 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Soft Actor-Critic: Off-Policy Reinforcement Learning for Addressing Value Estimation Errors
Feb 23, 2020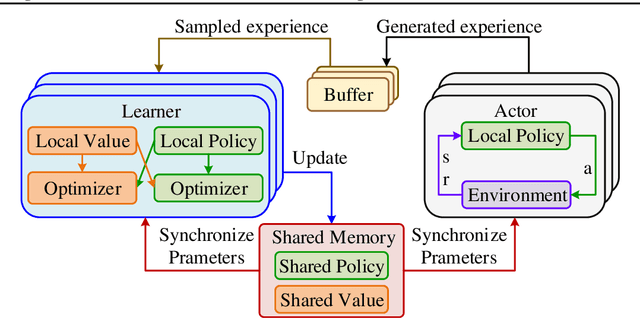

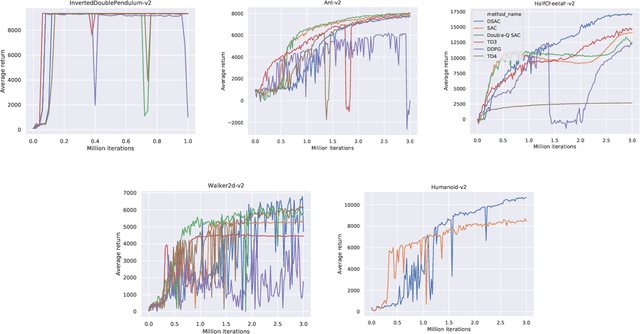

In current reinforcement learning (RL) methods, function approximation errors are known to lead to the overestimated or underestimated Q-value estimates, thus resulting in suboptimal policies. We show that the learning of a state-action return distribution function can be used to improve the Q-value estimation accuracy. We employ the return distribution function within the maximum entropy RL framework in order to develop what we call the Distributional Soft Actor-Critic (DSAC) algorithm, which is an off-policy method for continuous control setting. Unlike traditional distributional RL algorithms which typically only learn a discrete return distribution, DSAC directly learns a continuous return distribution by truncating the difference between the target and current distribution to prevent gradient explosion. Additionally, we propose a new Parallel Asynchronous Buffer-Actor-Learner architecture (PABAL) to improve the learning efficiency, which is a generalization of current high-throughput learning architectures. We evaluate our method on the suite of MuJoCo continuous control tasks, achieving state-of-the-art performance.
Improving Generalization of Reinforcement Learning with Minimax Distributional Soft Actor-Critic
Feb 13, 2020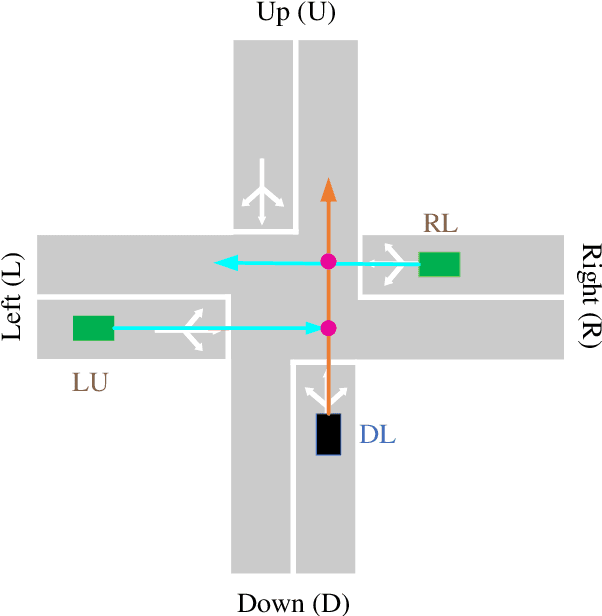
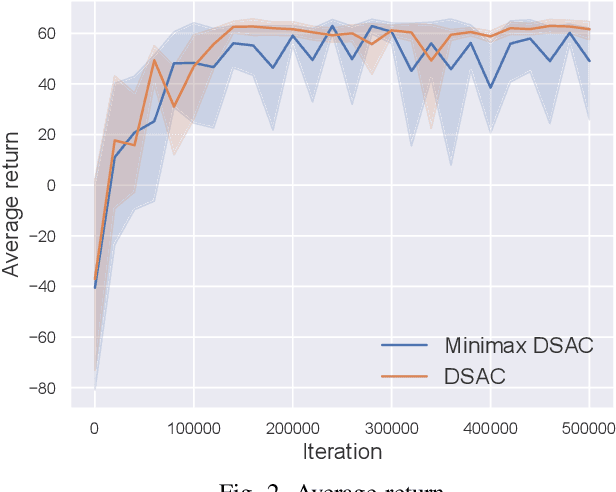
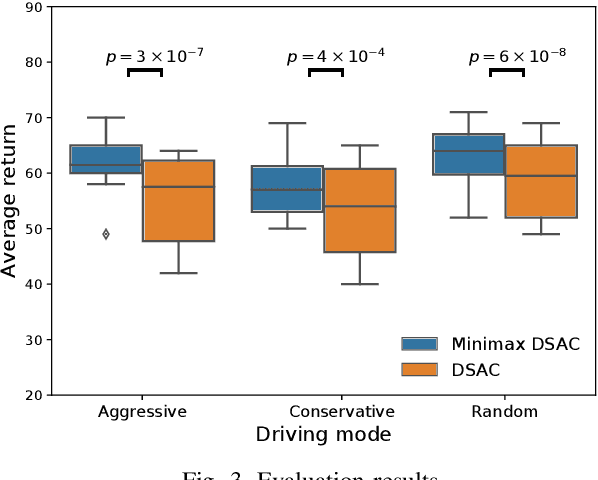
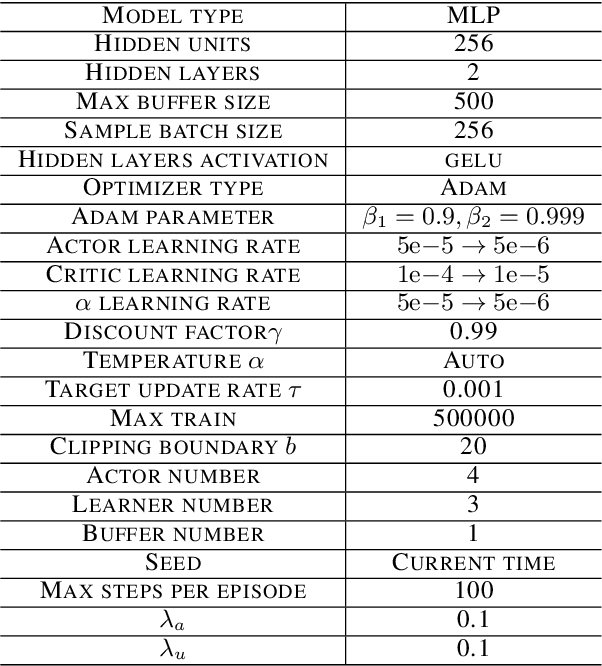
Reinforcement learning (RL) has achieved remarkable performance in a variety of sequential decision making and control tasks. However, a common problem is that learned nearly optimal policy always overfits to the training environment and may not be extended to situations never encountered during training. For practical applications, the randomness of the environment usually leads to rare but devastating events, which should be the focus of safety-critical systems, such as autonomous driving. In this paper, we introduce the minimax formulation and distributional framework to improve the generalization ability of RL algorithms and develop the Minimax Distributional Soft Actor-Critic (Minimax DSAC) algorithm. Minimax formulation aims to seek optimal policy considering the most serious disturbances from environment, in which the protagonist policy maximizes action-value function while the adversary policy tries to minimize it. Distributional framework aims to learn a state-action return distribution, from which we can model the risk of different returns explicitly, thus, formulating a risk-averse protagonist policy and a risk-seeking adversarial policy. We implement our method on the decision-making tasks of autonomous vehicles at intersections and test the trained policy in distinct environments from training environment. Results demonstrate that our method can greatly improve the generalization ability of the protagonist agent to different environmental variations.
Direct and indirect reinforcement learning
Dec 23, 2019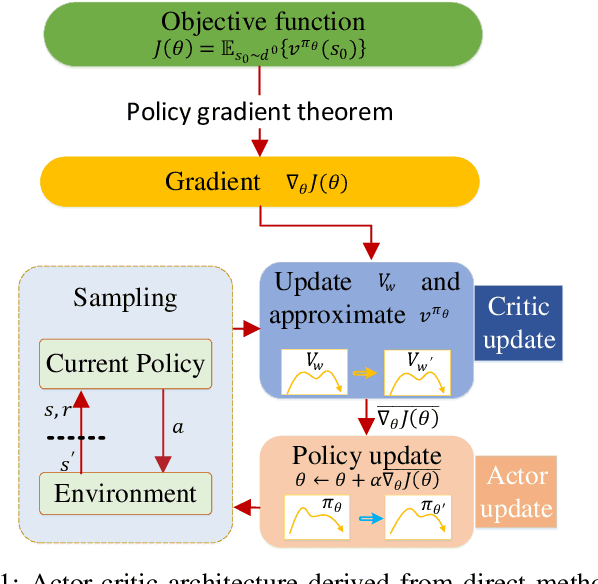
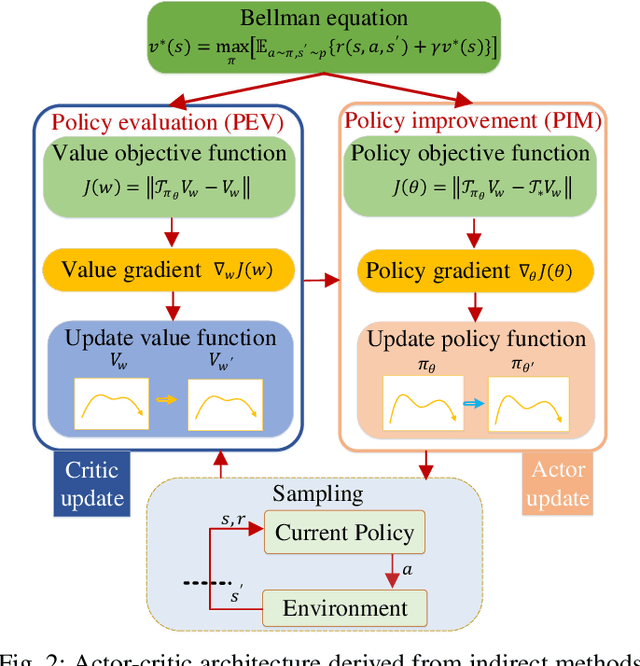
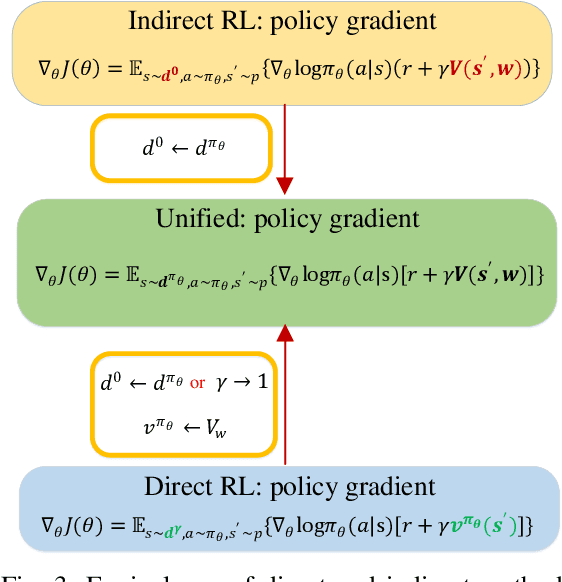

Reinforcement learning (RL) algorithms have been successfully applied to a range of challenging sequential decision making and control tasks. In this paper, we classify RL into direct and indirect methods according to how they seek optimal policy of the Markov Decision Process (MDP) problem. The former solves optimal policy by directly maximizing an objective function using gradient descent method, in which the objective function is usually the expectation of accumulative future rewards. The latter indirectly finds the optimal policy by solving the Bellman equation, which is the sufficient and necessary condition from Bellman's principle of optimality. We take vanilla policy gradient and approximate policy iteration to study their internal relationship, and reveal that both direct and indirect methods can be unified in actor-critic architecture and are equivalent if we always choose stationary state distribution of current policy as initial state distribution of MDP. Finally, we classify the current mainstream RL algorithms and compare the differences between other criteria including value-based and policy-based, model-based and model-free.
Centralized Conflict-free Cooperation for Connected and Automated Vehicles at Intersections by Proximal Policy Optimization
Dec 18, 2019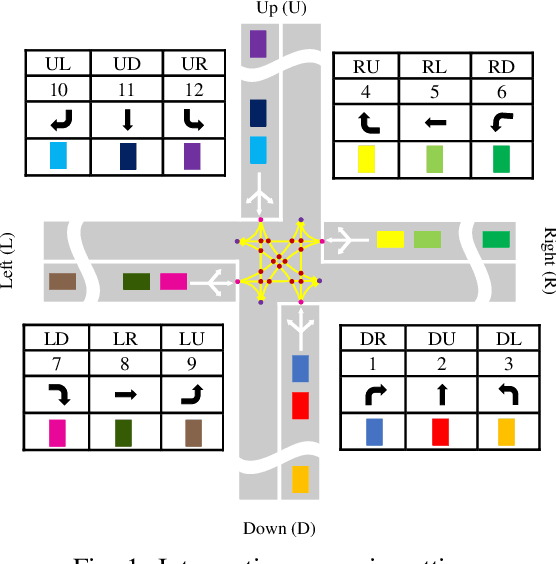
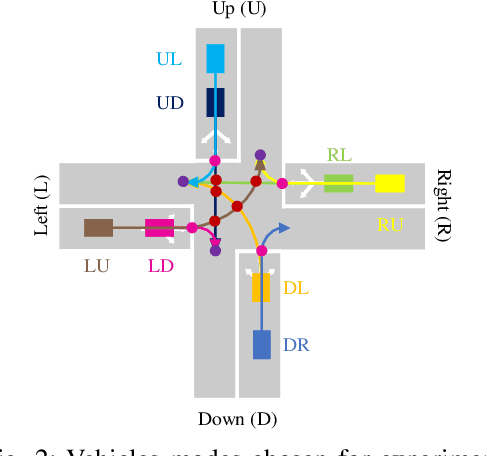
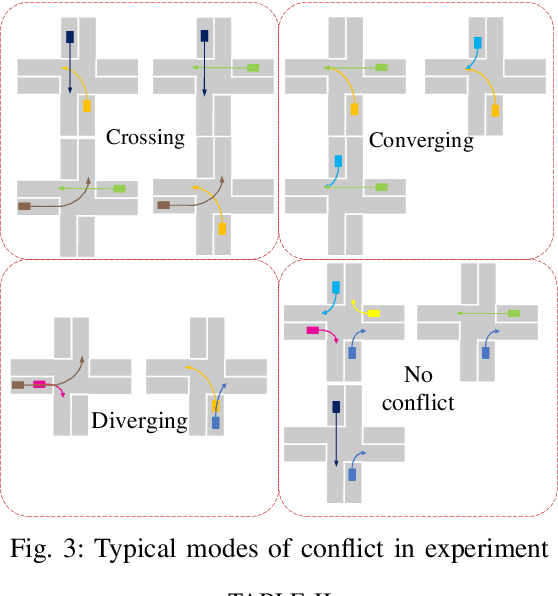
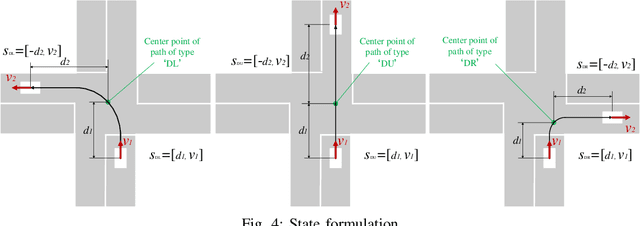
Connected vehicles will change the modes of future transportation management and organization, especially at intersections. There are mainly two categories coordination methods at unsignalized intersection, i.e. centralized and distributed methods. Centralized coordination methods need huge computation resources since they own a centralized controller to optimize the trajectories for all approaching vehicles, while in distributed methods each approaching vehicles owns an individual controller to optimize the trajectory considering the motion information and the conflict relationship with its neighboring vehicles, which avoids huge computation but needs sophisticated manual design. In this paper, we propose a centralized conflict-free cooperation method for multiple connected vehicles at unsignalized intersection using reinforcement learning (RL) to address computation burden naturally by training offline. We firstly incorporate a prior model into proximal policy optimization (PPO) algorithm to accelerate learning process. Then we present the design of state, action and reward to formulate centralized cooperation as RL problem. Finally, we train a coordinate policy by our model-accelerated PPO (MA-PPO) in a simulation setting and analyze results. Results show that the method we propose improves the traffic efficiency of the intersection on the premise of ensuring no collision.