a new approach for 3D instance segmentation based on sparse convolution and point affinity prediction, which indicates the likelihood of two points belonging to the same instance. The proposed network, built upon submanifold sparse convolution [3], processes a voxelized point cloud and predicts semantic scores for each occupied voxel as well as the affinity between neighboring voxels at different scales. A simple yet effective clustering algorithm segments points into instances based on the predicted affinity and the mesh topology. The semantic for each instance is determined by the semantic prediction. Experiments show that our method outperforms the state-of-the-art instance segmentation methods by a large margin on the widely used ScanNet benchmark [2]. We share our code publicly at https://github.com/art-programmer/MASC.