 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Alignment: A simple and effective proxy for model merging in computer vision
Apr 14, 2026Efficiently merging several models fine-tuned for different tasks, but stemming from the same pretrained base model, is of great practical interest. Despite extensive prior work, most evaluations of model merging in computer vision are restricted to image classification using CLIP, where different classification datasets define different tasks. In this work, our goal is to make model merging more practical and show its relevance on challenging scenarios beyond this specific setting. In most vision scenarios, different tasks rely on trainable and usually heterogeneous decoders. Differently from previous studies with frozen decoders, where merged models can be evaluated right away, the non-trivial cost of decoder training renders hyperparameter selection based on downstream performance impractical. To address this, we introduce the task alignment proxy, and show how it can be used to speed up hyperparameter selection by orders of magnitude while retaining performance. Equipped with the task alignment proxy, we extend the applicability of model merging to multi-task vision models beyond CLIP-based classification.
Weatherproofing Retrieval for Localization with Generative AI and Geometric Consistency
Feb 14, 2024



State-of-the-art visual localization approaches generally rely on a first image retrieval step whose role is crucial. Yet, retrieval often struggles when facing varying conditions, due to e.g. weather or time of day, with dramatic consequences on the visual localization accuracy. In this paper, we improve this retrieval step and tailor it to the final localization task. Among the several changes we advocate for, we propose to synthesize variants of the training set images, obtained from generative text-to-image models, in order to automatically expand the training set towards a number of nameable variations that particularly hurt visual localization. After expanding the training set, we propose a training approach that leverages the specificities and the underlying geometry of this mix of real and synthetic images. We experimentally show that those changes translate into large improvements for the most challenging visual localization datasets. Project page: https://europe.naverlabs.com/ret4loc
Key Protected Classification for Collaborative Learning
Aug 27, 2019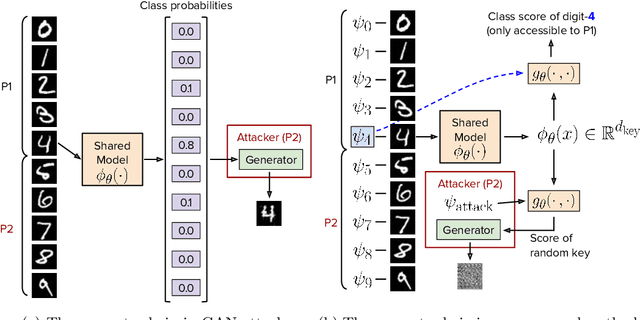
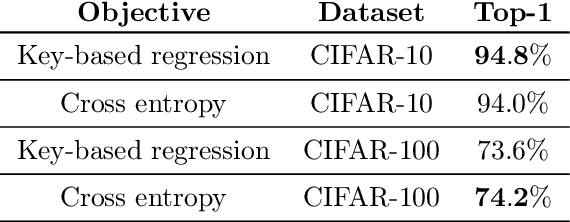
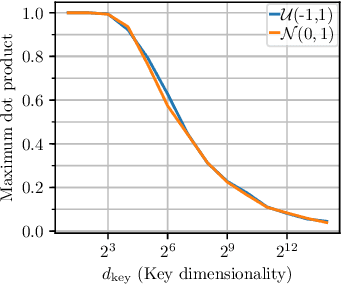
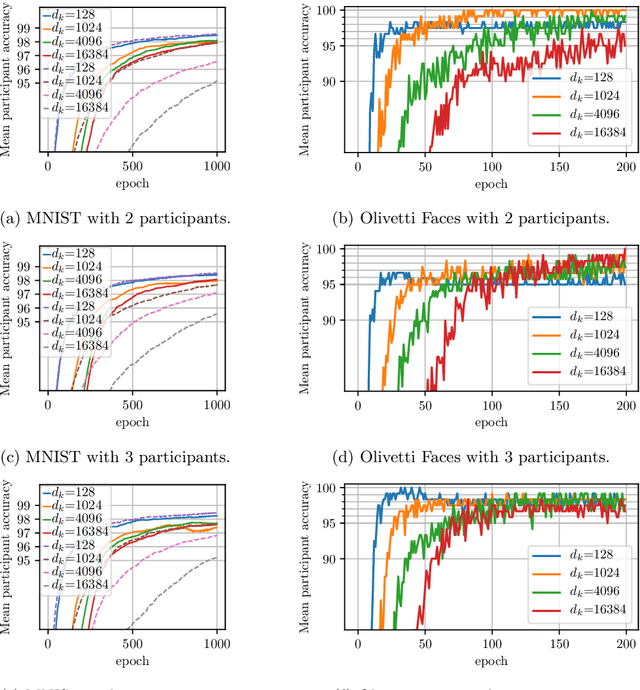
Large-scale datasets play a fundamental role in training deep learning models. However, dataset collection is difficult in domains that involve sensitive information. Collaborative learning techniques provide a privacy-preserving solution, by enabling training over a number of private datasets that are not shared by their owners. However, recently, it has been shown that the existing collaborative learning frameworks are vulnerable to an active adversary that runs a generative adversarial network (GAN) attack. In this work, we propose a novel classification model that is resilient against such attacks by design. More specifically, we introduce a key-based classification model and a principled training scheme that protects class scores by using class-specific private keys, which effectively hides the information necessary for a GAN attack. We additionally show how to utilize high dimensional keys to improve the robustness against attacks without increasing the model complexity. Our detailed experiments demonstrate the effectiveness of the proposed technique.