 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Networks with Adaptive Regularization
Jul 14, 2019



Feed-forward neural networks can be understood as a combination of an intermediate representation and a linear hypothesis. While most previous works aim to diversify the representations, we explore the complementary direction by performing an adaptive and data-dependent regularization motivated by the empirical Bayes method. Specifically, we propose to construct a matrix-variate normal prior (on weights) whose covariance matrix has a Kronecker product structure. This structure is designed to capture the correlations in neurons through backpropagation. Under the assumption of this Kronecker factorization, the prior encourages neurons to borrow statistical strength from one another. Hence, it leads to an adaptive and data-dependent regularization when training networks on small datasets. To optimize the model, we present an efficient block coordinate descent algorithm with analytical solutions. Empirically, we demonstrate that the proposed method helps networks converge to local optima with smaller stable ranks and spectral norms. These properties suggest better generalizations and we present empirical results to support this expectation. We also verify the effectiveness of the approach on multiclass classification and multitask regression problems with various network structures.
Learning Representations from Imperfect Time Series Data via Tensor Rank Regularization
Jul 01, 2019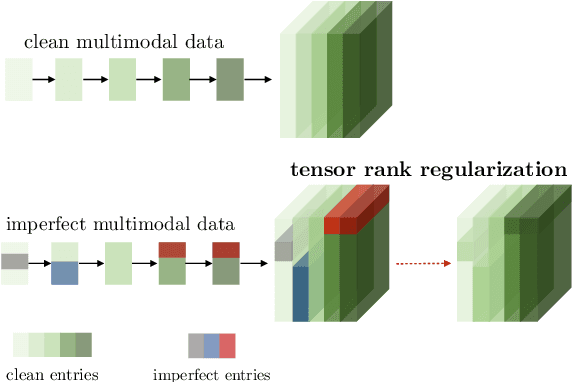
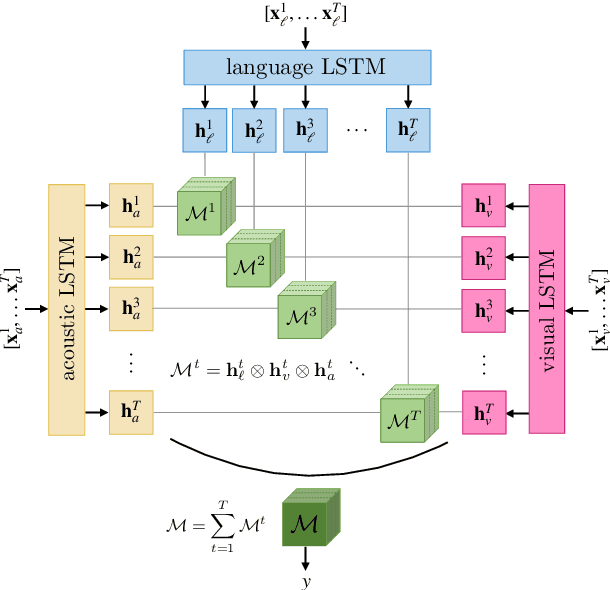
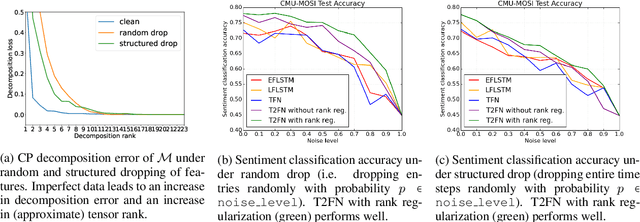
There has been an increased interest in multimodal language processing including multimodal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often imperfect as a result of imperfect modalities, missing entries or noise corruption. To address these concerns, we present a regularization method based on tensor rank minimization. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor representations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfection.
Multimodal Transformer for Unaligned Multimodal Language Sequences
Jun 01, 2019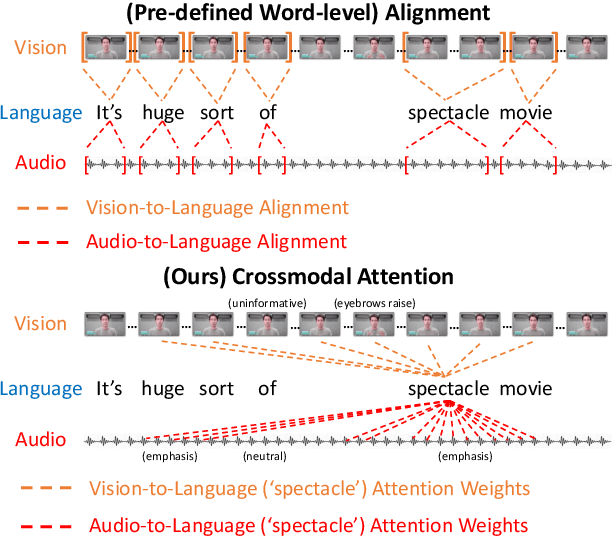
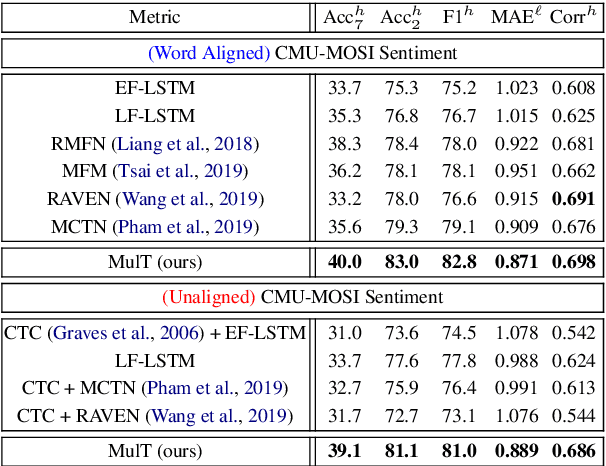
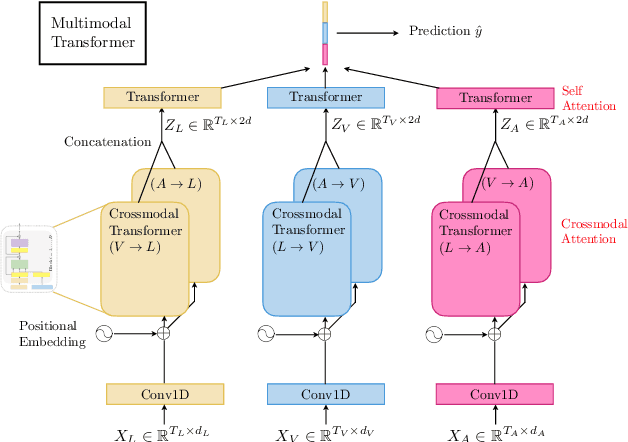
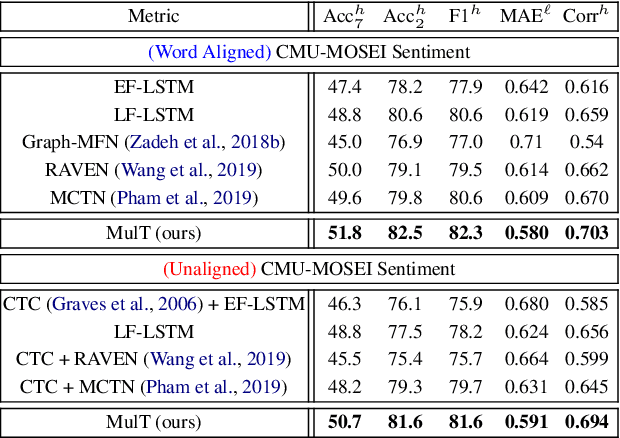
Human language is often multimodal, which comprehends a mixture of natural language, facial gestures, and acoustic behaviors. However, two major challenges in modeling such multimodal human language time-series data exist: 1) inherent data non-alignment due to variable sampling rates for the sequences from each modality; and 2) long-range dependencies between elements across modalities. In this paper, we introduce the Multimodal Transformer (MulT) to generically address the above issues in an end-to-end manner without explicitly aligning the data. At the heart of our model is the directional pairwise crossmodal attention, which attends to interactions between multimodal sequences across distinct time steps and latently adapt streams from one modality to another. Comprehensive experiments on both aligned and non-aligned multimodal time-series show that our model outperforms state-of-the-art methods by a large margin. In addition, empirical analysis suggests that correlated crossmodal signals are able to be captured by the proposed crossmodal attention mechanism in MulT.
Strong and Simple Baselines for Multimodal Utterance Embeddings
May 14, 2019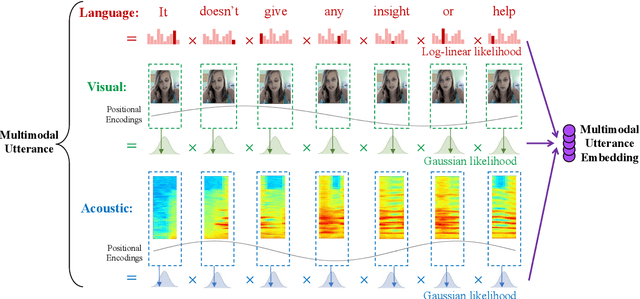
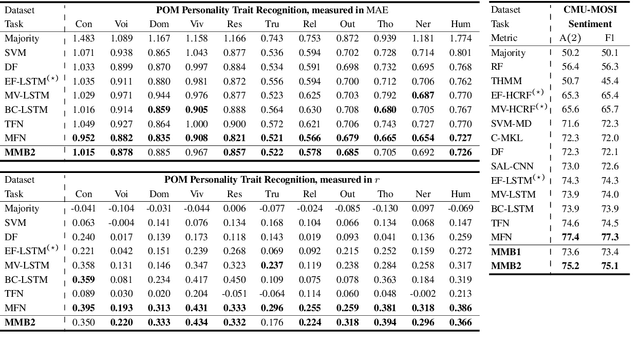
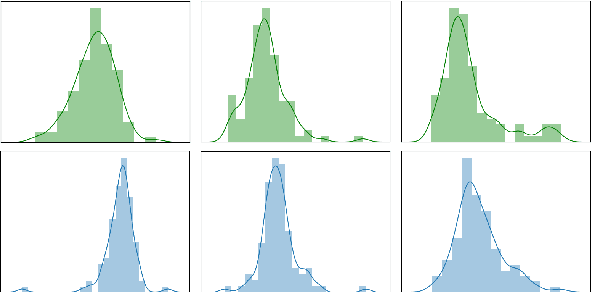
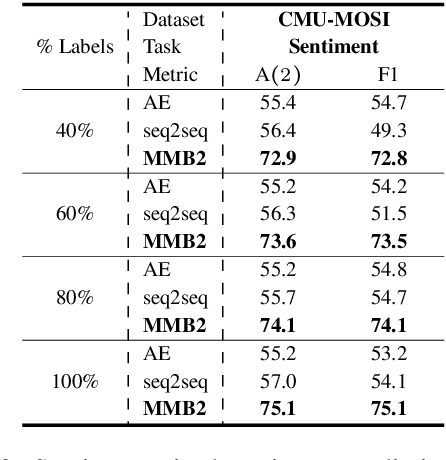
Human language is a rich multimodal signal consisting of spoken words, facial expressions, body gestures, and vocal intonations. Learning representations for these spoken utterances is a complex research problem due to the presence of multiple heterogeneous sources of information. Recent advances in multimodal learning have followed the general trend of building more complex models that utilize various attention, memory and recurrent components. In this paper, we propose two simple but strong baselines to learn embeddings of multimodal utterances. The first baseline assumes a conditional factorization of the utterance into unimodal factors. Each unimodal factor is modeled using the simple form of a likelihood function obtained via a linear transformation of the embedding. We show that the optimal embedding can be derived in closed form by taking a weighted average of the unimodal features. In order to capture richer representations, our second baseline extends the first by factorizing into unimodal, bimodal, and trimodal factors, while retaining simplicity and efficiency during learning and inference. From a set of experiments across two tasks, we show strong performance on both supervised and semi-supervised multimodal prediction, as well as significant (10 times) speedups over neural models during inference. Overall, we believe that our strong baseline models offer new benchmarking options for future research in multimodal learning.
Video Relationship Reasoning using Gated Spatio-Temporal Energy Graph
Mar 27, 2019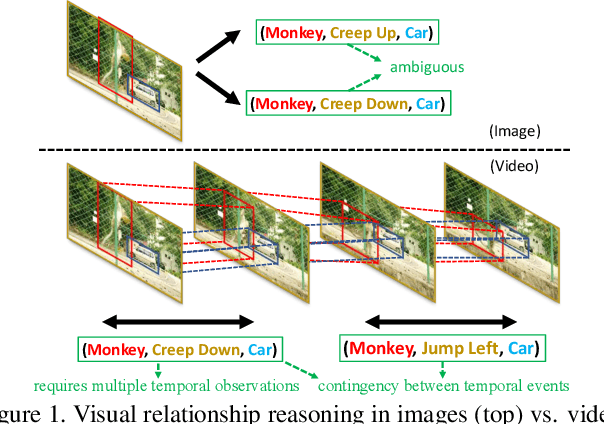
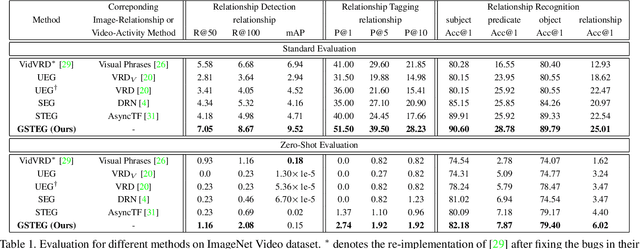
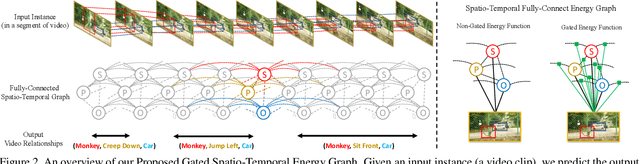
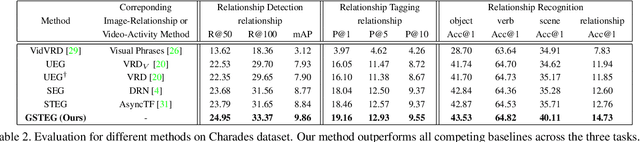
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship 'man, open, door' involves a complex relation 'open' between concrete entities 'man, door'. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., 'man, lift up, box' vs. 'man, put down, box'), as well as relationships that are often correlated through time (e.g., 'woman, pay, money' followed by 'woman, buy, coffee'). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.
Selecting the Best in GANs Family: a Post Selection Inference Framework
Jun 23, 2018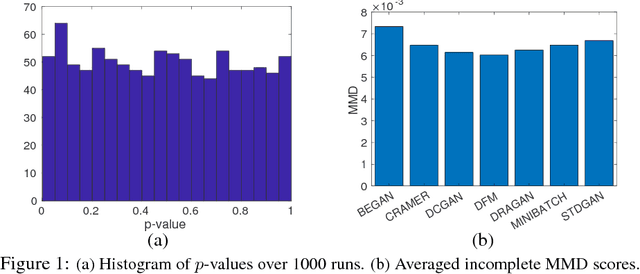
"Which Generative Adversarial Networks (GANs) generates the most plausible images?" has been a frequently asked question among researchers. To address this problem, we first propose an \emph{incomplete} U-statistics estimate of maximum mean discrepancy $\mathrm{MMD}_{inc}$ to measure the distribution discrepancy between generated and real images. $\mathrm{MMD}_{inc}$ enjoys the advantages of asymptotic normality, computation efficiency, and model agnosticity. We then propose a GANs analysis framework to select and test the "best" member in GANs family using the Post Selection Inference (PSI) with $\mathrm{MMD}_{inc}$. In the experiments, we adopt the proposed framework on 7 GANs variants and compare their $\mathrm{MMD}_{inc}$ scores.
Learning Factorized Multimodal Representations
Jun 16, 2018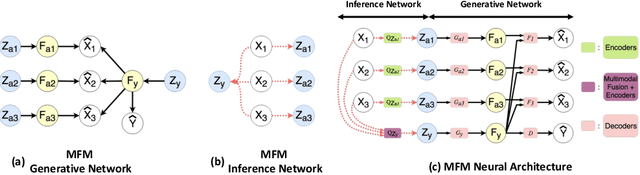
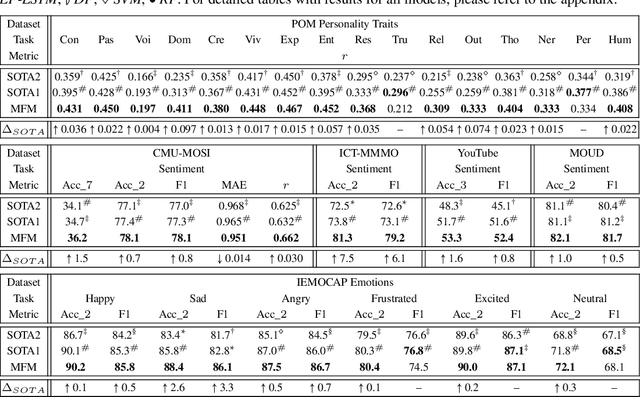
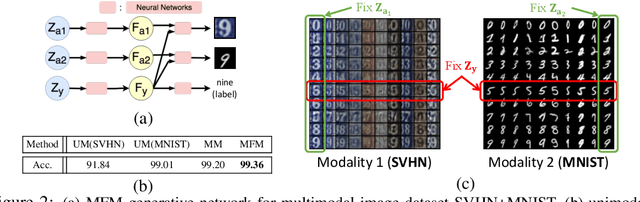
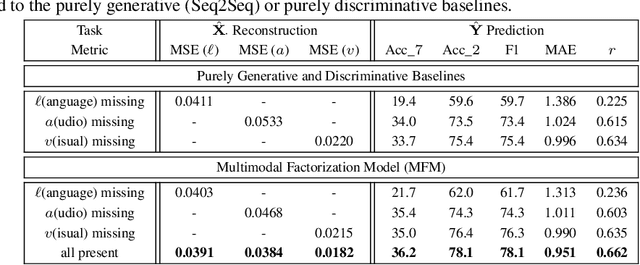
Learning representations of multimodal data is a fundamentally complex research problem due to the presence of multiple sources of information. To address the complexities of multimodal data, we argue that suitable representation learning models should: 1) factorize representations according to independent factors of variation in the data, capture important features for both 2) discriminative and 3) generative tasks, and 4) couple both modality-specific and multimodal information. To encapsulate all these properties, we propose the Multimodal Factorization Model (MFM) that factorizes multimodal representations into two sets of independent factors: multimodal discriminative factors and modality-specific generative factors. Multimodal discriminative factors are shared across all modalities and contain joint multimodal features required for discriminative tasks such as predicting sentiment. Modality-specific generative factors are unique for each modality and contain the information required for generating data. Our experimental results show that our model is able to learn meaningful multimodal representations and achieve state-of-the-art or competitive performance on five multimodal datasets. Our model also demonstrates flexible generative capabilities by conditioning on the independent factors. We further interpret our factorized representations to understand the interactions that influence multimodal learning.
Post Selection Inference with Incomplete Maximum Mean Discrepancy Estimator
Feb 17, 2018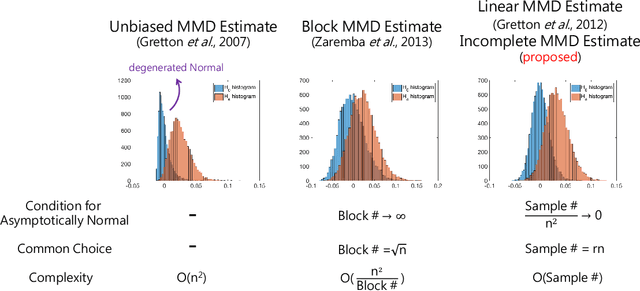

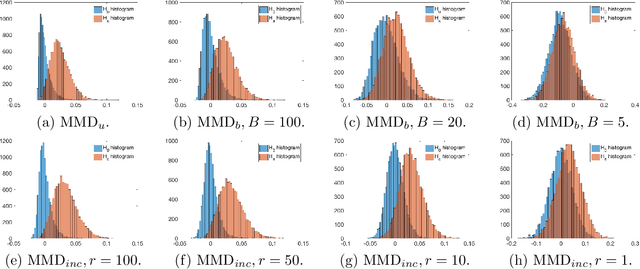
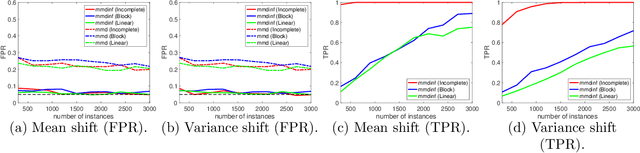
Measuring divergence between two distributions is essential in machine learning and statistics and has various applications including binary classification, change point detection, and two-sample test. Furthermore, in the era of big data, designing divergence measure that is interpretable and can handle high-dimensional and complex data becomes extremely important. In the paper, we propose a post selection inference (PSI) framework for divergence measure, which can select a set of statistically significant features that discriminate two distributions. Specifically, we employ an additive variant of maximum mean discrepancy (MMD) for features and introduce a general hypothesis test for PSI. A novel MMD estimator using the incomplete U-statistics, which has an asymptotically Normal distribution (under mild assumptions) and gives high detection power in PSI, is also proposed and analyzed theoretically. Through synthetic and real-world feature selection experiments, we show that the proposed framework can successfully detect statistically significant features. Last, we propose a sample selection framework for analyzing different members in the Generative Adversarial Networks (GANs) family.
"Dependency Bottleneck" in Auto-encoding Architectures: an Empirical Study
Feb 15, 2018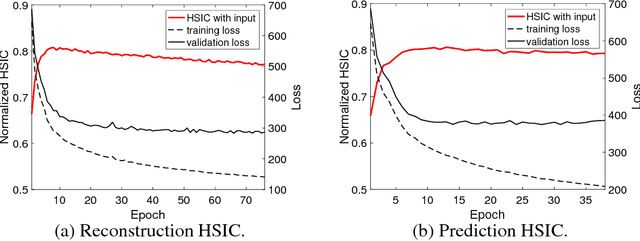
Recent works investigated the generalization properties in deep neural networks (DNNs) by studying the Information Bottleneck in DNNs. However, the mea- surement of the mutual information (MI) is often inaccurate due to the density estimation. To address this issue, we propose to measure the dependency instead of MI between layers in DNNs. Specifically, we propose to use Hilbert-Schmidt Independence Criterion (HSIC) as the dependency measure, which can measure the dependence of two random variables without estimating probability densities. Moreover, HSIC is a special case of the Squared-loss Mutual Information (SMI). In the experiment, we empirically evaluate the generalization property using HSIC in both the reconstruction and prediction auto-encoding (AE) architectures.
Discovering Order in Unordered Datasets: Generative Markov Networks
Feb 15, 2018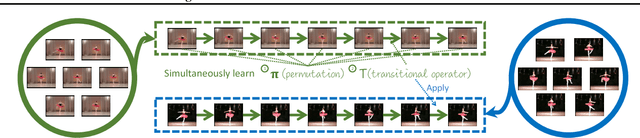
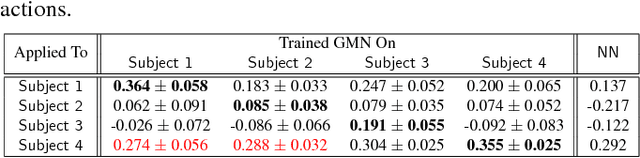

The assumption that data samples are independently identically distributed is the backbone of many learning algorithms. Nevertheless, datasets often exhibit rich structures in practice, and we argue that there exist some unknown orders within the data instances. Aiming to find such orders, we introduce a novel Generative Markov Network (GMN) which we use to extract the order of data instances automatically. Specifically, we assume that the instances are sampled from a Markov chain. Our goal is to learn the transitional operator of the chain as well as the generation order by maximizing the generation probability under all possible data permutations. One of our key ideas is to use neural networks as a soft lookup table for approximating the possibly huge, but discrete transition matrix. This strategy allows us to amortize the space complexity with a single model and make the transitional operator generalizable to unseen instances. To ensure the learned Markov chain is ergodic, we propose a greedy batch-wise permutation scheme that allows fast training. Empirically, we evaluate the learned Markov chain by showing that GMNs are able to discover orders among data instances and also perform comparably well to state-of-the-art methods on the one-shot recognition benchmark task.