 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeDUCE: Generating Counterfactual Explanations Efficiently
Nov 29, 2021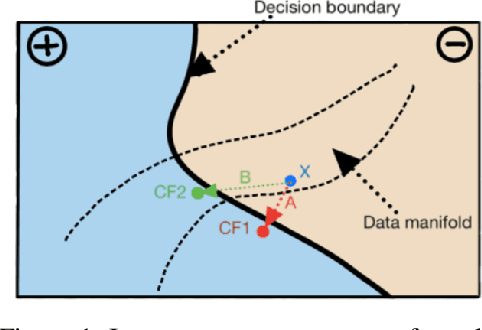

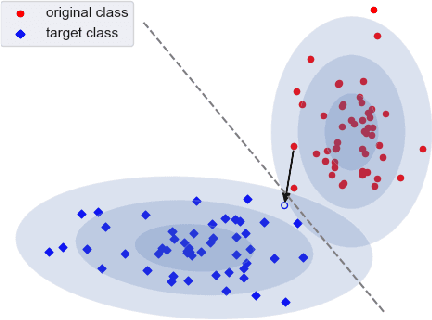

When an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. This is the aim of algorithms generating counterfactual explanations. However, there is no easily scalable method to generate such counterfactuals. We develop a new algorithm providing counterfactual explanations for large image classifiers trained with spectral normalisation at low computational cost. We empirically compare this algorithm against baselines from the literature; our novel algorithm consistently finds counterfactuals that are much closer to the original inputs. At the same time, the realism of these counterfactuals is comparable to the baselines. The code for all experiments is available at https://github.com/benedikthoeltgen/DeDUCE.
Contrastive Representation Learning with Trainable Augmentation Channel
Nov 15, 2021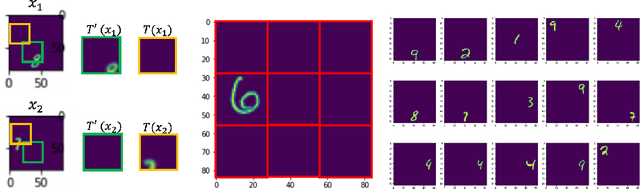

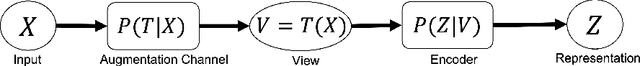

In contrastive representation learning, data representation is trained so that it can classify the image instances even when the images are altered by augmentations. However, depending on the datasets, some augmentations can damage the information of the images beyond recognition, and such augmentations can result in collapsed representations. We present a partial solution to this problem by formalizing a stochastic encoding process in which there exist a tug-of-war between the data corruption introduced by the augmentations and the information preserved by the encoder. We show that, with the infoMax objective based on this framework, we can learn a data-dependent distribution of augmentations to avoid the collapse of the representation.
Multi-Spectral Multi-Image Super-Resolution of Sentinel-2 with Radiometric Consistency Losses and Its Effect on Building Delineation
Nov 05, 2021
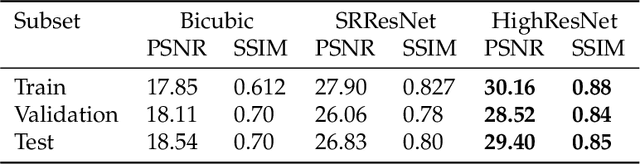
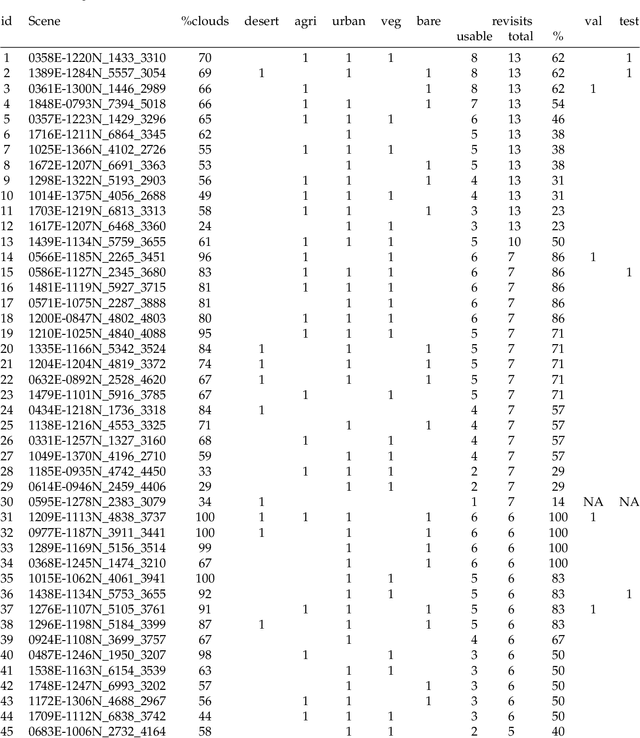
High resolution remote sensing imagery is used in broad range of tasks, including detection and classification of objects. High-resolution imagery is however expensive, while lower resolution imagery is often freely available and can be used by the public for range of social good applications. To that end, we curate a multi-spectral multi-image super-resolution dataset, using PlanetScope imagery from the SpaceNet 7 challenge as the high resolution reference and multiple Sentinel-2 revisits of the same imagery as the low-resolution imagery. We present the first results of applying multi-image super-resolution (MISR) to multi-spectral remote sensing imagery. We, additionally, introduce a radiometric consistency module into MISR model the to preserve the high radiometric resolution of the Sentinel-2 sensor. We show that MISR is superior to single-image super-resolution and other baselines on a range of image fidelity metrics. Furthermore, we conduct the first assessment of the utility of multi-image super-resolution on building delineation, showing that utilising multiple images results in better performance in these downstream tasks.
Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data
Nov 03, 2021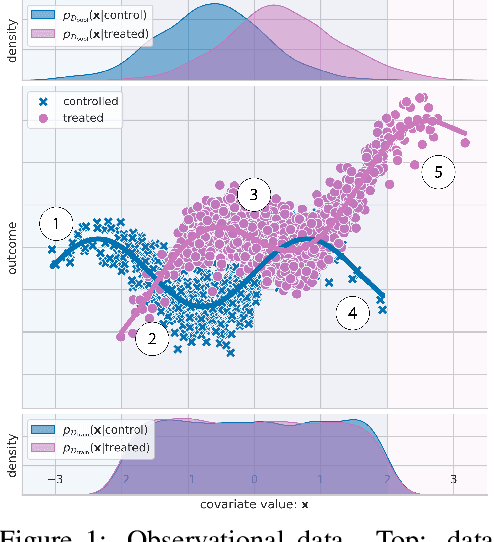
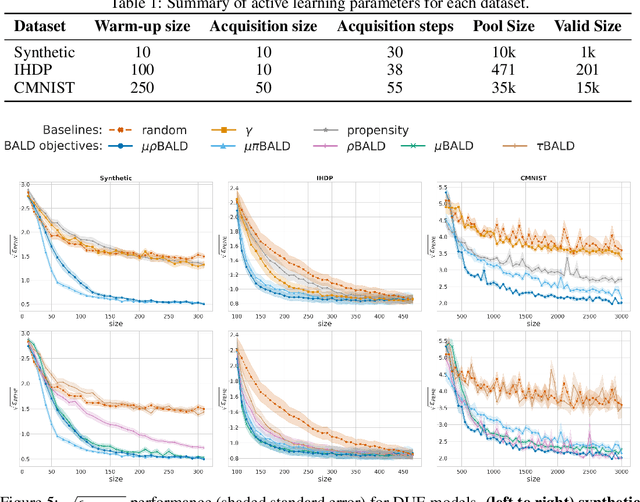
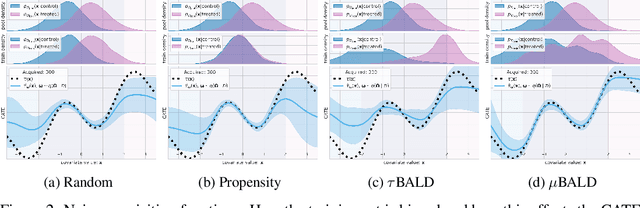

Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical, or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations. However, when measuring individual outcomes is costly, as is the case of a tumor biopsy, a sample-efficient strategy for acquiring each result is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, existing methods bias training data acquisition towards regions of non-overlapping support between the treated and control populations. These are not sample-efficient because the treatment effect is not identifiable in such regions. We introduce causal, Bayesian acquisition functions grounded in information theory that bias data acquisition towards regions with overlapping support to maximize sample efficiency for learning personalized treatment effects. We demonstrate the performance of the proposed acquisition strategies on synthetic and semi-synthetic datasets IHDP and CMNIST and their extensions, which aim to simulate common dataset biases and pathologies.
Using Non-Linear Causal Models to Study Aerosol-Cloud Interactions in the Southeast Pacific
Nov 03, 2021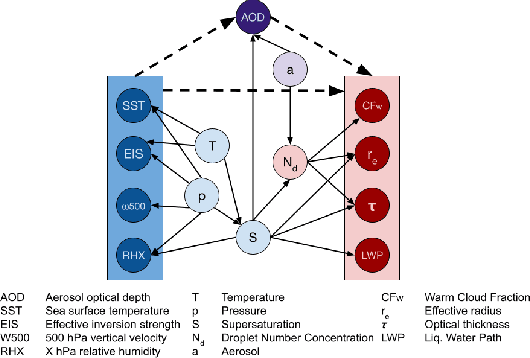

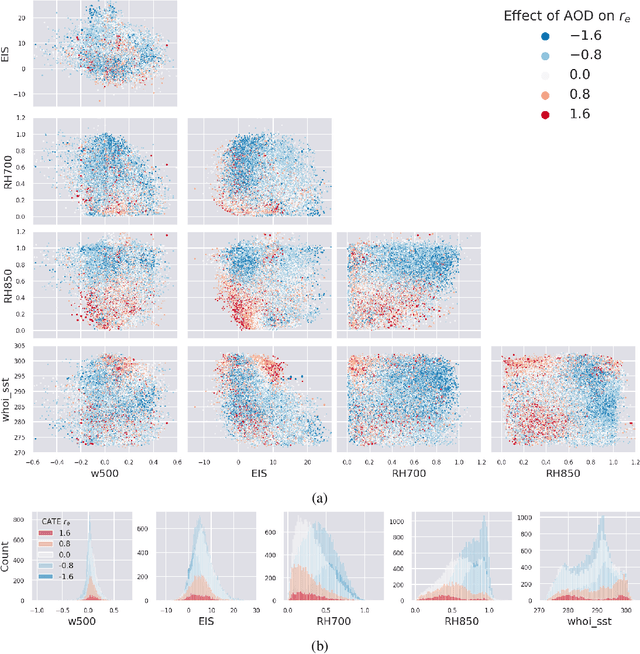
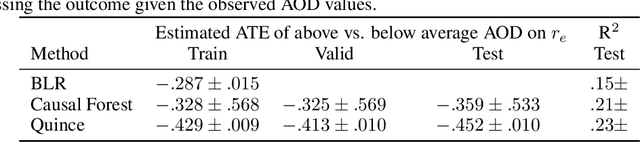
Aerosol-cloud interactions include a myriad of effects that all begin when aerosol enters a cloud and acts as cloud condensation nuclei (CCN). An increase in CCN results in a decrease in the mean cloud droplet size (r$_{e}$). The smaller droplet size leads to brighter, more expansive, and longer lasting clouds that reflect more incoming sunlight, thus cooling the earth. Globally, aerosol-cloud interactions cool the Earth, however the strength of the effect is heterogeneous over different meteorological regimes. Understanding how aerosol-cloud interactions evolve as a function of the local environment can help us better understand sources of error in our Earth system models, which currently fail to reproduce the observed relationships. In this work we use recent non-linear, causal machine learning methods to study the heterogeneous effects of aerosols on cloud droplet radius.
Deep Deterministic Uncertainty for Semantic Segmentation
Oct 29, 2021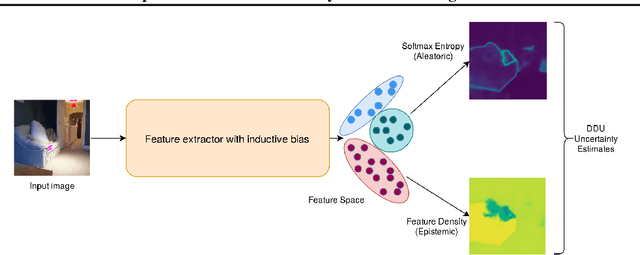
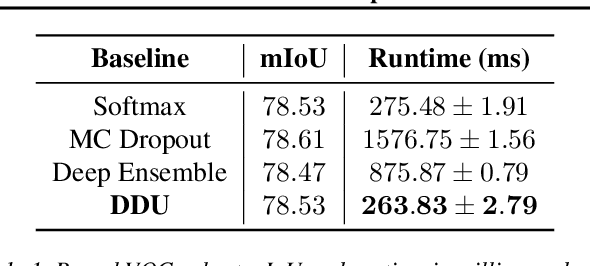
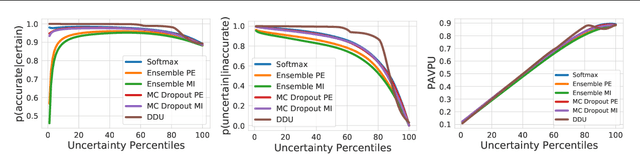
We extend Deep Deterministic Uncertainty (DDU), a method for uncertainty estimation using feature space densities, to semantic segmentation. DDU enables quantifying and disentangling epistemic and aleatoric uncertainty in a single forward pass through the model. We study the similarity of feature representations of pixels at different locations for the same class and conclude that it is feasible to apply DDU location independently, which leads to a significant reduction in memory consumption compared to pixel dependent DDU. Using the DeepLab-v3+ architecture on Pascal VOC 2012, we show that DDU improves upon MC Dropout and Deep Ensembles while being significantly faster to compute.
GeneDisco: A Benchmark for Experimental Design in Drug Discovery
Oct 22, 2021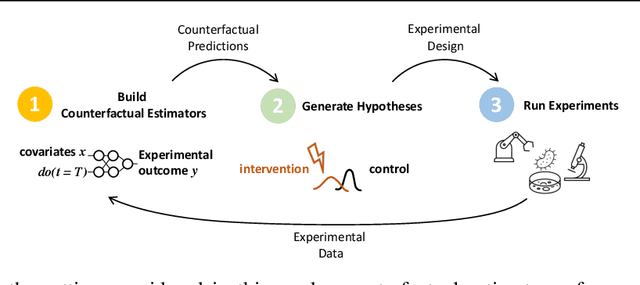
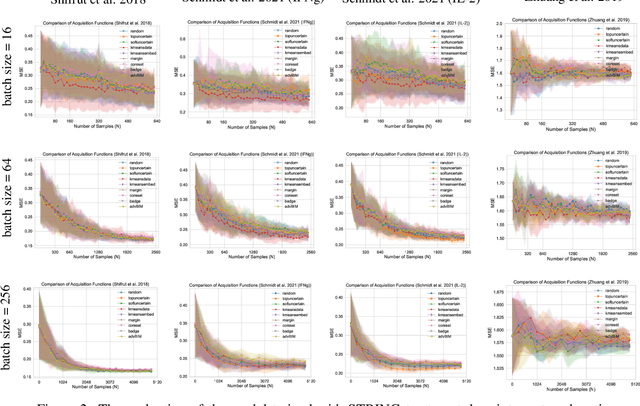
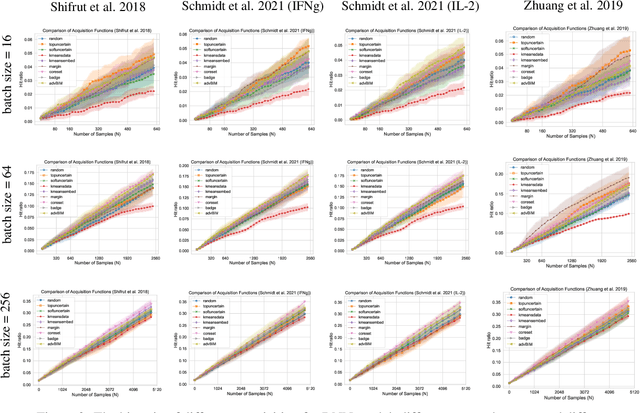
In vitro cellular experimentation with genetic interventions, using for example CRISPR technologies, is an essential step in early-stage drug discovery and target validation that serves to assess initial hypotheses about causal associations between biological mechanisms and disease pathologies. With billions of potential hypotheses to test, the experimental design space for in vitro genetic experiments is extremely vast, and the available experimental capacity - even at the largest research institutions in the world - pales in relation to the size of this biological hypothesis space. Machine learning methods, such as active and reinforcement learning, could aid in optimally exploring the vast biological space by integrating prior knowledge from various information sources as well as extrapolating to yet unexplored areas of the experimental design space based on available data. However, there exist no standardised benchmarks and data sets for this challenging task and little research has been conducted in this area to date. Here, we introduce GeneDisco, a benchmark suite for evaluating active learning algorithms for experimental design in drug discovery. GeneDisco contains a curated set of multiple publicly available experimental data sets as well as open-source implementations of state-of-the-art active learning policies for experimental design and exploration.
Quantifying Uncertainty for Machine Learning Based Diagnostic
Jul 29, 2021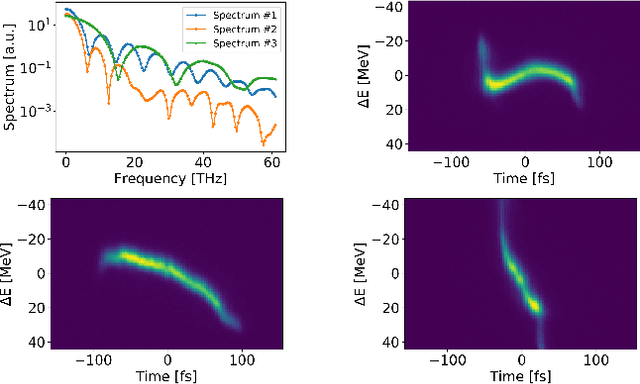
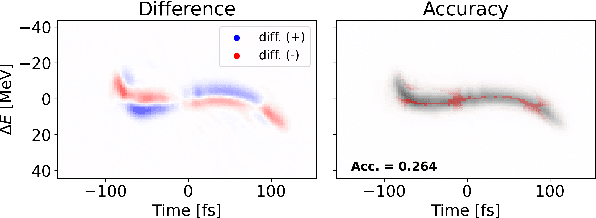
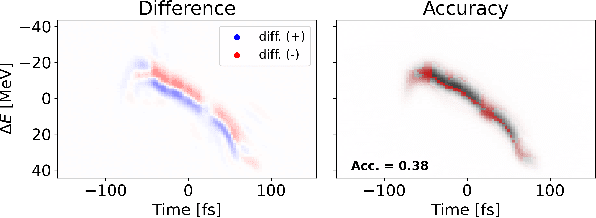
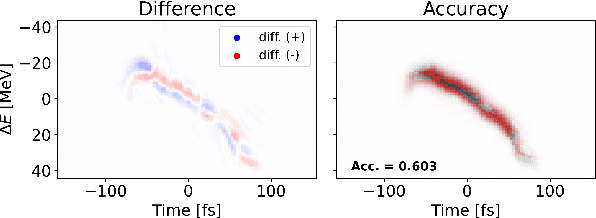
Virtual Diagnostic (VD) is a deep learning tool that can be used to predict a diagnostic output. VDs are especially useful in systems where measuring the output is invasive, limited, costly or runs the risk of damaging the output. Given a prediction, it is necessary to relay how reliable that prediction is. This is known as 'uncertainty quantification' of a prediction. In this paper, we use ensemble methods and quantile regression neural networks to explore different ways of creating and analyzing prediction's uncertainty on experimental data from the Linac Coherent Light Source at SLAC. We aim to accurately and confidently predict the current profile or longitudinal phase space images of the electron beam. The ability to make informed decisions under uncertainty is crucial for reliable deployment of deep learning tools on safety-critical systems as particle accelerators.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021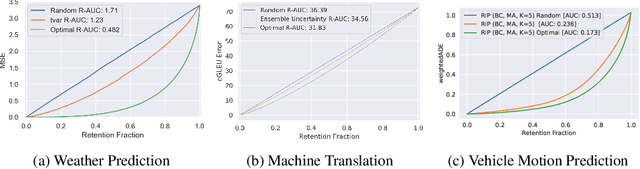
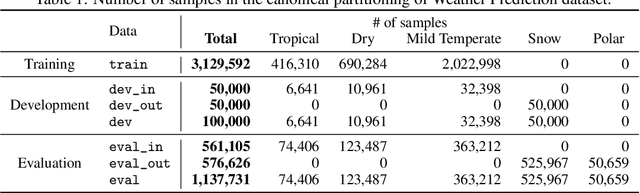
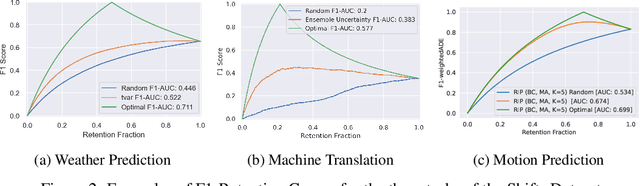
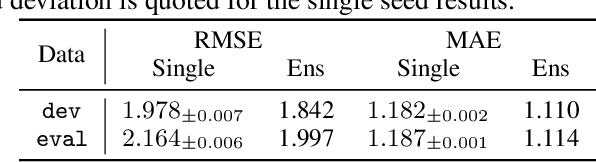
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021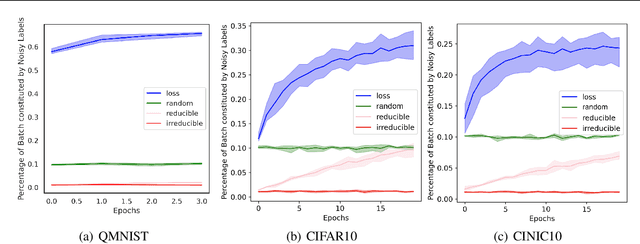
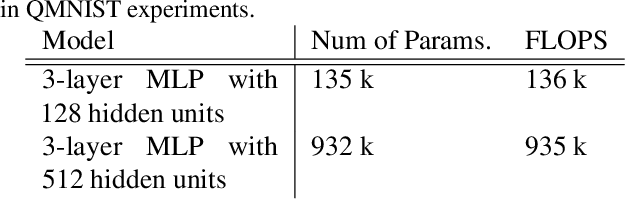
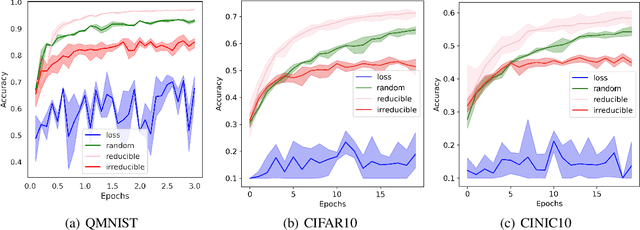
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.