 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIFT: Sliding Window Reconstruction for Few-Shot Training-Free Generated Video Attribution
Mar 09, 2026Recent advancements in video generation technologies have been significant, resulting in their widespread application across multiple domains. However, concerns have been mounting over the potential misuse of generated content. Tracing the origin of generated videos has become crucial to mitigate potential misuse and identify responsible parties. Existing video attribution methods require additional operations or the training of source attribution models, which may degrade video quality or necessitate large amounts of training samples. To address these challenges, we define for the first time the "few-shot training-free generated video attribution" task and propose SWIFT, which is tightly integrated with the temporal characteristics of the video. By leveraging the "Pixel Frames(many) to Latent Frame(one)" temporal mapping within each video chunk, SWIFT applies a fixed-length sliding window to perform two distinct reconstructions: normal and corrupted. The variation in the losses between two reconstructions is then used as an attribution signal. We conducted an extensive evaluation of five state-of-the-art (SOTA) video generation models. Experimental results show that SWIFT achieves over 90% average attribution accuracy with merely 20 video samples across all models and even enables zero-shot attribution for HunyuanVideo, EasyAnimate, and Wan2.2. Our source code is available at https://github.com/wangchao0708/SWIFT.
Modification and Generated-Text Detection: Achieving Dual Detection Capabilities for the Outputs of LLM by Watermark
Feb 12, 2025



The development of large language models (LLMs) has raised concerns about potential misuse. One practical solution is to embed a watermark in the text, allowing ownership verification through watermark extraction. Existing methods primarily focus on defending against modification attacks, often neglecting other spoofing attacks. For example, attackers can alter the watermarked text to produce harmful content without compromising the presence of the watermark, which could lead to false attribution of this malicious content to the LLM. This situation poses a serious threat to the LLMs service providers and highlights the significance of achieving modification detection and generated-text detection simultaneously. Therefore, we propose a technique to detect modifications in text for unbiased watermark which is sensitive to modification. We introduce a new metric called ``discarded tokens", which measures the number of tokens not included in watermark detection. When a modification occurs, this metric changes and can serve as evidence of the modification. Additionally, we improve the watermark detection process and introduce a novel method for unbiased watermark. Our experiments demonstrate that we can achieve effective dual detection capabilities: modification detection and generated-text detection by watermark.
Image Steganography based on Style Transfer
Mar 09, 2022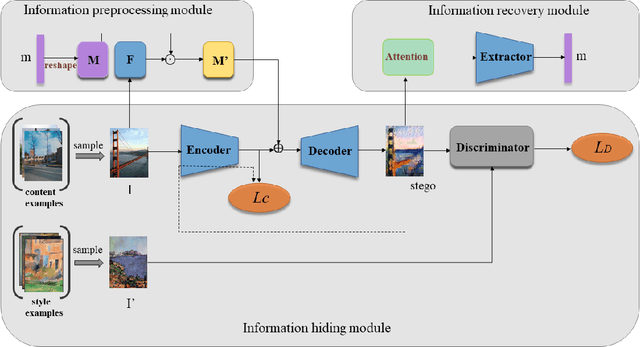
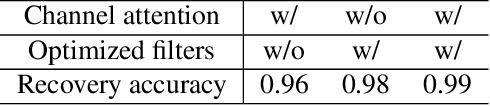
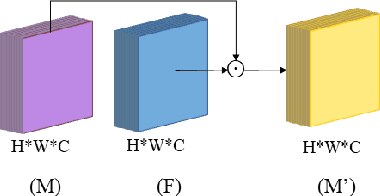
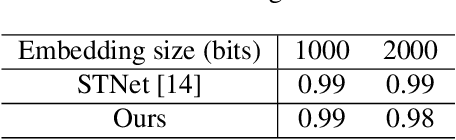
Image steganography is the art and science of using images as cover for covert communications. With the development of neural networks, traditional image steganography is more likely to be detected by deep learning-based steganalysis. To improve upon this, we propose image steganography network based on style transfer, and the embedding of secret messages can be disguised as image stylization. We embed secret information while transforming the content image style. In latent space, the secret information is integrated into the latent representation of the cover image to generate the stego images, which are indistinguishable from normal stylized images. It is an end-to-end unsupervised model without pre-training. Extensive experiments on the benchmark dataset demonstrate the reliability, quality and security of stego images generated by our steganographic network.