 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARAGS: A Multi-Adapter System for Multi-Task Retrieval Augmented Generation Question Answering
Sep 05, 2024



In this paper we present a multi-adapter retrieval augmented generation system (MARAGS) for Meta's Comprehensive RAG (CRAG) competition for KDD CUP 2024. CRAG is a question answering dataset contains 3 different subtasks aimed at realistic question and answering RAG related tasks, with a diverse set of question topics, question types, time dynamic answers, and questions featuring entities of varying popularity. Our system follows a standard setup for web based RAG, which uses processed web pages to provide context for an LLM to produce generations, while also querying API endpoints for additional information. MARAGS also utilizes multiple different adapters to solve the various requirements for these tasks with a standard cross-encoder model for ranking candidate passages relevant for answering the question. Our system achieved 2nd place for Task 1 as well as 3rd place on Task 2.
BEVERS: A General, Simple, and Performant Framework for Automatic Fact Verification
Mar 29, 2023Automatic fact verification has become an increasingly popular topic in recent years and among datasets the Fact Extraction and VERification (FEVER) dataset is one of the most popular. In this work we present BEVERS, a tuned baseline system for the FEVER dataset. Our pipeline uses standard approaches for document retrieval, sentence selection, and final claim classification, however, we spend considerable effort ensuring optimal performance for each component. The results are that BEVERS achieves the highest FEVER score and label accuracy among all systems, published or unpublished. We also apply this pipeline to another fact verification dataset, Scifact, and achieve the highest label accuracy among all systems on that dataset as well. We also make our full code available.
Improving Low-Resource Speech Recognition with Pretrained Speech Models: Continued Pretraining vs. Semi-Supervised Training
Jul 01, 2022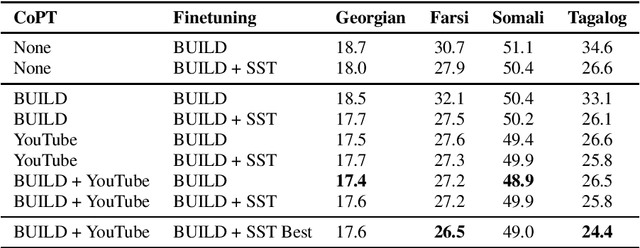
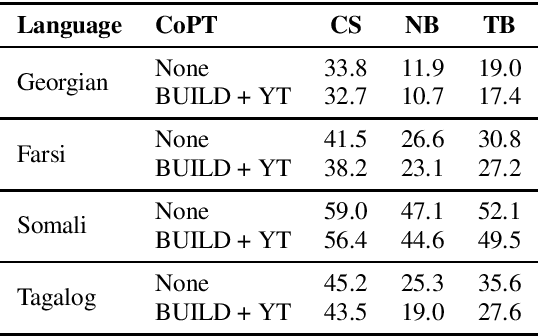
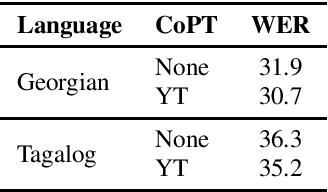
Self-supervised Transformer based models, such as wav2vec 2.0 and HuBERT, have produced significant improvements over existing approaches to automatic speech recognition (ASR). This is evident in the performance of the wav2vec 2.0 based pretrained XLSR-53 model across many languages when fine-tuned with available labeled data. However, the performance from finetuning these models can be dependent on the amount of in-language or similar-to-in-language data included in the pretraining dataset. In this paper we investigate continued pretraining (CoPT) with unlabeled in-language audio data on the XLSR-53 pretrained model in several low-resource languages. CoPT is more computationally efficient than semi-supervised training (SST), the standard approach of utilizing unlabeled data in ASR, since it omits the need for pseudo-labeling of the unlabeled data. We show CoPT results in word error rates (WERs), equal to or slightly better than using SST. In addition, we show that using the CoPT model for pseudo-labeling, and using these labels in SST, results in further improvements in WER.
Machine-Assisted Script Curation
Jan 14, 2021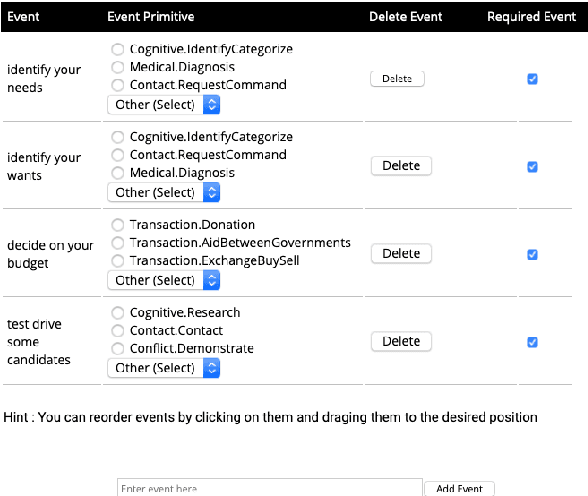
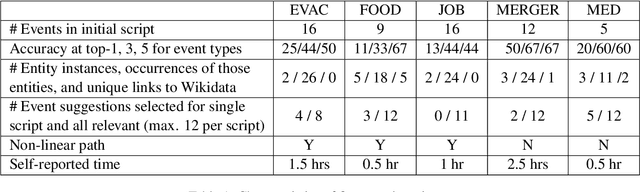
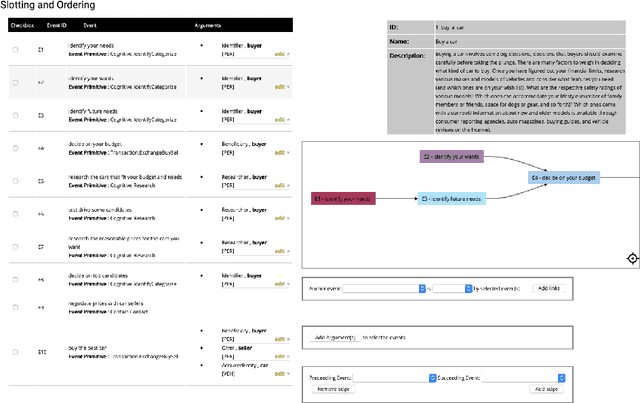
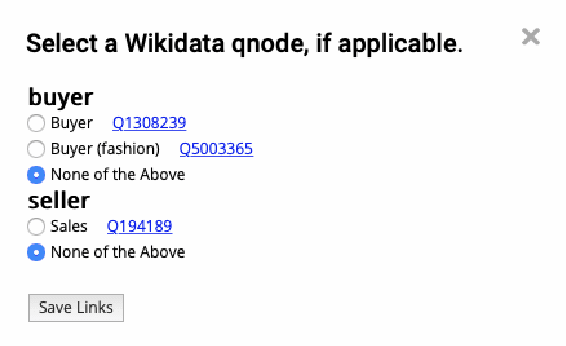
We describe Machine-Aided Script Curator (MASC), a system for human-machine collaborative script authoring. Scripts produced with MASC include (1) English descriptions of sub-events that comprise a larger, complex event; (2) event types for each of those events; (3) a record of entities expected to participate in multiple sub-events; and (4) temporal sequencing between the sub-events. MASC automates portions of the script creation process with suggestions for event types, links to Wikidata, and sub-events that may have been forgotten. We illustrate how these automations are useful to the script writer with a few case-study scripts.