 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanMove: Next Location Recommendation via Self-Attention Network
Dec 15, 2021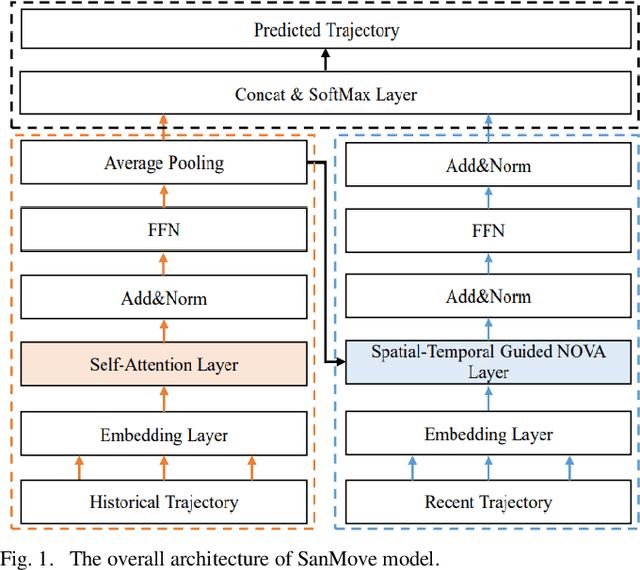
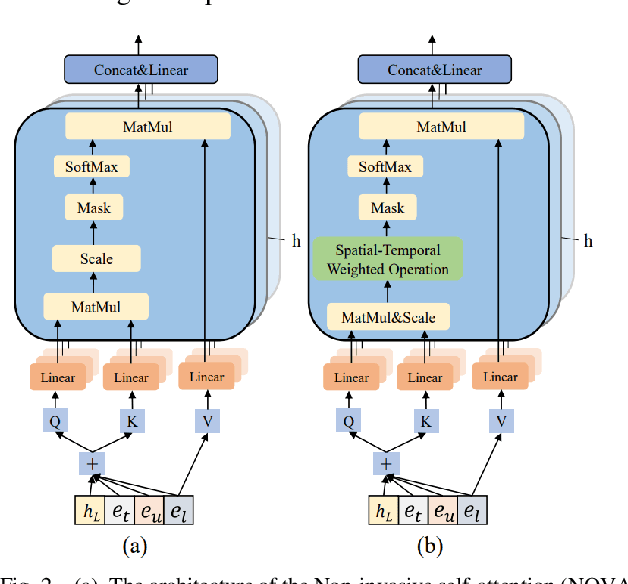
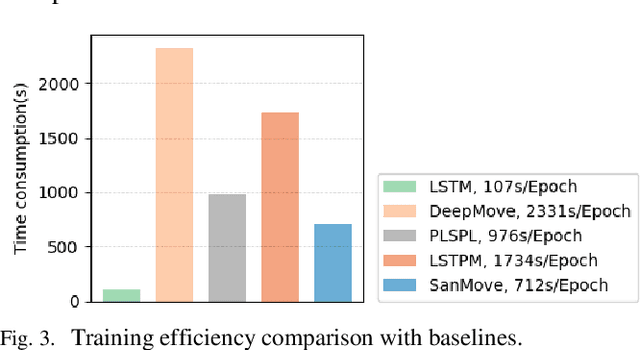
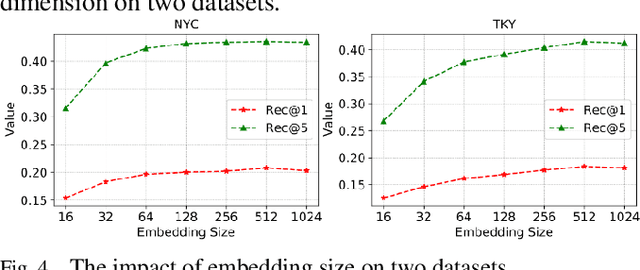
Currently, next location recommendation plays a vital role in location-based social network applications and services. Although many methods have been proposed to solve this problem, three important challenges have not been well addressed so far: (1) most existing methods are based on recurrent network, which is time-consuming to train long sequences due to not allowing for full parallelism; (2) personalized preferences generally are not considered reasonably; (3) existing methods rarely systematically studied how to efficiently utilize various auxiliary information (e.g., user ID and timestamp) in trajectory data and the spatio-temporal relations among non-consecutive locations. To address the above challenges, we propose a novel method named SanMove, a self-attention network based model, to predict the next location via capturing the long- and short-term mobility patterns of users. Specifically, SanMove introduces a long-term preference learning module, and it uses a self-attention module to capture the users long-term mobility pattern which can represent personalized location preferences of users. Meanwhile, SanMove uses a spatial-temporal guided non-invasive self-attention (STNOVA) to exploit auxiliary information to learn short-term preferences. We evaluate SanMove with two real-world datasets, and demonstrate SanMove is not only faster than the state-of-the-art RNN-based predict model but also outperforms the baselines for next location prediction.
PG$^2$Net: Personalized and Group Preferences Guided Network for Next Place Prediction
Oct 15, 2021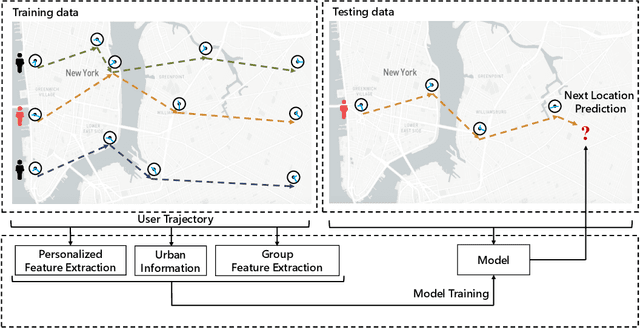
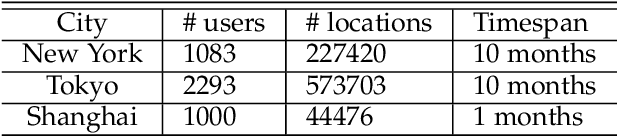
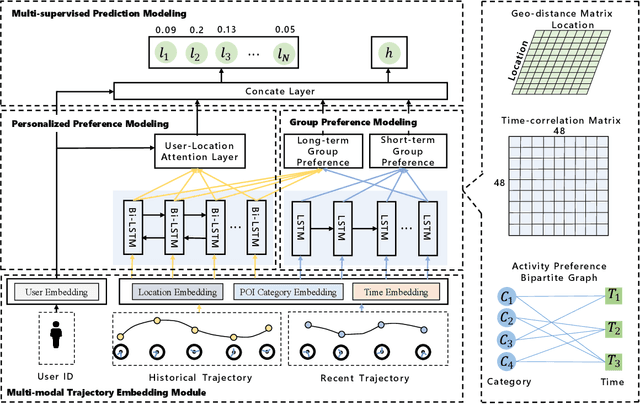
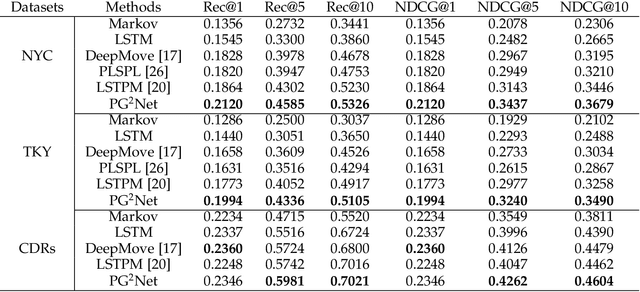
Predicting the next place to visit is a key in human mobility behavior modeling, which plays a significant role in various fields, such as epidemic control, urban planning, traffic management, and travel recommendation. To achieve this, one typical solution is designing modules based on RNN to capture their preferences to various locations. Although these RNN-based methods can effectively learn individual's hidden personalized preferences to her visited places, the interactions among users can only be weakly learned through the representations of locations. Targeting this, we propose an end-to-end framework named personalized and group preference guided network (PG$^2$Net), considering the users' preferences to various places at both individual and collective levels. Specifically, PG$^2$Net concatenates Bi-LSTM and attention mechanism to capture each user's long-term mobility tendency. To learn population's group preferences, we utilize spatial and temporal information of the visitations to construct a spatio-temporal dependency module. We adopt a graph embedding method to map users' trajectory into a hidden space, capturing their sequential relation. In addition, we devise an auxiliary loss to learn the vectorial representation of her next location. Experiment results on two Foursquare check-in datasets and one mobile phone dataset indicate the advantages of our model compared to the state-of-the-art baselines. Source codes are available at https://github.com/urbanmobility/PG2Net.
Explaining the Attention Mechanism of End-to-End Speech Recognition Using Decision Trees
Oct 08, 2021
The attention mechanism has largely improved the performance of end-to-end speech recognition systems. However, the underlying behaviours of attention is not yet clearer. In this study, we use decision trees to explain how the attention mechanism impact itself in speech recognition. The results indicate that attention levels are largely impacted by their previous states rather than the encoder and decoder patterns. Additionally, the default attention mechanism seems to put more weights on closer states, but behaves poorly on modelling long-term dependencies of attention states.
Enhancing Unsupervised Anomaly Detection with Score-Guided Network
Sep 10, 2021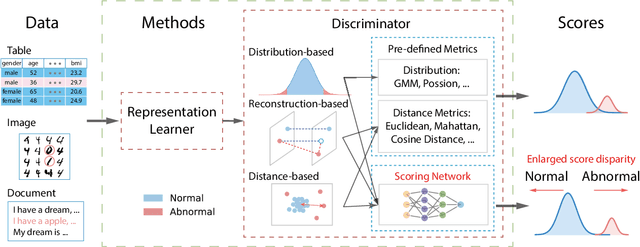
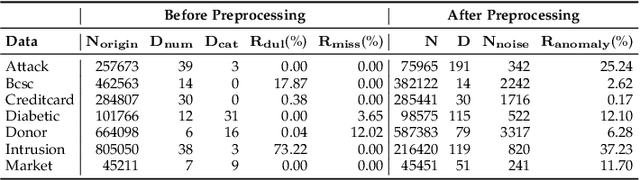
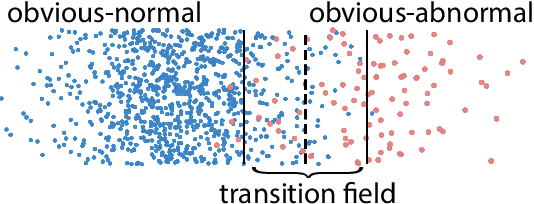

Anomaly detection plays a crucial role in various real-world applications, including healthcare and finance systems. Owing to the limited number of anomaly labels in these complex systems, unsupervised anomaly detection methods have attracted great attention in recent years. Two major challenges faced by the existing unsupervised methods are: (i) distinguishing between normal and abnormal data in the transition field, where normal and abnormal data are highly mixed together; (ii) defining an effective metric to maximize the gap between normal and abnormal data in a hypothesis space, which is built by a representation learner. To that end, this work proposes a novel scoring network with a score-guided regularization to learn and enlarge the anomaly score disparities between normal and abnormal data. With such score-guided strategy, the representation learner can gradually learn more informative representation during the model training stage, especially for the samples in the transition field. We next propose a score-guided autoencoder (SG-AE), incorporating the scoring network into an autoencoder framework for anomaly detection, as well as other three state-of-the-art models, to further demonstrate the effectiveness and transferability of the design. Extensive experiments on both synthetic and real-world datasets demonstrate the state-of-the-art performance of these score-guided models (SGMs).
An Empirical Study on End-to-End Singing Voice Synthesis with Encoder-Decoder Architectures
Aug 06, 2021
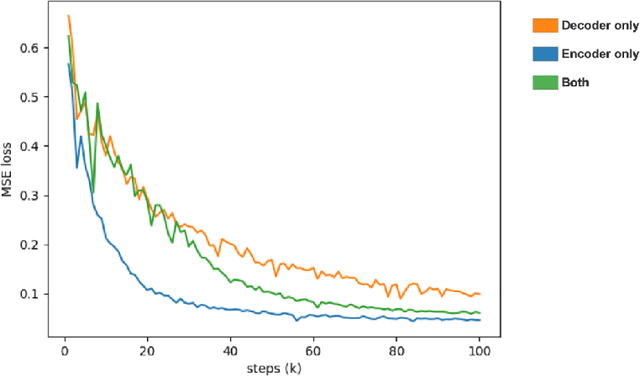
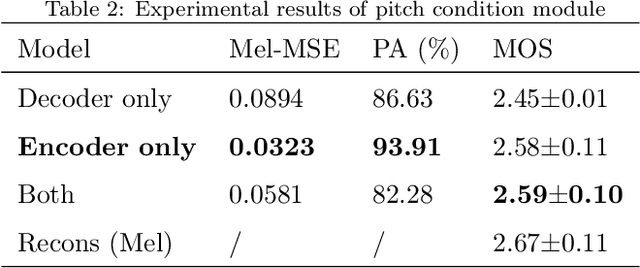
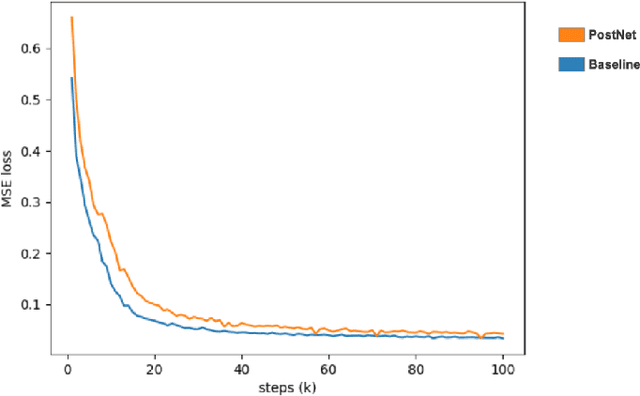
With the rapid development of neural network architectures and speech processing models, singing voice synthesis with neural networks is becoming the cutting-edge technique of digital music production. In this work, in order to explore how to improve the quality and efficiency of singing voice synthesis, in this work, we use encoder-decoder neural models and a number of vocoders to achieve singing voice synthesis. We conduct experiments to demonstrate that the models can be trained using voice data with pitch information, lyrics and beat information, and the trained models can produce smooth, clear and natural singing voice that is close to real human voice. As the models work in the end-to-end manner, they allow users who are not domain experts to directly produce singing voice by arranging pitches, lyrics and beats.
Speech Enhancement using Separable Polling Attention and Global Layer Normalization followed with PReLU
May 06, 2021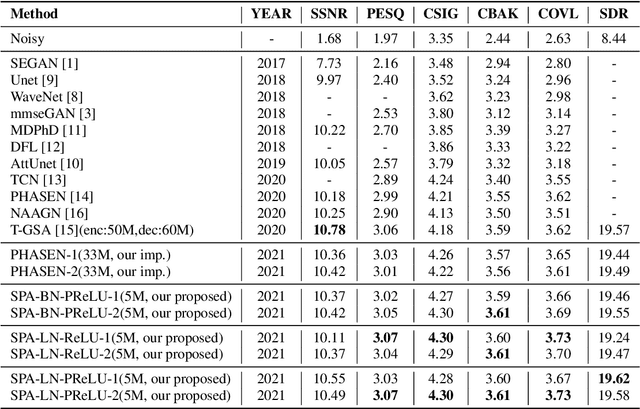
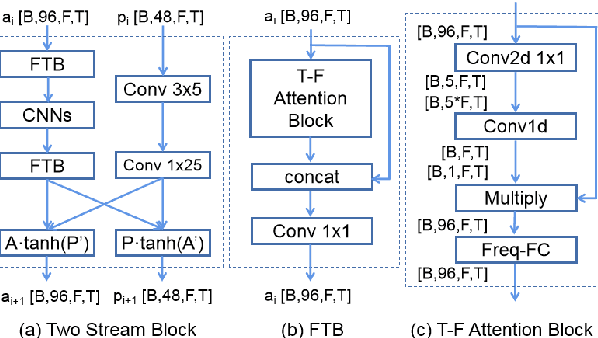
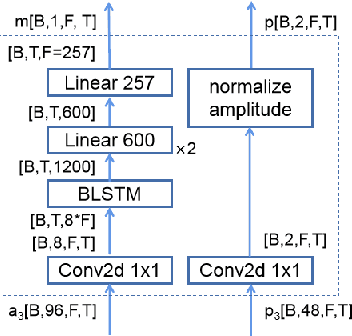

Single channel speech enhancement is a challenging task in speech community. Recently, various neural networks based methods have been applied to speech enhancement. Among these models, PHASEN and T-GSA achieve state-of-the-art performances on the publicly opened VoiceBank+DEMAND corpus. Both of the models reach the COVL score of 3.62. PHASEN achieves the highest CSIG score of 4.21 while T-GSA gets the highest PESQ score of 3.06. However, both of these two models are very large. The contradiction between the model performance and the model size is hard to reconcile. In this paper, we introduce three kinds of techniques to shrink the PHASEN model and improve the performance. Firstly, seperable polling attention is proposed to replace the frequency transformation blocks in PHASEN. Secondly, global layer normalization followed with PReLU is used to replace batch normalization followed with ReLU. Finally, BLSTM in PHASEN is replaced with Conv2d operation and the phase stream is simplified. With all these modifications, the size of the PHASEN model is shrunk from 33M parameters to 5M parameters, while the performance on VoiceBank+DEMAND is improved to the CSIG score of 4.30, the PESQ score of 3.07 and the COVL score of 3.73.
Dynamically Mitigating Data Discrepancy with Balanced Focal Loss for Replay Attack Detection
Jun 25, 2020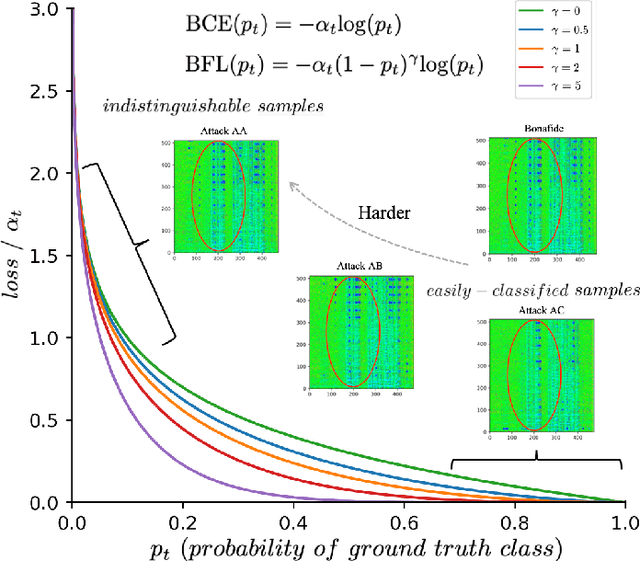
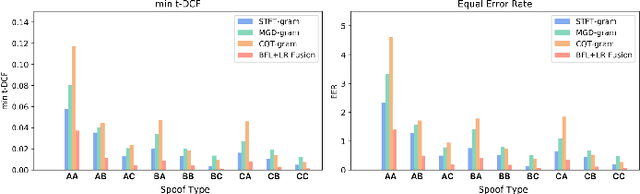
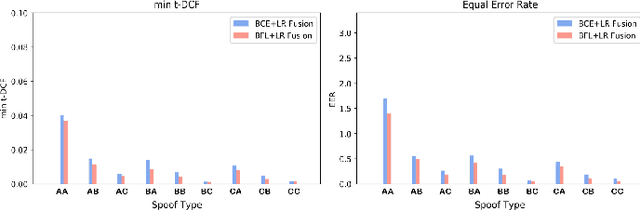
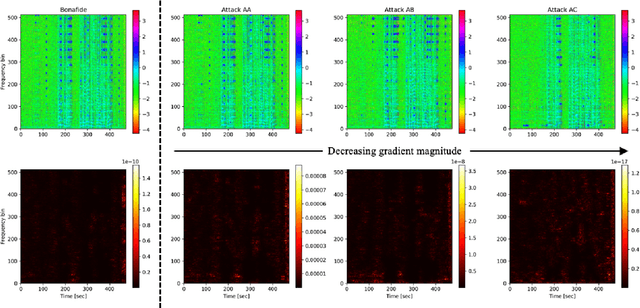
It becomes urgent to design effective anti-spoofing algorithms for vulnerable automatic speaker verification systems due to the advancement of high-quality playback devices. Current studies mainly treat anti-spoofing as a binary classification problem between bonafide and spoofed utterances, while lack of indistinguishable samples makes it difficult to train a robust spoofing detector. In this paper, we argue that for anti-spoofing, it needs more attention for indistinguishable samples over easily-classified ones in the modeling process, to make correct discrimination a top priority. Therefore, to mitigate the data discrepancy between training and inference, we propose to leverage a balanced focal loss function as the training objective to dynamically scale the loss based on the traits of the sample itself. Besides, in the experiments, we select three kinds of features that contain both magnitude-based and phase-based information to form complementary and informative features. Experimental results on the ASVspoof2019 dataset demonstrate the superiority of the proposed methods by comparison between our systems and top-performing ones. Systems trained with the balanced focal loss perform significantly better than conventional cross-entropy loss. With complementary features, our fusion system with only three kinds of features outperforms other systems containing five or more complex single models by 22.5% for min-tDCF and 7% for EER, achieving a min-tDCF and an EER of 0.0124 and 0.55% respectively. Furthermore, we present and discuss the evaluation results on real replay data apart from the simulated ASVspoof2019 data, indicating that research for anti-spoofing still has a long way to go.
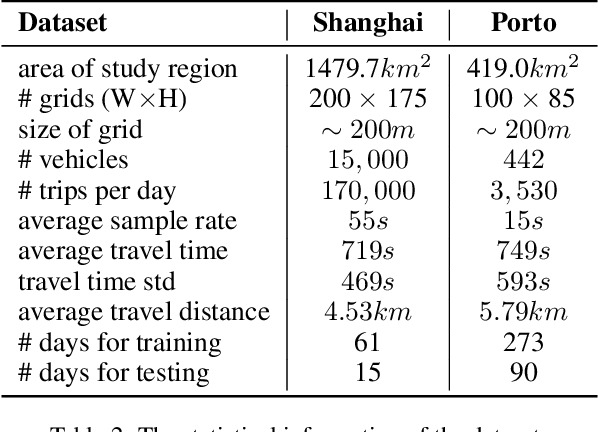
Travel Time Estimation without Road Networks: An Urban Morphological Layout Representation Approach
Jul 08, 2019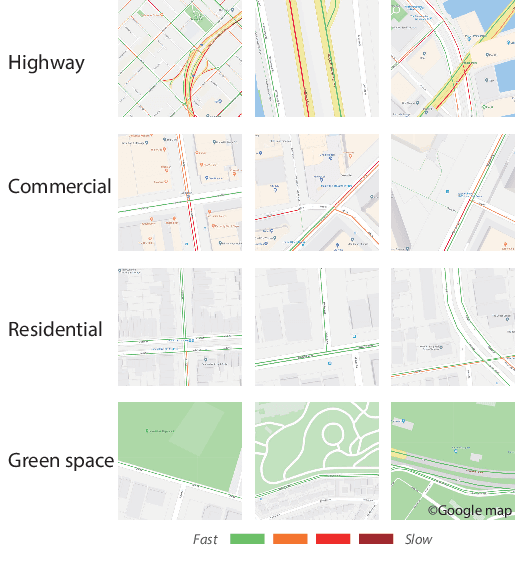
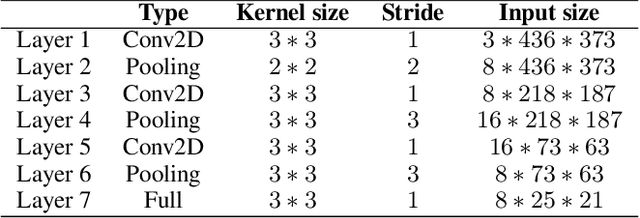
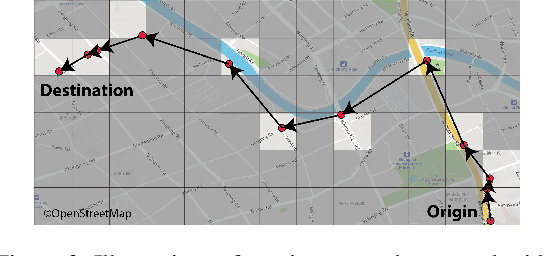
Travel time estimation is a crucial task for not only personal travel scheduling but also city planning. Previous methods focus on modeling toward road segments or sub-paths, then summing up for a final prediction, which have been recently replaced by deep neural models with end-to-end training. Usually, these methods are based on explicit feature representations, including spatio-temporal features, traffic states, etc. Here, we argue that the local traffic condition is closely tied up with the land-use and built environment, i.e., metro stations, arterial roads, intersections, commercial area, residential area, and etc, yet the relation is time-varying and too complicated to model explicitly and efficiently. Thus, this paper proposes an end-to-end multi-task deep neural model, named Deep Image to Time (DeepI2T), to learn the travel time mainly from the built environment images, a.k.a. the morphological layout images, and showoff the new state-of-the-art performance on real-world datasets in two cities. Moreover, our model is designed to tackle both path-aware and path-blind scenarios in the testing phase. This work opens up new opportunities of using the publicly available morphological layout images as considerable information in multiple geography-related smart city applications.
Trainable back-propagated functional transfer matrices
Oct 28, 2017
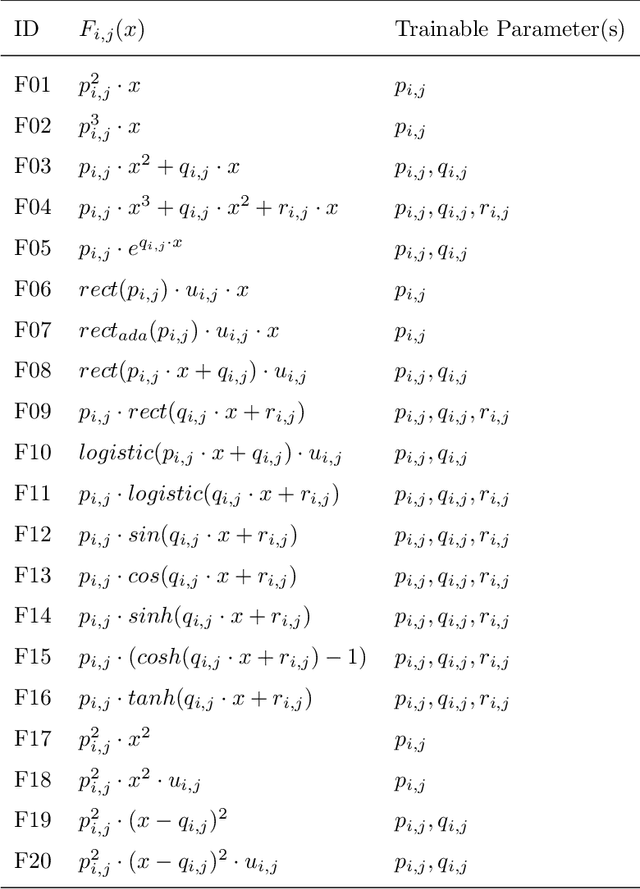
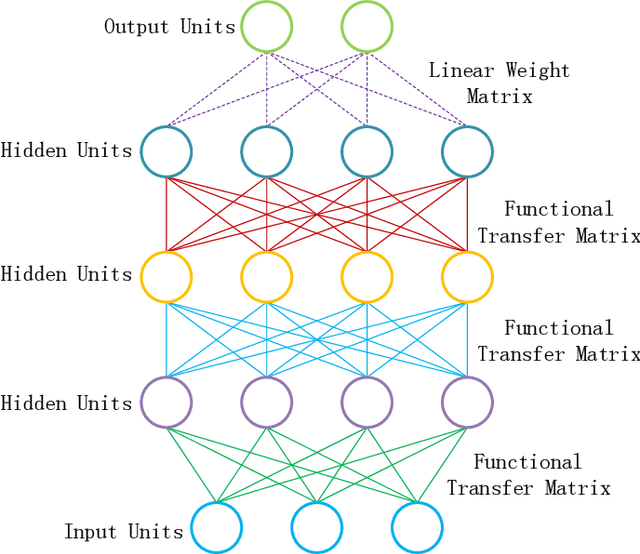

Connections between nodes of fully connected neural networks are usually represented by weight matrices. In this article, functional transfer matrices are introduced as alternatives to the weight matrices: Instead of using real weights, a functional transfer matrix uses real functions with trainable parameters to represent connections between nodes. Multiple functional transfer matrices are then stacked together with bias vectors and activations to form deep functional transfer neural networks. These neural networks can be trained within the framework of back-propagation, based on a revision of the delta rules and the error transmission rule for functional connections. In experiments, it is demonstrated that the revised rules can be used to train a range of functional connections: 20 different functions are applied to neural networks with up to 10 hidden layers, and most of them gain high test accuracies on the MNIST database. It is also demonstrated that a functional transfer matrix with a memory function can roughly memorise a non-cyclical sequence of 400 digits.
* 39 pages, 4 figures, submitted as a journal article
Learning of Human-like Algebraic Reasoning Using Deep Feedforward Neural Networks
Apr 25, 2017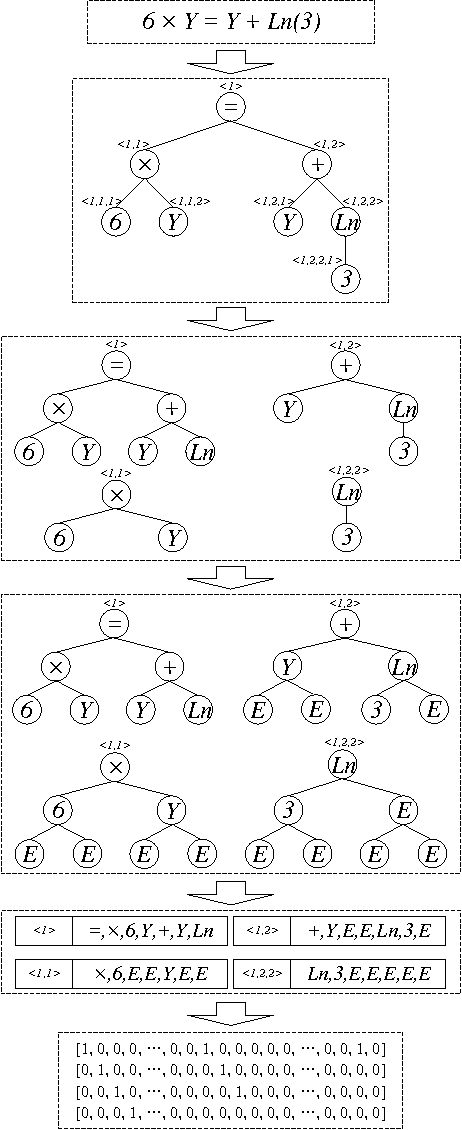
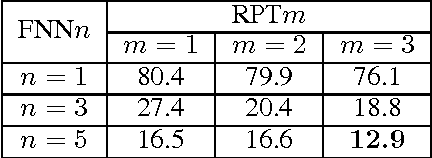
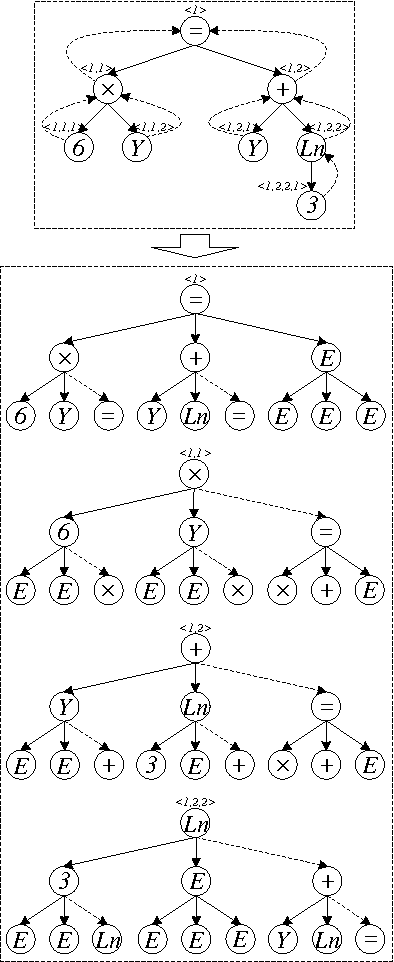
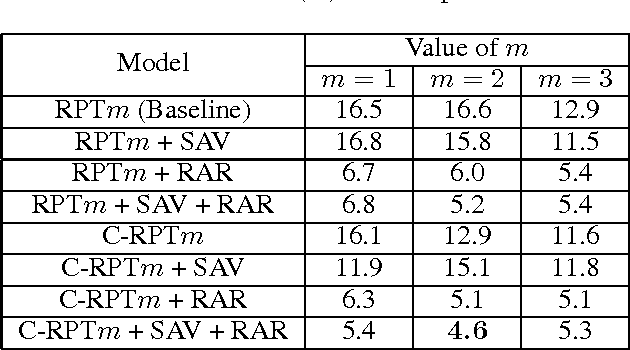
There is a wide gap between symbolic reasoning and deep learning. In this research, we explore the possibility of using deep learning to improve symbolic reasoning. Briefly, in a reasoning system, a deep feedforward neural network is used to guide rewriting processes after learning from algebraic reasoning examples produced by humans. To enable the neural network to recognise patterns of algebraic expressions with non-deterministic sizes, reduced partial trees are used to represent the expressions. Also, to represent both top-down and bottom-up information of the expressions, a centralisation technique is used to improve the reduced partial trees. Besides, symbolic association vectors and rule application records are used to improve the rewriting processes. Experimental results reveal that the algebraic reasoning examples can be accurately learnt only if the feedforward neural network has enough hidden layers. Also, the centralisation technique, the symbolic association vectors and the rule application records can reduce error rates of reasoning. In particular, the above approaches have led to 4.6% error rate of reasoning on a dataset of linear equations, differentials and integrals.